《市场营销人求职交流聚集地》专题
-
1.5.3.1.18.3 聚合
Leaflet.markercluster 是一个提供动态的标识聚类功能的 Leaflet 插件库。 引入插件 Leaflet.markercluster 包括两种方式: 下载 Leaflet.markercluster 1.进入 github 下载 Leaflet.markercluster,下载地址为: https://github.com/Leaflet/Leaflet.markerclus
-
2.3. 聚类
校验者: @花开无声 @小瑶 翻译者: @小瑶 @krokyin 未标记的数据的 Clustering(聚类) 可以使用模块 sklearn.cluster 来实现。 每个 clustering algorithm (聚类算法)有两个变体: 一个是 class, 它实现了 fit 方法来学习 train data(训练数据)的 clusters(聚类),还有一个 function(函数),是给定
-
为什么任务在Spring云数据流中上线后不销毁?
我已经创建了一些Spring批处理项目,并使用Spring Cloud Data Flow(SCDF)部署了这些作业。 在SCDF中启动任务(作业)后,创建JVM执行任务(作业)。 但是,当任务完成时,JVM并不结束。它仍然存在。 当我启动作业20次时,它宣布 并且有一些关于我的作业的信息,作业的第一个日志是以: 但是在我为Spring批处理项目使用了以下属性之后: 并使用JobExecution
-
并行流,收集器和线程安全
问题内容: 请参阅下面的简单示例,该示例计算列表中每个单词的出现次数: 最后是。 但是我的数据流很大,我想并行化作业,所以我写: 但是我注意到这很简单,所以我想知道是否需要显式请求并发映射以确保线程安全: 非并行收集器可以安全地与并行流一起使用吗?从并行流中收集时,我是否应该仅使用并发版本? 问题答案: 非并行收集器可以安全地与并行流一起使用吗?从并行流中收集时,我是否应该仅使用并发版本? 在并行
-
Java 我应该返回集合还是流?
问题内容: 假设我有一个将只读视图返回到成员列表的方法: 进一步假设所有客户要做的就是立即遍历列表一次。也许将播放器放入JList之类。客户端就不能存储到列表的引用以便稍后进行检查! 在这种常见情况下,我应该返回流吗? 还是在Java中返回流非惯用语?流是否设计为始终在创建它们的相同表达式内被“终止”? 问题答案: 答案是一如既往的“取决于”。这取决于返回的集合的大小。这取决于结果是否随时间变化,
-
集团财产不工作在春流云?
我使用Spring Stream云来消费Kafka上的消息。当Kafka上的信息产生时,所有的消费者都受到了冲击。 但Kafka的文献表明,通过使用群体,只有一个消费者消费信息。 这是我的消费代码。 这是我的配置,但我的两个方法都调用了:(
-
使用流水线理解MIPS程序集
对于MIPS架构的标准5级管道,并假设一些指令相互依赖,如何将管道气泡插入到以下汇编代码中? 首先我们插入一个气泡,我们 如您所见,当I3暂停时,I4可以继续解码。对不对?下一个 我认为这在MIPS的标准管道中是可能的,但有人说,每当插入气泡时,整个管道都会停顿。如何才能解决这个问题?
-
使用Java流删除和收集元素
假设我有一个,还有一个,它匹配我想从中删除的元素。但我不只是想丢弃它们,我想将匹配的元素移动到一个新集合中。在Java 7中,我会这样做: 我很好奇是否有一个流/Java8方法来做这件事。不幸地只是返回一个(甚至没有删除元素的数量?太糟糕了。)我设想了这样的东西(当然不存在): 注:此问题受类似问题启发;这个问题是关于在从集合中移除的项上获取流的更一般的情况。正如链接问题中所指出的,命令式解决方案
-
Spring Integration DSL在流之间收集度量
有什么方法可以从InboundAdapter到OutboundAdapter收集这样的度量: 每秒的消息量; 邮件总数; 分钟通过流传递时间; 通过流的最大传输时间; 通过流传递的平均时间; 错误消息的数量; 处理邮件的持续时间; 我尝试了使用MessageChannelMetrics提出的解决方案: https://docs.Spring.io/Spring-Integration/refere
-
如何将流收集到列表?[副本]
出了什么问题?
-
带有火花流集成错误的kafka
我不能用火花流运行Kafka。以下是我迄今为止采取的步骤: > 将此行添加到- Kafka版本:kafka_2.10-0.10.2.2 Jar文件版本:spark-streaming-kafka-0-8-assembly_2.10-2.2.0。罐子 Python代码: 但我仍然得到以下错误: 我做错了什么?
-
带有SQS和Reactive的Spring集成流DSL
如何使用DSL为以下步骤设置无功流: 使用SqsMessageDrivenChannelAdapter接收SQS消息 使用验证方法验证Json消息[类] 将json转换为对象 将对象传递给服务激活器(
-
我的Spring集成流的一些问题
我使用的是带有spring Integration 5.3.0的spring boot 2.3.0版本,不知何故,我无法让下面的代码正常工作。应用程序启动,没有错误,但当控制到方法时,什么也没有发生或打印。谁能告诉我我错过了什么。任何帮助都很感激。谢了。
-
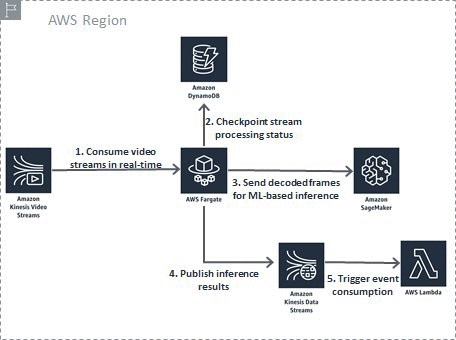 Kinesis视频流与Amazon SageMaker的KIT集成
Kinesis视频流与Amazon SageMaker的KIT集成我正在做一个项目,我需要将视频从我的IP摄像机发送到Kinesis视频流,并使用Sagemaker来托管我的ML模型,然后它将实时分析来自Kinesis视频流的视频。 我跟踪了这个链接:https://aws.amazon.com/blogs/machine-learning/analyse-live-video-at-scale-in-real-time-using-amazon-kinesis
-
Java 8流-收集可能为空的值