《群面攻略》专题
-
我是否应该在使用pm2集群模式的同时使用Node.js Greenlock-Express集群模式?
我正在使用Node.js、Express和pm2构建一个用于流程管理的无状态Web应用程序。在生产环境中,我为服务器CPU的每个核心运行一个应用程序实例(感谢pm2集群模式)。 最近我开始阅读Greenlock-Express(用于自动获取证书),它还有一个“cluster”属性,如果我理解正确的话,它基本上与pm2集群模式做的事情相同。 如果我在集群模式下同时运行Greenlock-Expres
-
跨GCP项目在GKE集群中将Google服务帐户与Kubernetes集群服务帐户绑定
我在一个GCP项目中构建了一个Google Kubernetes引擎(GKE)集群。 根据集群上运行的应用程序的不同用例,我将应用程序与不同的服务帐户和不同的授予权限相关联。为此,我将Google服务帐户(GSA)与库伯内特斯集群服务帐户(KSA)绑定如下: 参考:https://cloud.google.com/kubernetes-engine/docs/how-to/workload-ide
-
Amazon Elasticache Redis集群-无法获得端点
问题内容: 我需要获取Amazon Elasticache中Redis集群的终端节点。以下代码适用于Memcached群集,但不适用于Redis: 输出为: 请注意,群集对象如何包含端点信息(键:),但仍返回。 我如何获得终点? 问题答案: 通常,我在发布问题后就找到了解决方案。在Redis中,您必须访问缓存节点:
-
如何使用node.js连接到ElastiCache集群
问题内容: 我们知道不建议在Amazon实例外部访问ElastiCache,因此我们仅在Amazon EC2实例内部进行尝试。 我们有一个具有9个节点的ElastiCache Redis集群 。当我们尝试使用常规redis实现连接到它时,它会引发一些Moved错误 根据@Miller尝试了重试策略方法。还尝试过使用不稳定和稳定(可怜的人)实现的RedisCluster。 这些实现均无作用。有什么建
-
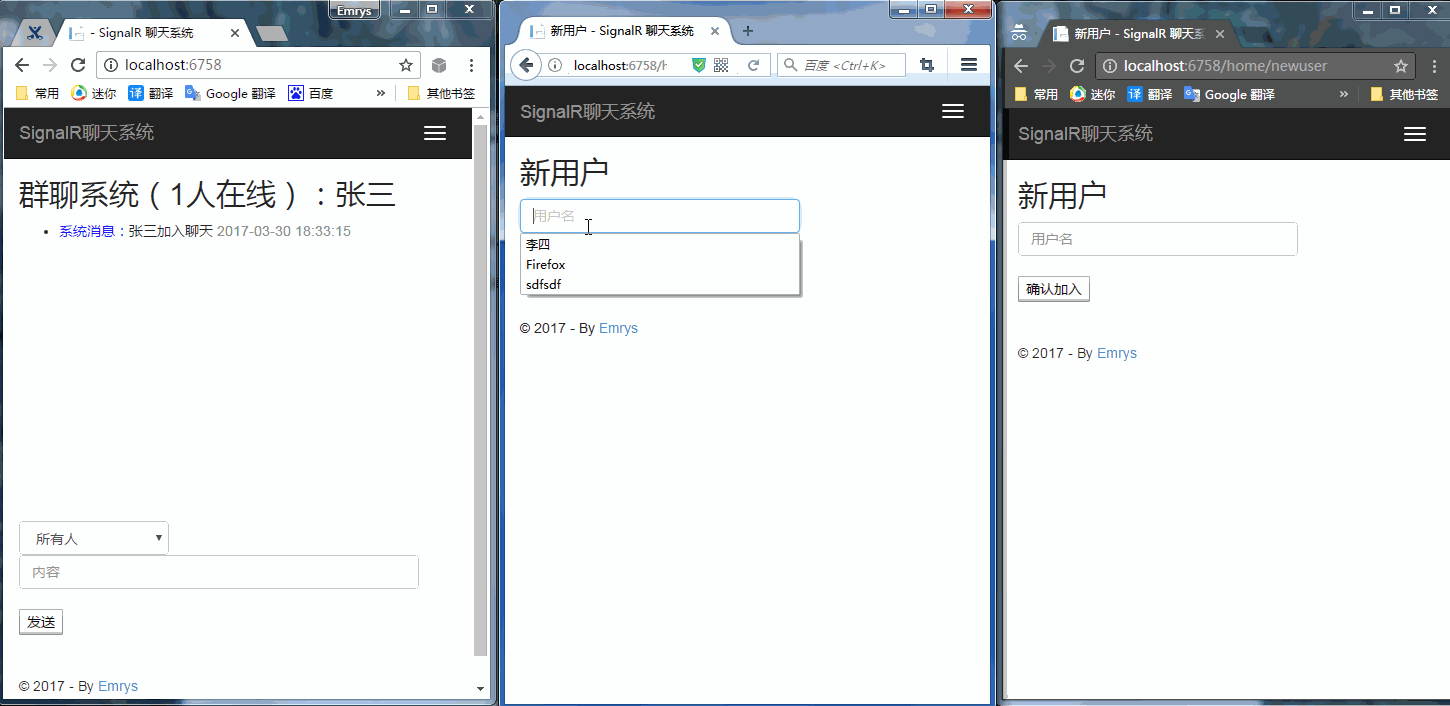 Asp.net SignalR应用并实现群聊功能
Asp.net SignalR应用并实现群聊功能本文向大家介绍Asp.net SignalR应用并实现群聊功能,包括了Asp.net SignalR应用并实现群聊功能的使用技巧和注意事项,需要的朋友参考一下 ASP.NET SignalR 是为 ASP.NET 开发人员提供的一个库,可以简化开发人员将实时 Web 功能添加到应用程序的过程。实时 Web 功能是指这样一种功能:当所连接的客户端变得可用时服务器代码可以立即向其推送内容,而不是让服务
-
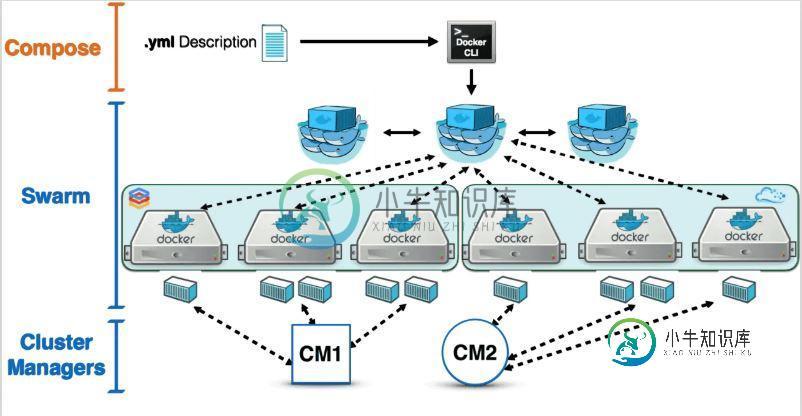 Docker 搭建集群MongoDB的实现步骤
Docker 搭建集群MongoDB的实现步骤本文向大家介绍Docker 搭建集群MongoDB的实现步骤,包括了Docker 搭建集群MongoDB的实现步骤的使用技巧和注意事项,需要的朋友参考一下 前言 由于公司业务需要,我们打算自己搭建 MongoDB 的服务,因为 MongoDB 的云数据库好贵,我们这次采用副本集的方式来搭建集群,三台服务器,一主、一副、一仲裁 基本概念 Replica Set 副本集:一个副本集就是一组 Mongo
-
MySQL扩展解决方案(复制,群集)
问题内容: 在启动时,我正在为我们的数据库考虑扩展解决方案。MySQL至少使我感到困惑(至少对我而言),MySQL具有MySQL群集,复制和MySQL群集复制(来自5.1.6版),它是MySQL群集的异步版本。MySQL手册解释了其集群FAQ中的一些差异,但是很难确定何时使用它们中的一个。 我将不胜感激那些熟悉这些解决方案之间的区别以及优点和缺点以及何时建议使用每种解决方案的人的任何建议。 问题答
-
集群成员之间的Hazelcast序列化
我有一个配置类,它存储在hz IMap 这个配置类是1-st实例成员 P. S成员是两个不同的应用程序的一部分。 此配置作为对象从第一个集群成员推送到IMap 我的目标是在另一个模块中看到这个配置 如何在第二个成员实例中序列化该对象 如果调用 我得到了
-
Mapsforge不从域重新绘制集群POI
我使用Realm从DB加载POI。接下来,通过mapsforge将这些点添加到集群实现中。此代码运行良好: 它在地图上绘制所有POI,但若我在领域集群中使用RxJava,就永远不会在地图上添加POI。代码如下:
-
jquery ui map群集器标记不显示
我正在使用jquery ui map,我正在从geoJSON加载标记,然后我想对它们进行聚类,但我可以看到标记,但不能看到聚类。 我的代码如下: 当我执行console.log($(this).gmap('get','marks'))时;它是空的,我不明白它为什么会这样。 你有什么主意吗? 谢谢
-
Spark数据帧中的分区和群集
我们有没有可能在Spark中先按一列分区,然后再按另一列聚类? 在我的例子中,我在一个有数百万行的表中有一个< code>month列和一个< code>cust_id列。我可以说,当我将数据帧保存到hive表中,以便根据月份将该表分区,并按< code>cust_id将该表聚类成50个文件吗? 忽略按< code>cust_id的聚类,这里有三个不同的选项 第一种情况和最后一种情况在 Spark
-
尝试使用docker-compose设置elasticsearch群集
我的环境是两台物理机器,都运行在Docker-Compose中。 我想创建跨越两个docker容器的elasticsearch集群。 我这样的建筑 两个容器不能互相连接,有什么想法吗? docker image正在使用ElasticSearch:5.4.2 Docker-compose.yml ElasticSearch.yml 和日志 [2017-11-09T05:56:10,552][信息][
-
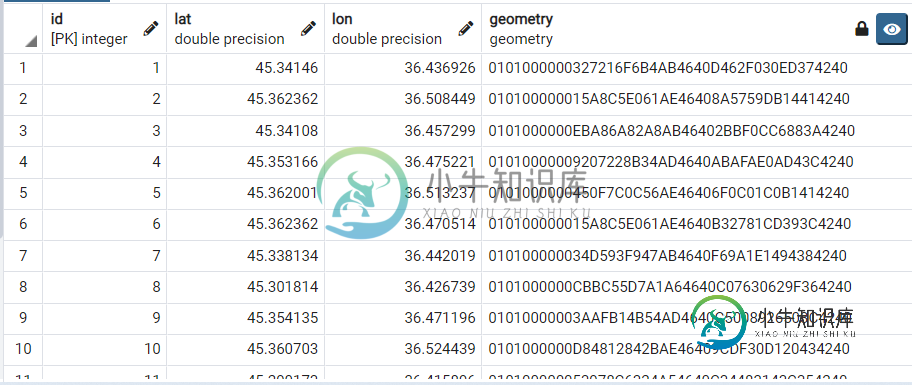 找到一公里内最大的点群
找到一公里内最大的点群我在研究空间日期时遇到了一个问题。我有一个包含列的表:对象id及其坐标(纬度和经度,数据类型是几何体)。我需要找到一公里内最大的一组点。我怎么能这么做?
-
tomcat集群环境中的内存泄漏
我的应用程序出现OutOfMemory异常。我已经把垃圾堆和垫子翻了个底朝天。在分析我的应用程序内存使用情况时,我发现以下疑点。我无法理解这些嫌疑人背后的主要原因。 请帮助我了解这种泄漏的怀疑和什么相关的解决方案。 “AJP-Bio-9002”-exec-5 at java.util.arrays.copyof([ci)[C(arrays.java:2882)at java.lang.abstra
-
Spark+Mesos集群模式,谁上传罐子?
我正在尝试用Mesos集群模式运行Spark应用程序。(我有客户端模式工作,但仍然想尝试集群模式) 在YARN集群模式下,Spark的YARN客户机实现将把应用程序jar上传到HDFS,这样驱动程序和所有执行程序都可以访问jar,但是我在RestSubmissionClient中找不到这样的代码,Mesos或Standalond集群模式使用的是RestSubmissionClient。 在这种情况