
TensorFlow实现指数衰减学习率的方法

在TensorFlow中,tf.train.exponential_decay函数实现了指数衰减学习率,通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。
tf.train.exponential_decay(learning_rate, global_step, decay_steps, decay_rate, staircase, name)函数会指数级地减小学习率,它实现了以下代码的功能:
#tf.train.exponential_decay函数可以通过设置staircase参数选择不同的学习率衰减方式
#staircase参数为False(默认)时,选择连续衰减学习率:
decayed_learning_rate = learning_rate * math.pow(decay_rate, global_step / decay_steps)
#staircase参数为True时,选择阶梯状衰减学习率:
decayed_learning_rate = learning_rate * math.pow(decay_rate, global_step // decay_steps)
①decayed_leaming_rate为每一轮优化时使用的学习率;
②leaming_rate为事先设定的初始学习率;
③decay_rate为衰减系数;
④global_step为当前训练的轮数;
⑤decay_steps为衰减速度,通常代表了完整的使用一遍训练数据所需要的迭代轮数,这个迭代轮数也就是总训练样本数除以每一个batch中的训练样本数,比如训练数据集的大小为128,每一个batch中样例的个数为8,那么decay_steps就为16。
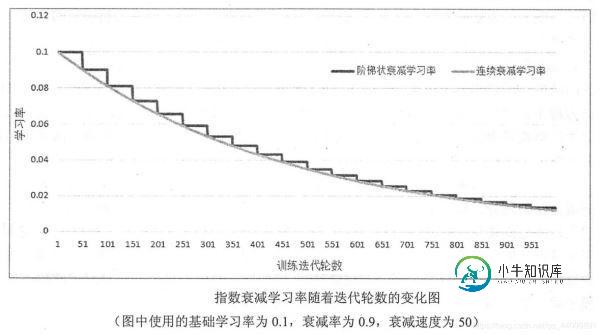
当staircase参数设置为True,使用阶梯状衰减学习率时,代码的含义是每完整地过完一遍训练数据即每训练decay_steps轮,学习率就减小一次,这可以使得训练数据集中的所有数据对模型训练有相等的作用;当staircase参数设置为False,使用连续的衰减学习率时,不同的训练数据有不同的学习率,而当学习率减小时,对应的训练数据对模型训练结果的影响也就小了。
接下来看一看tf.train.exponential_decay函数应用的两种形态(省略部分代码):
①第一种形态,global_step作为变量被优化,在这种形态下,global_step是变量,在minimize函数中传入global_step将自动更新global_step参数(global_step每轮迭代自动加一),从而使得学习率也得到相应更新:
import tensorflow as tf
.
.
.
#设置学习率
global_step = tf.Variable(tf.constant(0))
learning_rate = tf.train.exponential_decay(0.01, global_step, 16, 0.96, staircase=True)
#定义反向传播算法的优化方法
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy, global_step=global_step)
.
.
.
#创建会话
with tf.Session() as sess:
.
.
.
for i in range(STEPS):
.
.
.
#通过选取的样本训练神经网络并更新参数
sess.run(train_step, feed_dict={x:X[start:end], y_:Y[start:end]})
.
.
.
②第二种形态,global_step作为占位被feed,在这种形态下,global_step是占位,在调用sess.run(train_step)时使用当前迭代的轮数i进行feed:
import tensorflow as tf . . . #设置学习率 global_step = tf.placeholder(tf.float32, shape=()) learning_rate = tf.train.exponential_decay(0.01, global_step, 16, 0.96, staircase=True) #定义反向传播算法的优化方法 train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) . . . #创建会话 with tf.Session() as sess: . . . for i in range(STEPS): . . . #通过选取的样本训练神经网络并更新参数 sess.run(train_step, feed_dict={x:X[start:end], y_:Y[start:end], global_step:i}) . . .
总结
以上所述是小编给大家介绍的TensorFlow实现指数衰减学习率的方法,希望对大家有所帮助!
-
我正在尝试使用Tiny YOLO v2的代码库。我在声明学习率计划时遇到以下错误。我可以看到我的值与我的值大小相同,但我不确定什么是好的修复方法。我已经包括了明确声明值的尝试(使用
-
TensorFlow 是一种表示计算的方式,直到请求时才实际执行。 从这个意义上讲,它是一种延迟计算形式,它能够极大改善代码的运行。 翻译自:https://learningtensorflow.com/
-
2006 年,Geoffrey Hinton等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。
-
上一节中我们观察了过拟合现象,即模型的训练误差远小于它在测试集上的误差。虽然增大训练数据集可能会减轻过拟合,但是获取额外的训练数据往往代价高昂。本节介绍应对过拟合问题的常用方法:权重衰减(weight decay)。 方法 权重衰减等价于$L_2$范数正则化(regularization)。正则化通过为模型损失函数添加惩罚项使学出的模型参数值较小,是应对过拟合的常用手段。我们先描述$L_2$范数正
-
本文向大家介绍详解tensorflow实现迁移学习实例,包括了详解tensorflow实现迁移学习实例的使用技巧和注意事项,需要的朋友参考一下 本文主要是总结利用tensorflow实现迁移学习的基本步骤。 所谓迁移学习,就是将上一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。比如说,我们可以保留训练好的Inception-v3模型中所有的参数,只替换最后一层全连接层。在最后一层全连接
-
问题内容: 我想知道是否有一种方法可以对Caffe中的不同层使用不同的学习率。我正在尝试修改预训练的模型,并将其用于其他任务。我想要的是加快对新添加的层的培训,并使受过培训的层保持较低的学习率,以防止它们变形。例如,我有一个5转换层的预训练模型。现在,我添加一个新的转换层并对其进行微调。前5层的学习率为0.00001,后5层的学习率为0.001。任何想法如何实现这一目标? 问题答案: 使用2个优化