《大厂实习》专题
-
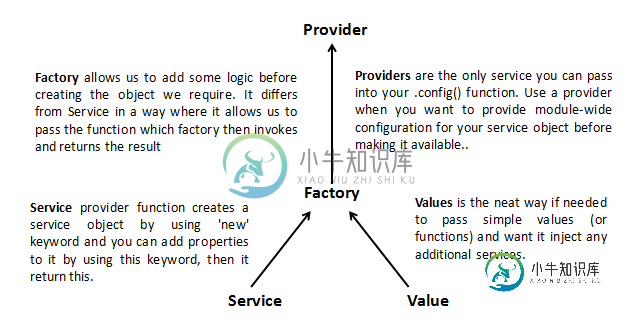 AngularJS:工厂和服务?
AngularJS:工厂和服务?问题内容: 编辑2016年1月: 由于这仍然引起注意。自问了这个之后,我已经完成了一些AngularJS项目,对于我最常使用的那些项目,建立了一个对象并最后返回了该对象。但是,我下面的说法仍然正确。 编辑: 我想我终于了解了两者之间的主要区别,并且我有一个代码示例来演示。我也认为这个问题与建议的重复问题有所不同。重复项说明该服务不可实例化,但是如果您按照我在下面的演示中进行设置,它实际上是可实例化
-
抽象工厂模式
抽象工厂模式 亦称: Abstract Factory 意图 抽象工厂模式是一种创建型设计模式, 它能创建一系列相关的对象, 而无需指定其具体类。 问题 假设你正在开发一款家具商店模拟器。 你的代码中包括一些类, 用于表示: 1、一系列相关产品, 例如 椅子Chair 、 沙发Sofa和 咖啡桌CoffeeTable 。 2、系列产品的不同变体。 例如, 你可以使用 现代Modern 、
-
工厂方法模式
亦称: 虚拟构造函数、Virtual Constructor、Factory Method 意图 工厂方法模式是一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。 问题 假设你正在开发一款物流管理应用。 最初版本只能处理卡车运输, 因此大部分代码都在位于名为 卡车的类中。 一段时间后, 这款应用变得极受欢迎。 你每天都能收到十几次来自海运公司的请求, 希望应用
-
抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。 介绍 意图:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。 主要
-
第六章:类工厂
类与继承在javascript的出现,说明javascript已经达到大规模开发的门槛了,在之前是ECMAScript4,就试图引入类,模块等东西,但由于过分引入太多的特性,搞得javascript乌烟瘴气,导致被否决。不过只是把类延时到ES6.到目前为止,javascript还没有正真意义上的类。不过我们可以模拟类,曾近一段时间,类工厂是框架的标配,本章会介绍各种类实现,方便大家在自己的框架中或
-
工厂方法模式
工厂方法模式是一种实现了「工厂」概念的面向对象设计模式。就像其他创建型模式一样,它也是处理在不指定对象具体类型的情况下创建对象的问题。工厂方法模式的实质是「定义一个创建对象的接口,但让实现这个接口的类来决定实例化哪个类。工厂方法让类的实例化推迟到子类中进行。」 var Humanity = (function() { function Man() { this.introduce = fu
-
工厂方法模式
问题 直到开始运行你才知道需要的是什么种类的对象。 解决方案 使用 工厂方法(Factory Method) 模式和选择对象都是动态生成的。 你需要将一个文件加载到编辑器,但是直到用户选择文件时你才知道它的格式。一个类使用工厂方法 ( Factory Method ) 模式可以根据文件的扩展名提供不同的解析器。 class HTMLParser constructor: ->
-
抽象工厂模式
简介 抽象工厂模式是一种软件开发设计模式。抽象工厂模式提供了一种方式,可以将一组具有同一主题的单独的工厂封装起来。在正常使用中,客户端程序需要创建抽象工厂的具体实现,然后使用抽象工厂作为接口来创建这一主题的具体对象。客户端程序不需要知道(或关心)它从这些内部的工厂方法中获得对象的具体类型,因为客户端程序仅使用这些对象的通用接口。抽象工厂模式将一组对象的实现细节与他们的一般使用分离开来。 简例 有个
-
工厂方法模式
简介 “工厂方法模式(Factory Method Pattern)又称为工厂模式,也叫虚拟构造器(Virtual Constructor)模式或者多态工厂(Polymorphic Factory)模式,它属于类创建型模式。在工厂方法模式中,工厂父类负责定义创建产品对象的公共接口,而工厂子类则负责生成具体的产品对象,这样做的目的是将产品类的实例化操作延迟到工厂子类中完成,即通过工厂子类来确定究竟应
-
简单工厂模式
活字印刷 面向对象 话说三国时期,曹操带领百万大军攻打东吴,大军在长江赤壁驻扎,军船连成一片,眼看就要灭掉东吴,统一天下,曹操大悦,于是大宴众文武,在酒席间,曹操诗兴大发,不觉吟道:喝酒唱歌,人生真爽。众文武齐呼:“丞相好诗!于是一臣子速命印刷工匠刻板印刷,以便流传天下。” 样张出来给曹操一看,曹操感觉不妥,说到:“喝与唱,此话过俗,应该为‘对酒当歌’较好!”,于是此臣就命工匠重新来过。工匠眼看连
-
工厂模式( Factory Pattern)
工厂模式是Java中最常用的设计模式之一。 这种类型的设计模式属于创建模式,因为此模式提供了创建对象的最佳方法之一。 在Factory模式中,我们创建对象而不将创建逻辑暴露给客户端,并使用公共接口引用新创建的对象。 实现 (Implementation) 我们将创建一个Shape接口和实现Shape接口的具体类。 工厂类ShapeFactory被定义为下一步。 FactoryPatternDemo
-
抽象工厂(Abstract Factory)
抽象工厂模式也称为工厂工厂。 此设计模式属于创建设计模式类别。 它提供了创建对象的最佳方法之一。 它包括一个接口,负责创建与Factory相关的对象。 如何实现抽象工厂模式? 以下程序有助于实现抽象工厂模式。 class Window: __toolkit = "" __purpose = "" def __init__(self, toolkit, purpose):
-
数据库工厂类
数据库工厂类提供了一些方法来帮助你管理你的数据库。 Table of Contents 数据库工厂类 初始化数据库工厂类 创建和删除数据库 创建和删除数据表 添加字段 添加键 创建表 删除表 重命名表 修改表 给表添加列 从表中删除列 修改表中的某个列 类参考 初始化数据库工厂类 重要 由于数据库工厂类依赖于数据库驱动器,为了初始化该类,你的数据库驱动器必须已经运行。 加载数据库工厂类的代码如下:
-
抽象工厂模式
抽象工厂模式(Abstract Factory Pattern)是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。 在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。 介绍 意图:提供一个创建一系列相关或相互依赖对象的接口,而无需指定它们具体的类。 主要
-
Hibernate 的会话工厂
1. 前言 Hibernate 的核心价值观是:开发者们!做你们应该做的。脏的、累的、没技术含义的由本尊来做。 本节课和大家一起好好的聊聊 Hibernate 的核心组件之一:会话工厂(SessionFactory)。 通过本节课,你将学习到: 会话工厂的设计要求; 会话工厂的核心功能。 2. 会话工厂的作用 原生 Jdbc 开发如同自己炒菜做饭,需经手买菜、洗菜、做菜……一系列过程。 基于 Hi