《欢聚时代实习》专题
-
 宁德时代面经
宁德时代面经算法岗,面试,全程15min,这还是我觉得太短了故意多问了几个问题,面试官迟到五分钟,上来自我介绍1分半,然后问我介绍一下项目经历,遇到什么苦难,如何解决,这是老一套问题了,我就中规中矩答了,3min,他不追问任何问题,直接说他的理解,一句话给我概括了,问我对不对,我说差不多,然后问我第二个项目,类似,用时2min,然后问我为啥选择宁德时代,我说了行业,公司地位之类的,然后说了一下我和算法岗的匹配
-
在聚合时将字符串转换为浮点数?
问题内容: 指定直方图聚合时,是否可以将字符串转换为浮点数?因为我的文档中的字段是浮点型的,但没有通过Elasticsearch解析,因此当我尝试使用字符串字段求和时,它将引发下一个错误。 我知道我可以更改映射,但是对于我有的用例,如果在编写字段的聚合时可以指定类似“ script:_value.tofloat()”的内容,则将更加方便。 这是我的代码: } 问题答案: 你需要这个 对于称为的字段
-
 TextInputLayout:未聚焦时提示标签的不同颜色
TextInputLayout:未聚焦时提示标签的不同颜色null
-
AngularJS-单击复选框时使输入元素聚焦
问题内容: 单击复选框时,是否有一种更干净的方法将焦点委派给元素。这是我入侵的肮脏版本: 的HTML 的JavaScript JSFiddle:http : //jsfiddle.net/U4jvE/8/ 问题答案: 这个怎么样 ?矮人 @asgoth和@Mark Rajcok是正确的。我们应该使用指令。我只是懒惰。 这是指令版本。plunker我觉得一个好的理由将其作为指令是可以重用这件事。 因
-
在SQL中通过日期和时间执行聚合
问题内容: 我有一个数据集,其中包含对频率为2分钟的几周的观察。我想将时间间隔从2分钟增加到5分钟。问题在于,观察的频率并不总是相同的。我的意思是,从理论上讲,每10分钟应进行5次观察,但通常情况并非如此。请让我知道如何根据平均功能以及观察的时间和日期汇总观察。换句话说,基于每5分钟的汇总,而对于每5分钟的时间间隔,观察次数却不同。此外,我有时间戳格式的日期和时间。 示例数据: 预期成绩: 问题答
-
如何在jprofiler调用树中聚合方法时间
我试图从根本上解决java中的性能问题。我使用jprofiler获得了采样配置文件。我可以看到许多不同的URI在根上具有相同的方法调用(xss2csv) 例如 用户1文件1 某物 xss2csv User2File2 某物 xss2csv 我想找出xss2csv方法花费的总时间百分比。单个调用显示140(所有状态),但热点视图显示此方法的0。请告知。 如果需要更多信息,请告诉我。
-
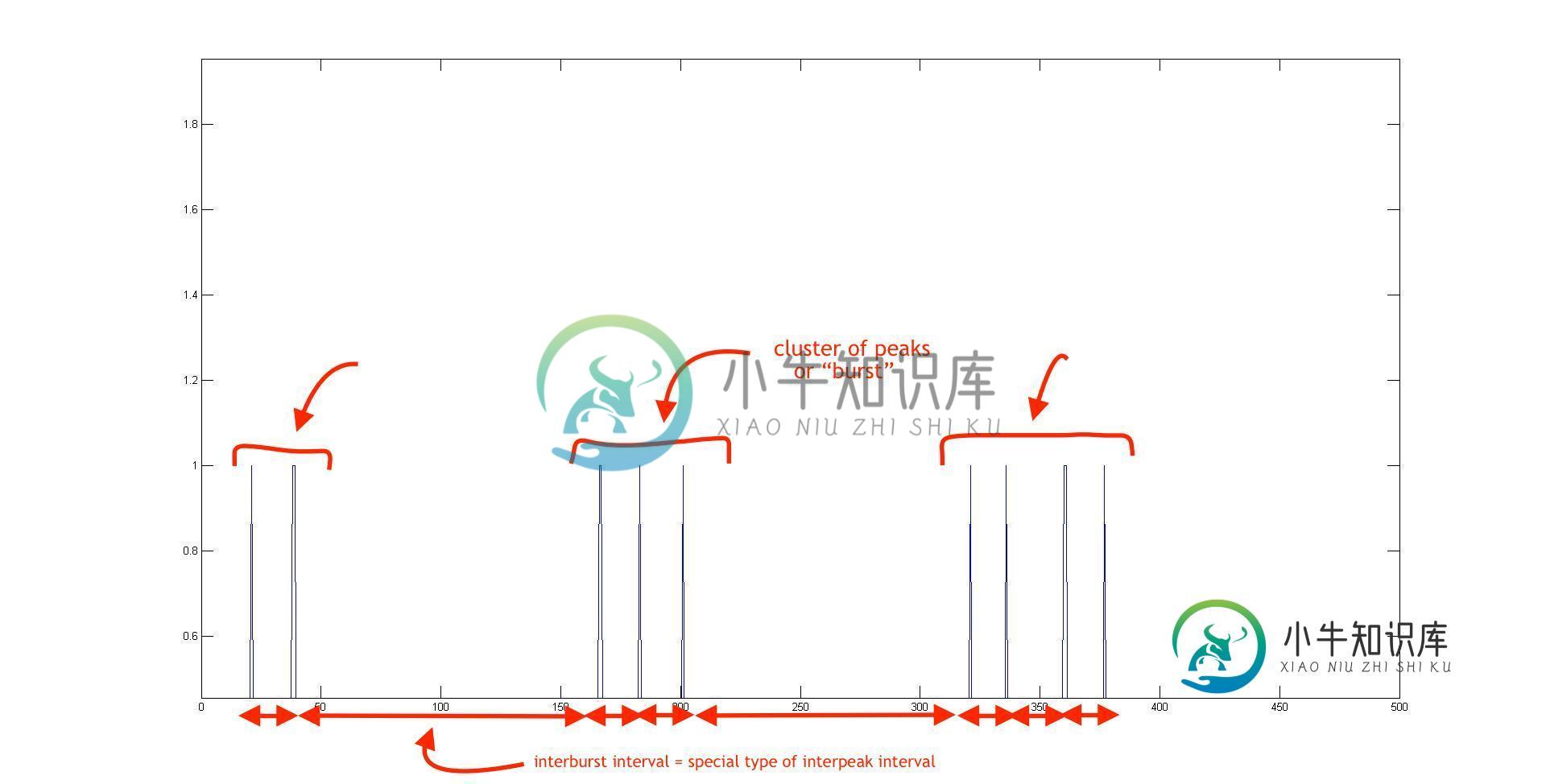 时间序列信号峰值聚类检测算法
时间序列信号峰值聚类检测算法我有一个带有开/关数据的二进制时间序列数据集。on通常是短暂的,因此看起来像一个峰值。这就是它的样子。 我已经检测到了峰值,并提取了峰值之间的时间间隔,并且也有数据(底部的红色小双向箭头)。问题是,可以看出,峰值是聚集的,我想对突发大小(集群中的峰值数量)、突发间隔(第一个集群的最后一个峰值和最后一个集群的第一个峰值之间的距离)、突发数量等进行量化。 一旦确定了集群,所有这些都很容易做到。这可以通
-
使用聚合时,子查询返回超过1行
子查询返回超过1行?? 下表是我想要达到的目标 这就是为什么我认为我需要使用group by来区分user_id 我已经看过了 子查询返回超过1行-MySQL 子查询返回的行数是否超过1行? 但还是不明白。 通过连接两个不同的表,我得到了下表。 谁能帮我解决这个问题?
-
使用触发器作为SQL聚合函数的替代方案?
问题内容: 我有一个包含数百万行的表,并且经常需要知道其中一列的总数。在查询中使用SUM太慢了,因为它需要触摸整个表。是否有一种万无一失的方法来保持准确的总数而不在每个查询中进行计算? 我曾考虑过在插入,更新或删除行时使用触发器来增加和减少存储的总数。但是(我假设)这样做的一个问题是,如果表被截断,那么总数将不会为零。我可以忍受,但还有其他需要注意的地方吗?或者,如果有更好的方法可以解决此问题,请
-
JS代码触发事件代码实例
本文向大家介绍JS代码触发事件代码实例,包括了JS代码触发事件代码实例的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了js代码触发事件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
ElasticSearch术语聚合
问题内容: 我正在尝试使用以下查询对以下数据进行elasticsearch来执行术语聚合,输出将名称分解为标记(请参见下面的输出)。因此,我尝试将os_name映射为multi_field,但现在无法通过它查询。是否可以有没有令牌的索引?例如“ Fedora Core”? 查询: 数据: 输出: 映射: 问题答案: 实际上,您应该像这样更改映射 并且您的aggs应该更改为:
-
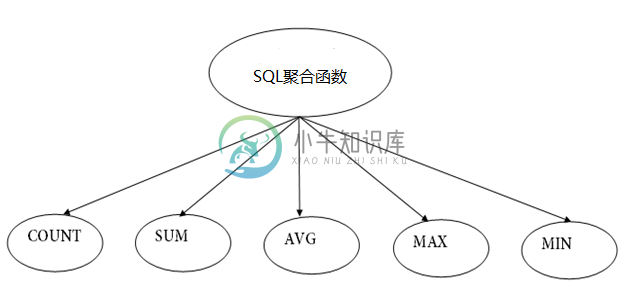 SQL聚合函数
SQL聚合函数主要内容:1.COUNT函数,2. SUM函数,3. AVG函数,4. MAX函数,5. MIN函数SQL聚合函数用于对表的单个列的多行执行计算,它只返回一个值。它还用于汇总数据。 SQL聚合函数的类型,如下图所示 - 接下来,我们一个个地讲解。 1.COUNT函数 函数用于计算数据库表中的行数,它可以在数字和非数字数据类型上工作。 函数使用返回指定表中所有行的计数。 包函重复值和值。 语法 假设有一个表,它的结构和数据如下所示 - PRODUCT COMPANY QTY RATE COST I
-
MongoDB聚合查询
主要内容:aggregate() 方法,管道MongoDB 中的聚合操作用来处理数据并返回计算结果,聚合操作可以将多个文档中的值组合在一起,并可对数据执行各种操作,以返回单个结果,有点类似于 SQL 语句中的 count(*)、group by 等。 aggregate() 方法 您可以使用 MongoDB 中的 aggregate() 方法来执行聚合操作,其语法格式如下: db.collection_name.aggregate(aggr
-
KStream 窗口聚合
尝试合并多个 Kafka 流,聚合
-
Elixir和mongodb聚合
并给我带来这些结果: {“_id”:{“name”:“city1”},“count”:212} {“_id”:{“name”:“city2”},“count”:1200} https://hexdocs.pm/mongodb/readme.html#贡献 提前谢了。