《数据分析科学实习》专题
-
Java 1.5:数学公式解析器
问题内容: 您好,我经常开发JTableModels,其中某些单元格必须包含将某个简单数学公式加总的结果。该公式可以具有: 运算符(+,-,*,/) 数字常数 其他单元格引用(包含数字) 参数(引用名称如“ INTEREST_RATE”的数字) 我经常通过制作一个小的计算器类来解决该问题,该类可以解析公式,定义的语法。计算器类使用堆栈进行计算,语法始终使用波兰语表示法。 但是波兰语对我和我的用户来
-
 华润数科java后端实习
华润数科java后端实习1介绍两个项目 2熟悉的两个比较熟悉的技术栈 3用过redis的哪些功能? 4:数据库中的数据和缓存中的数据不一致,怎么解决? 5 redis中的持久化有哪些 6 aof文件太大,会启动重写机制,了解重写做了什么吗? 7 redis中的过期键的删除策略 8:reids用过哨兵,集群吗? 9:用过redis的分布式锁吗? 10 redis中的goodsip协议? 11 redis6.0是什么线程的?
-
python实现的分析并统计nginx日志数据功能示例
本文向大家介绍python实现的分析并统计nginx日志数据功能示例,包括了python实现的分析并统计nginx日志数据功能示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python实现的分析并统计nginx日志数据功能。分享给大家供大家参考,具体如下: 利用python脚本分析nginx日志内容,默认统计ip、访问url、状态,可以通过修改脚本统计分析其他字段。 一、脚本运行方式
-
如何抑制Python中的科学计数法?
问题内容: 这是我的代码: 我的商显示为 有什么方法可以压制科学记数法并使其显示为 ?我将使用结果作为字符串。 问题答案: 但是你需要自己管理精度。例如,
-
抑制大熊猫的科学计数法吗?
问题内容: 我在熊猫中有一个DataFrame,其中一些数字用科学计数法(或指数计数法)表示,如下所示: 科学的表示法使应该进行轻松的比较成为不必要的困难。我认为正是21900的价值将其推向了其他水平。我的意思是1.0被编码。一! 这不起作用: 而且也没有实现抑制,而且我已经绝望了,只能为所有其他float值打开它,而无法关闭它。 问题答案: 您的数据可能是dtype。这是数据的直接复制/粘贴。将
-
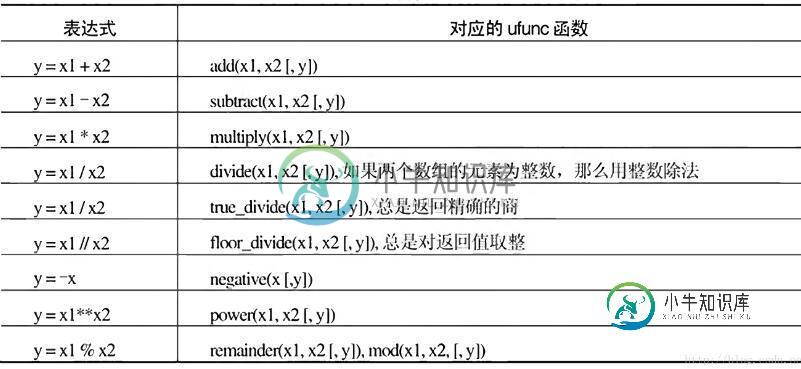 python科学计算之numpy——ufunc函数用法
python科学计算之numpy——ufunc函数用法本文向大家介绍python科学计算之numpy——ufunc函数用法,包括了python科学计算之numpy——ufunc函数用法的使用技巧和注意事项,需要的朋友参考一下 写在前面 ufunc是universal function的缩写,意思是这些函数能够作用于narray对象的每一个元素上,而不是针对narray对象操作,numpy提供了大量的ufunc的函数。这些函数在对narray进行运算的
-
不带科学计数法显示浮点值
问题内容: 当我在PHP中进行以下乘法时: 我得到结果:1.0E-9 我想将此结果转换为普通的十进制表示法,我该怎么做? 不起作用,它返回。溢出? 问题答案: 不起作用,它返回。溢出? 可以,但是您在这里错过了一点。 没有溢出。只是对于修饰符,默认情况下使用6位数字。另外,请注意区域设置,可能更适合。 您可能希望使用更多数字,例如说4000000(400万): 如该示例所示,不仅有一个公共值(6位
-
python数据分析:关键字提取方式
本文向大家介绍python数据分析:关键字提取方式,包括了python数据分析:关键字提取方式的使用技巧和注意事项,需要的朋友参考一下 TF-IDF TF-IDF(Term Frequencey-Inverse Document Frequency)指词频-逆文档频率,它属于数值统计的范畴。使用TF-IDF,我们能够学习一个词对于数据集中的一个文档的重要性。 TF-IDF的概念 TF-IDF有两部
-
Regex用于分析数据库列,如JDBC ResultSet
我正在使用JDBC从查询结果中获取列。 例如: 我想在运行查询之前解析它们。本质上,我希望为列标签创建一个数组,该数组将与resultSet所期望的值相匹配。get**方法。出于说明的目的,我想用这个替换上面的循环,并得到相同的结果: 这看起来很简单。我可以用一个简单的正则表达式解析我的语句,该正则表达式接受SELECT和from之间的字符串,使用列分隔符创建组,并从组中构建arrayOf列。但是
-
如何进行探索性数据分析(EDA)?
本文向大家介绍如何进行探索性数据分析(EDA)?相关面试题,主要包含被问及如何进行探索性数据分析(EDA)?时的应答技巧和注意事项,需要的朋友参考一下 EDA的目的是去挖掘数据的一些重要信息。一般情况下会从粗到细的方式进行EDA探索。一开始我们可以去探索一些全局性的信息。观察一些不平衡的数据,计算一下各个类的方差和均值。看一下前几行数据的信息,包含什么特征等信息。使用Pandas中的df.info
-
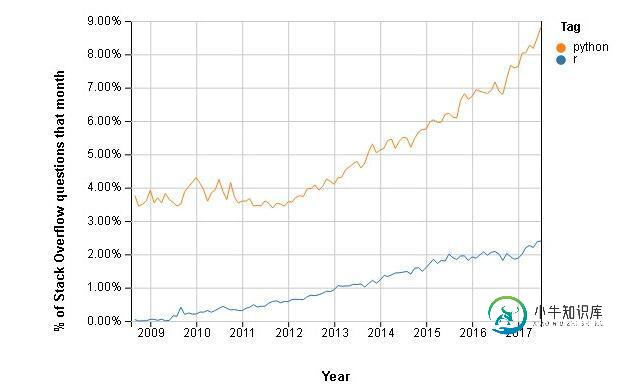 R vs. Python 数据分析中谁与争锋?
R vs. Python 数据分析中谁与争锋?本文向大家介绍R vs. Python 数据分析中谁与争锋?,包括了R vs. Python 数据分析中谁与争锋?的使用技巧和注意事项,需要的朋友参考一下 当我们想要选择一种编程语言进行数据分析时,相信大多数人都会想到R和Python——但是从这两个非常强大、灵活的数据分析语言中二选一是非常困难的。 我承认我还没能从这两个数据科学家喜爱的语言中选出更好的那一个。因此,为了使事情变得有趣,本文将介绍
-
Spring对不同数据的批处理分析
我有一个场景,文件有不同的类型。文件分为页眉、正文和页脚三部分。标题可以是2类型dipend,根据标题大小,我需要使用标记器和范围来解析内容。 页脚也一样,这取决于正文大小和页脚长度,需要解析页脚内容。 我查看了PatternMatchingCompositeLineMapper和fixedlenghttokenizer,但没有找到为范围指定条件的方法,也没有找到在页脚中共享正文内容以检查长度的方
-
深入分析Mongodb数据的导入导出
本文向大家介绍深入分析Mongodb数据的导入导出,包括了深入分析Mongodb数据的导入导出的使用技巧和注意事项,需要的朋友参考一下 一、Mongodb导出工具mongoexport Mongodb中的mongoexport工具可以把一个collection导出成JSON格式或CSV格式的文件。可以通过参数指定导出的数据项,也可以根据指定的条件导出数据。 mongoexport具体用法 参数说明
-
 顺丰-大数据挖掘与分析面经
顺丰-大数据挖掘与分析面经顺丰-大数据挖掘与分析(2021秋招) 顺丰一面: 1.深挖实习,指标体系如何建立,各项指标的权重如何确定 2.逻辑回归算法的原理 3.谈谈对ABtest的认识 4.sql排序窗口函数的区别 顺丰二面: 1.深挖实习,预测为什么选用随机森林算法,如何调参 2.论文项目,简单介绍 3.了解哪些机器学习算法 4.反问 顺丰hr面 1.实习中遇到的困难,如何解决 2.过往经历中,你认为最困难的问题,你是
-
 字节电商数据分析——一面凉经
字节电商数据分析——一面凉经今天面了电商数据分析一面,来写写面经,感觉问的问题倒是不难可惜自己没准备好,还是蛮可惜的,emo中~ 面试下午五点开始,面试官胖胖的很可爱,像我的博士学长哈哈~但是还是很紧张,可能是第一次面大厂 SQL题: 1:dense_rank(),rank()和row_number()三个函数的区别 2:用户登录日期的最大间隔是多少 这个我当时有点慌,采用了计算用户连续登录天数的做法,当时也想到了用