《大厂实习》专题
-
Spring 3.1 + Hibernate 4.1 JPA,实体管理器工厂已注册两次
问题内容: 我使用带有Hibernate 4.1的Spring Framework 3.1作为JPA提供程序,并且具有完整的功能设置,但是每次启动Web应用程序时,我都会看到以下警告消息: 该应用程序正常运行,但是像这样的警告消息困扰着我,数小时的搜索,调整和试验使我无所适从。我试过更改工厂名称并添加和省略配置块,但无济于事。看来,Spring或Hibernate中的某些东西只是两次初始化了实体管
-
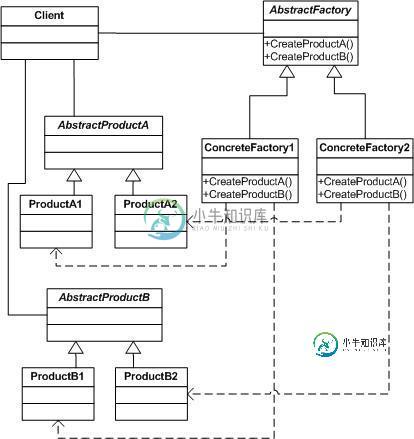 PHP实现设计模式中的抽象工厂模式详解
PHP实现设计模式中的抽象工厂模式详解本文向大家介绍PHP实现设计模式中的抽象工厂模式详解,包括了PHP实现设计模式中的抽象工厂模式详解的使用技巧和注意事项,需要的朋友参考一下 抽象工厂模式(Abstact Factory)是一种常见的软件设计模式。该模式为一个产品族提供了统一的创建接口。当需要这个产品族的某一系列的时候,可以为此系列的产品族创建一个 具体的工厂类。 【意图】 抽象工厂模式提供一个创建一系统相关或相互依赖对象的接口,而
-
Angular最佳实践:在工厂还是在控制器中承诺?
问题内容: 我的应用程序中有一个基本工厂,可以处理API调用。目前,我正在使用以下形式: 在我的控制器中,我正在像这样处理诺言: 看来我可以将promise处理移至Factory,而不是在控制器中执行,但是我不确定这是否会带来比小型控制器更多的好处。 有人可以解释有关此模式的最佳做法吗? 问题答案: 最终由您自己决定要向服务调用者提供多少数据。如果需要,您可以肯定地将HTTP响应对象返回给调用者,
-
如何在java中创建抽象工厂来实例化对象
我想创建一个抽象工厂。这是我试过的。 //抽象类工作者 //扩展工人的电工班 //梅森班 //接口可操作性StractFactory // //应用程序类 你认为它能像那样工作吗?现在,如果我真的想要一个具体的物体,怎么能做到呢?因为我想写一个根据类型计算每个工人工资的方法,例如,我如何在方法中使用我的抽象工厂来返回每个类型。
-
 字节大数据开发实习一二HR面
字节大数据开发实习一二HR面5/5一面 5/14 二面 5/18 hr面 5/19 OC 一面(1h10min) 1.自我介绍一下 2.介绍一下你的项目 2.1 Mysql全量数据规模 2.2 既然Mysql能存储,为什么要导入到hive中 3.说一下MySQL的ACID特性 4.脏读和幻读分别是什么含义 5.spark持久化的级别和作用 6.spark任务出现数据倾斜有哪些方法解决 7.hive没办法创建分区怎么理
-
 网易大数据开发日常实习 已oc
网易大数据开发日常实习 已oc部门:网易云 8.23约面,8.25 一面 8.29 二面。8.30 hr面 一面: 45min左右 1.自我介绍 2.说说项目用到了哪些技术 3.你刚刚说到了即席查询,项目里是怎么做的。 4.四道sql,十分钟后对答案 5.笛卡尔积了解吗。 6.笛卡尔积会产生什么问题。 7.你刚刚说到了数据倾斜。介绍一下。 8.笛卡尔积就会产生数据倾斜吗 9.mr流程介绍一下 10.你多久能来实习 11.你刚刚
-
 ACCESS大数据开发实习一面凉经(20min)
ACCESS大数据开发实习一面凉经(20min)自我介绍 问对hadoop各个组件的了解 解释下mapreduce的过程 问有没看过谷歌的GFS论文 问项目里数据库咋建模设计的 对维度建模的了解 对数仓的了解,数仓一般咋分层 GGGG,这之前只关注框架底层了,,没看过数仓的东西#大数据开发面经##实习生[话题]##access#
-
 百度/滴滴后端/大数据实习面经
百度/滴滴后端/大数据实习面经返校前最后篇面经 这两次面试官感觉都挺满意的,,估计能有offer了 百度大数据研发一面(就一面) 2.22 自我介绍 项目 1.爬虫和识别匹配的细节 2.爬虫异常情况 3.内部表外部表区别 4.数据量大小 5.推荐KNN模型距离的细节 技术 6.mapreduce计算过程 7.shuffle细节 8.数据倾斜原因和处理方式 我举了两种 mapjoin 加盐 9.hive窗
-
 欢聚 大数据开发实习 面经(已offer)
欢聚 大数据开发实习 面经(已offer)首先做了三道SQL题,主要涉及分组聚合、窗口函数。 3.3 一面 28min: 1.自我介绍 2.为什么要做这个项目 3.介绍DataX 4.项目问题 5.介绍HDFS 6.Hadoop hive hdfs spark关系 7.职业规划 8.数仓分层 9.窗口函数 3.6 二面 45min: 1.自我介绍 2.项目介绍 3.维度模型 4.一道数仓场景题 5.数仓分层 6.SQL常用函数 7.ran
-
 美团 大数据开发 暑期实习 一面
美团 大数据开发 暑期实习 一面时长:1h 由于问题太多,分四类进行整理 0. 实习相关:之前有数据开发的实习经验,就问了之前工作有没有spark或者hivesql优化的经验;如何确保数据的有效性;实习公司数据存储格式(Parquet),还知道哪些数据存储格式 1. 大数据相关问题:为什么Spark比MR快;对Spark的了解;两个表join的优化方法(大小表join可以map-side join, join前过滤null值);
-
 (暑期实习)携程大数据一面、二面
(暑期实习)携程大数据一面、二面个人情况简述:本硕双非,acm银牌 测评答的个人感觉不错,笔试AK 测评隔天笔试(第一批),之后就跟大部队流程差不多约了一、二面 一面(总时长50分钟),二面(总时长40分钟) 纯业务理解,深挖实习经历和项目经历 提出的问题多为数仓设计问题和开放性问题,基本都是大量的对话和交流,因为很多想法是结合项目经验的临场idea,个人没有记录 携程给我的感觉就是,如果你做过很多项目,阅读过大量相关设计的学习
-
 美团暑期实习-大数据开发一面
美团暑期实习-大数据开发一面#暑期# #投递实习岗位前的准备# 3月23日--分享个经验,求个好运 时长一个小时二十分钟 自我介绍 因为学统计的,问了中心极限定理和大数据定律 机器学习-XGBoost算法简介 两道智力题:逻辑判断谁说谎了和分金条 问了为什么研究生跨专业保研了? Hive和MySQL区别 数据库的索引有什么用 说一下索引的类型,还有B+树索引 数据仓库和关系型数据库区别 Hadoop生态圈简介 问我SQL写的
-
 比特大陆嵌入式软件实习面经
比特大陆嵌入式软件实习面经自我介绍 介绍项目 shell命令怎么调试 shell怎么获得上一条命令执行结果 shell命令怎么在后台执行 说说Linux多线程编程 说说Linux网络编程过程 手撕代码:反转链表 ps:寄了,太多东西不记得了 #我的实习日记#
-
 阿里大淘宝暑期实习前端一面
阿里大淘宝暑期实习前端一面#我的实习求职记录# 4.26 四道笔试: (1)写一个toast组件 (2)复杂嵌套对象根据id访问相应值 (3)数组去重的方法 (4)promise.all 1、position有那些值 2、除了settimeout还有那些定时器 3、settimeout怎么模拟setInterval 4、复杂对象嵌套你的写法,问题是什么 5、数组去重 set和filter有什么区别吗 6、promise.a
-
 阿里 大淘宝 产品暑期实习 二面
阿里 大淘宝 产品暑期实习 二面二面已经是交叉面了,面试官问的问题也都是跟部门业务比较相关的,会比较关心对于数据的抽象能力和归纳总结能力。大哥人很好很nice,后面讲解了很久他们部门的业务和对于实习生的一些期待 1. 简单自我介绍 2. 在科研和实习中是不是有一些可以通过数据分析解决问题的case分享 a. 介绍了xx实习期间的xx项目(toB) i. 追问如何熟悉了解工作中涉及到的系统的,有没有什么有趣的发现,或者通过数据找到