《流利说》专题
-
使用非流式应用程序/JSON的Spring WebFlux流量行为
我正在评估使用Spring Webflux,但我们必须支持期望Application/JSON,而不是Application/Stream+JSON的客户机。我不清楚Spring WebFlux如何在需要Application/JSON的客户机的情况下处理Flux的序列化。 如果一个Flux序列化为application/json,而不是application/stream+json,这是一个阻塞
-
如何在不关闭流的情况下从流量中收集
我的做法是创建一个反应endpoint,如下所示: 这会在数据可用时立即将其发回前端,然而,我的第二个用例是在数据到达时将其汇集到一个单独的集合中,这样,如果以后有类似的请求到达,我就可以从池中卸载整个数据,而不必再次访问服务。 在不关闭流量流的情况下,我有什么选择来访问流量并在它们到达时将值存储到集合中? 遇到异常: java.lang.IllegalStateException:stream已
-
Spark结构流媒体-联合两个或多个流媒体源
这是因为检查点只存储了其中一个数据流的偏移量吗?浏览Spark结构流文档,似乎可以在Spark 2.2或>中进行流源的联接/联合
-
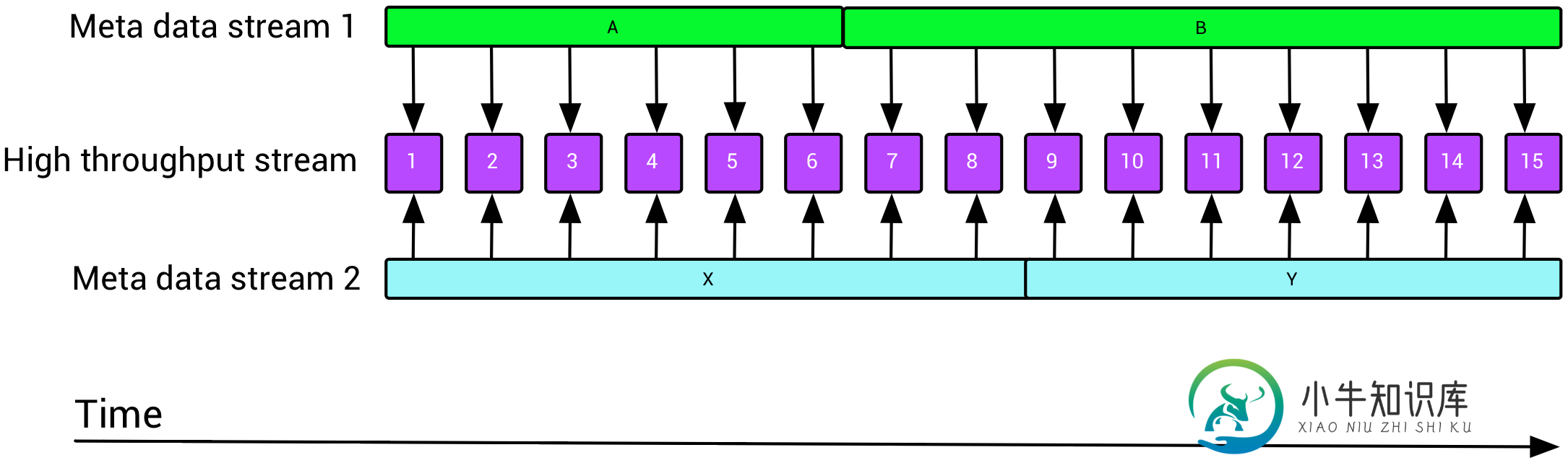 在Flink(浓缩)中结合低延迟流和多元数据流
在Flink(浓缩)中结合低延迟流和多元数据流我正在评估Flink,用于流式分析场景,但还没有找到足够的信息,说明如何实现我们今天在遗留系统中所做的ETL设置。 一个非常常见的场景是,我们有一个键控的低吞吐量元数据流,我们希望使用这些数据流来丰富高吞吐量数据流,如下所示: 这就提出了两个关于Flink的问题:如何使用时间窗口重叠但不相等的缓慢更新流来丰富快速移动的流(元数据可以活几天,而数据可以活几分钟)?如何有效地将多个(最多10个)流与F
-
仅为kafka流中的左联接在右流中获取空值
我正在尝试加入两个Kafka主题的两个数据流。 每个主题都有一个key值对,其中key是整数数据类型,value包含字符串格式的json。来自这两个源的数据类似于下面的示例(key、value): 现在我正尝试基于ProductID左联接这两个流,因此所有这些记录的键都设置为ProductID。但不幸的是,我在连接的正确流值中不断得到空值。甚至连一条记录都没有正确连接。下面是我加入这两个记录的代码
-
将一个Kafka输入流动态连接到多个输出流
Kafka流中是否内置了允许将单个输入流动态连接到多个输出流的功能?允许基于true/false谓词进行分支,但这不是我想要的。我希望每个传入日志都确定它将在运行时流到的主题,例如,日志将流到主题和日志将流到主题。 我可以在流中调用,然后写给Kafka制作人,但这似乎不是很好。在Streams框架中是否有更好的方法来实现这一点?
-
流的限制不适用于基于字符数组[duplicate]的流
为什么下面的代码不将输出限制为前三个字符? 输出: 我希望输出为:
-
Spring5WebResponsive-我们如何使用WebClient检索流量中的流数据?
当前里程碑(M4)文档显示了如何使用检索的示例: 我们如何使用WebClient将流式数据(从返回
-
你觉得知乎的盈利方式是什么呢?如果是你,你还会如何拓展知乎的盈利方式。
本文向大家介绍你觉得知乎的盈利方式是什么呢?如果是你,你还会如何拓展知乎的盈利方式。相关面试题,主要包含被问及你觉得知乎的盈利方式是什么呢?如果是你,你还会如何拓展知乎的盈利方式。时的应答技巧和注意事项,需要的朋友参考一下 知乎目前的盈利方式主要是知识付费、信息流广告和增值服务。 1.知识付费:知乎Live、知乎圆桌、大咖私家课、知乎读书会、付费咨询、知乎优质内容聚合出版 2.信息流广告:软广 3
-
Spring靴2.0。1应用程序不是以spring cloud启动的。芬奇利版本。RC1,但与芬奇利配合良好。M9
我在运行SpringBoot2.0时遇到以下异常。1使用spring clould版本Finchley的应用程序。RC1,但如果我将版本更改为Finchley,则可以正常工作。pom中的M9。xml格式: 上下文初始化期间遇到异常-取消刷新尝试:org。springframework。豆。工厂未满足的依赖项异常:创建名为“propertySourceBootstrapConfiguration”的
-
java IO异常:流关闭
问题内容: 这是我目前拥有的代码: 一切都会按预期进行(调用writeToFile方法时将文件写入)。但是,当第二次调用writeToFile方法时,出现以下错误: 该文件仍按预期第二次写入,但是它将在第二次以及以后对writeToFile()的调用中引发此错误。我想知道是什么导致此错误发生。 问题答案: 写完后就在打电话。流关闭后,将无法再次写入。通常,实现此目标的方法是将结束状态移至write
-
合并地图 Java 8流
问题内容: 我想将两个Map与JAVA 8 Stream合并: 我尝试使用此实现: 但是,此实现只会产生如下结果: 如果中没有包含一个键,则会将其作为新键添加到相应的String列表中。如果键在和中重复,则两个值列表将被合并为:,然后是。 问题答案: 您可以通过遍历中的所有条目并将它们合并到中来实现此目的。 下面通过调用操作消耗每个条目的键和值的位置来遍历的条目。对于每个条目,我们叫上:这将要么创
-
流模式MODE_STREAMING中的AudioTrack
问题内容: 我需要流式传输在运行时生成的PCM数据。所以我有一个带有循环的线程 不幸的是,这不起作用。似乎这并不取决于AudioTrack缓冲区的大小。我希望它很小以模拟某种低延迟行为(150毫秒),以便用户可以动态更改getPCM()选择的PCM。 但是,我试图将缓冲区大小增加到100k,但没有结果 问题答案: 这是对我有用的简短示例:
-
Spark Kafka流媒体问题
问题内容: 我正在使用Maven 我添加了以下依赖项 我还在代码中添加了jar 它完全可以正常工作,没有任何错误,在通过spark-submit提交时出现以下错误,非常感谢您的帮助。谢谢你的时间。 线程“主要” java.lang.NoClassDefFoundError中的异常:sun.reflect处的KafkaSparkStreaming.sparkStreamingTest(KafkaSp
-
通过谓词限制流
问题内容: 是否存在Java 8流操作来限制(可能是无限的)Stream直到第一个元素与谓词不匹配? 在Java 9中,我们可以takeWhile像下面的示例那样使用它来打印所有小于10的数字。 由于Java 8中没有这样的操作,以一般方式实现它的最佳方法是什么? 问题答案: 这样的操作在Java 8中应该是可能的,但不一定能有效地完成-例如,您不必并行化这样的操作,因为您必须按顺序查看元素。 该