《需求分析师》专题
-
Elasticsearch“ pattern_replace”,在分析时替换空格
问题内容: 基本上,我想删除所有空格并将整个字符串标记为单个标记。(稍后我将在其上使用nGram。) 这是我的索引设置: 我尝试使用和来代替。 但是,当我分析文本“ beleza na web”时,它仍然创建三个单独的标记:“ beleza”,“ na”和“ web”,而不是一个“ belezanaweb”。 问题答案: 分析器首先对字符串进行标记处理,然后应用一系列标记过滤器来分析字符串。您已将
-
Elasticsearch中的默认索引分析器
问题内容: 我在Elasticsearch上遇到问题,我不希望对索引项进行分析。但是elasticsearch有一些默认设置,可以在空间上标记它。因此,我的方面查询未返回我想要的结果。 我读到索引类型的属性应该工作。但是问题是我事先不知道我的文档结构。我会在不知道表结构的情况下将随机MySQL数据库索引到elasticsearch。 我如何设置elasticsearch,使其默认情况下会一直使用,
-
在ElasticSearch设置中更新分析器
问题内容: 我正在使用Sense(Chrome插件),并且已经成功设置了分析仪,并且可以正常工作。如果我在设置上发出GET(/ media / _settings),则返回以下内容。 我正在尝试通过执行以下操作来更新它: 关闭索引 发出此PUT命令(删除过滤器) 打开索引 但是,当设置恢复时,不会删除过滤器。创建分析器后,是否可以不对其进行更新? 问题答案: 简短答案:不可以。 更长的答案。从ES
-
请分析一下代码的作用
问题内容: var arr = []; function l(min,max,maxLen){ return function(arr){ var random = Math.floor(Math.random() * (max - min + 1)) + min; if(!arr.includes(random)){ arr.push(random); } if(arr.length >= ma
-
什么是算法的摊销分析?
问题内容: 与渐进分析有何不同?您何时使用它,为什么? 我读过一些写得不错的文章,例如: http://www.ugrad.cs.ubc.ca/~cs320/2010W2/handouts/aa-nutshell.pdf http://www.cs.princeton.edu/~fiebrink/423/AmortizedAnalysisExplained_Fiebrink.pdf 但我仍然没有完
-
适用于Linux的Java分析工具
问题内容: 我想在Linux服务器上以剖析模式运行Java程序。 是否有任何可以在命令提示符下对Linux服务器上的Java程序进行概要分析的概要分析工具? 问题答案: 所有这些Java性能分析工具都可以在Linux中使用: 你的包 JProfiler HPROF(Java 5+) 杰拉特
-
Linux日志文件的格式分析
只要是由日志服务 rsyslogd 记录的日志文件,它们的格式就都是一样的。所以我们只要了解了日志文件的格式,就可以很轻松地看懂日志文件。 日志文件的格式包含以下 4 列: 事件产生的时间。 产生事件的服务器的主机名。 产生事件的服务名或程序名。 事件的具体信息。 我们查看一下 /var/log/secure 日志,这个日志中主要记录的是用户验证和授权方面的信息,更加容易理解。命令如下: [roo
-
Linux分析系统性能(sar命令)
sar 命令很强大,是分析系统性能的重要工具之一,通过该命令可以全面地获取系统的 CPU、运行队列、磁盘读写(I/O)、分区(交换区)、内存、CPU 中断和网络等性能数据。 sar 命令的基本格式如下: [root@localhost ~]# sar [options] [-o filename] interval [count] 此命令格式中,各个参数的含义如下: -o filename:其中,
-
分析第一个C语言程序
主要内容:函数的概念,自定义函数和main函数,头文件的概念,最后的总结前面我们给出了一段最简单的C语言代码,并演示了如何在不同的平台下进行编译,这节我们来分析一下这段代码,让读者有个整体的认识。代码如下: 函数的概念 先来看第 4 行代码,这行代码会在显示器上输出“小牛知识库”。前面我们已经讲过,puts 后面要带 ,字符串也要放在 中。 在C语言中,有的语句使用时不能带括号,有的语句必须带括号。带括号的称为 函数(Function)。 C语言提供了很多功能,例如输
-
Python词干分析(使用数据帧)
我创建了一个数据框,其中包含要被词干化的句子。我想用雪球机来获得更高的分类算法精度。我该如何实现这一点?
-
C++析构函数解分配失败
在下面的C++代码中,在析构函数调用期间,它会崩溃,并出现以下错误。 如果打印了这条消息,至少程序还没有崩溃!但您可能还想打印其他诊断消息。DSCodes(16782,0x1000EFE00)malloc:***对象0x10742E2F0错误:未分配释放的指针DSCodes(16782,0x1000EFE00)malloc:***在malloc_error_break中设置断点以调试 有人能告诉我
-
分析xmldsig-core/xmldsig-core-schema.xsd时出错
我正在从wsdl文件生成客户机代码。在代码没有任何更改的情况下,它停止工作,现在我得到以下错误消息: [ERROR]未能在项目myproject:org.apache.cxf:cxf-codegen-plugin:2.1.2:wsdl2java(generate-sources)上执行myproject:org.apache.cxf.wsdl11.wsdlruntimeException:无法从:
-
用java解析分割的csv文件
我有一个带有注释的csv文件,其值需要在两个ArrayList之间拆分。例如: 实现这一目标的最佳方式是什么?我是否应该使用一个计数器,每次状态从%变到某个值时递增,反之亦然,然后如果计数器% 2 = 0,那么添加一个新的ArrayList并开始写入它?这是我能想到的唯一办法,但似乎有点笨拙,还有人有更好的主意吗? 编辑:我已经写了实际解析csv值的代码,我不需要帮助,只是想知道如何将值分成两个列
-
sonarqube分析触发器的自动化
我正在使用Sonarqube6.7,开发人员的版本,我在本地机器上通过声纳扫描器msbuild运行分析。有什么方法可以:1)在代码签入时自动触发此分析,而不使用声纳扫描仪?2)我可以通过邮件获得分析报告吗?我必须为每一个这些做什么?提前谢谢!
-
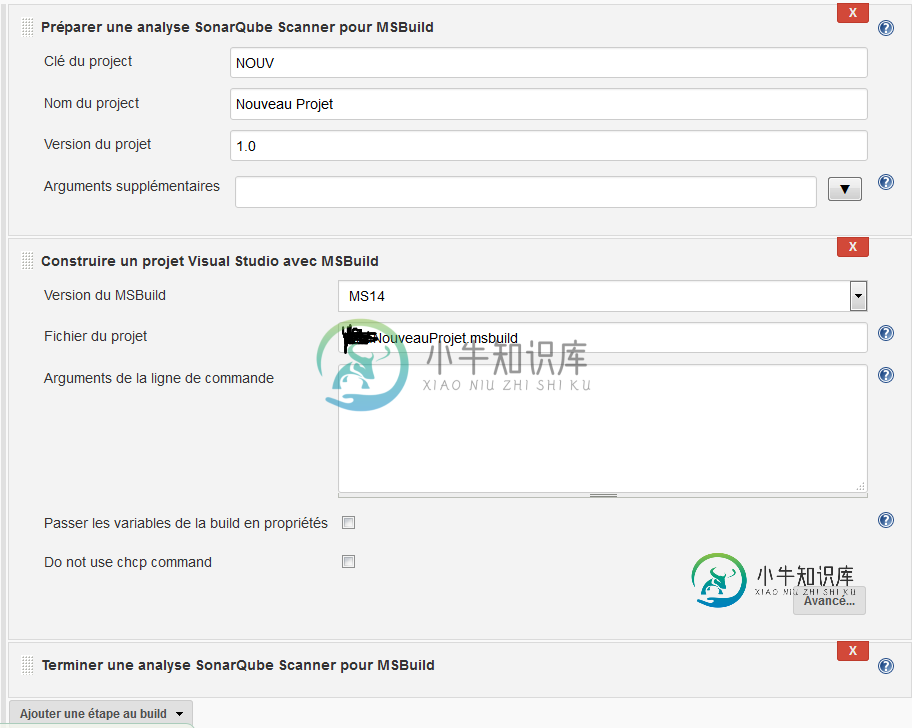 SonarQube scanner for MSBuild不分析C#代码
SonarQube scanner for MSBuild不分析C#代码SonarQube统计我们项目中的C#行,计算覆盖率和重复,但不检查问题或代码气味。例如,以下愚蠢的代码不会生成任何代码气味: 我们检查了C#质量配置文件(香草声纳方式)。没有文件排除。分析在javascript代码中运行良好。 我们正在使用: null null 在构建日志中,我们发现: la cible“runcodeanalysis”répertoriée dans unattribut B