《大数据测试》专题
-
 10.24京东大数据
10.24京东大数据1.自我介绍 2.大数据项目battle 3.对于窗口函数的了解 有什么,什么场景,怎么用 4.文本拼接函数是什么 5.hbase负载均衡怎么实现 6.cv项目battle 不同模型的区别 网络+部署 7.反问 京东商城核心检索业务 和leader讨论面试结果,一周内hr会联系
-
 soul大数据面经
soul大数据面经1.自我介绍 2.你的优势是什么 3.对数仓怎么看 4.sql,有id,score。怎么实现按score排序并且要排名,不能使用开窗函数。
-
 tplink大数据开发
tplink大数据开发6.27一面 20min 问简历,介绍项目提到的各种模型,做了什么优化 有没有spark实践的经历 介绍一下hadoop 了解哪些机器学习算法 xgboost和随机森林的区别 有用Java做过项目吗(无...) 反问 6.28二面 35min 简历项目一个一个详细讲 transformer编码器解码器区别 transformer位置编码的情况 spark实践经历 反问
-
 蔚来大数据笔试 7.17
蔚来大数据笔试 7.17第一题合并两个二叉树lc617 第二题爬楼梯,多少种爬法,10000级楼梯 第三题滑动窗口的最大值lc239 #蔚来提前批笔试#
-
 京东方大数据面试
京东方大数据面试7.22一面 spark的底层原理 spark yarn client和yarn cluster的区别 dataframe如何创建 数仓项目中用了几个节点,各个组件如何部署的 HA介绍一下 数仓分层介绍 hadoop的一些命令 hadoop如何更改文件所有者 kafka的监控 linux命令,vim编译器的命令 集群间节点是如何通信的 core-site文件一般配置什么内容 ranger权限管理的
-
 大华测试
大华测试#面经# 二面挂 大华一面:自我介绍。9.28 广播mac地址 python 转置三✖️九矩阵 简单数据库 求女生的英语成绩 python 用过哪些库 写过项目 udp tcp区别 直播用什么,都用 udp居多; c语言是够熟练 selium定位元素; 知道哪些排序方法; 二面:9.29 测试流程 测试的理解 发展方向 场景题 记得不太清楚了 但是大部分都是围绕测试基础知识展开 没有八股 自己觉得
-
13.9 用(测试数据)表驱动测试
编写测试代码时,一个较好的办法是把测试的输入数据和期望的结果写在一起组成一个数据表:表中的每条记录都是一个含有输入和期望值的完整测试用例,有时还可以结合像测试名字这样的额外信息来让测试输出更多的信息。 实际测试时简单迭代表中的每条记录,并执行必要的测试。这在练习 13.4 中有具体的应用。 可以抽象为下面的代码段: var tests = []struct{ // Test table
-
google play Alpha/Beta测试的最大测试人员数
我的应用程序还没有发布。通过Google Play测试应用程序的Alpha/Beta测试者的最大数量是多少?对于iOS来说,每个构建需要1000个外部测试人员。Google Play的限制是多少?
-
 大华二面 大数据开发c++
大华二面 大数据开发c++1.hashmap底层数据结构 2.virtual的使用场景,虚函数表 3.设计模式 4.多线程同步的方法 5.三次握手 6.智能指针有哪些,如何设计一个share_ptr? 7. vector是如何实现的,和list相比有何优缺点? 8.想问我网络编程方面的,我说不熟悉,跳过了…… 9.c++ 源文件到可执行文件的过程 9.多线程适用于那些应用场景? 10.stl哪些容器是线程安全的 11.补充
-
大数据数仓高级面试题 3
主要内容:1.建模锯齿,2.数据粒度的锯齿操作,3.下游表依赖上游表问题,4.数仓数据域划分方式,5.数仓一致性是如何保证的,6.数仓优化,7.数据全生命周期,8.数仓建模问题,9.数仓建模过程1.建模锯齿 建模锯齿是指在建模过程中的一种常见的效应,其中模型的输出可能会产生锯齿状的波动。这种效应通常是由于模型的不稳定性或过度拟合导致的。 在建模过程中,锯齿可能会使模型的表现变差,并且在预测新数据时也可能出现不一致的结果。因此,在建模时需要注意避免出现锯齿状的波动。 一种常用的方法是使用正则化来限
-
大数据数仓高级面试题 1
主要内容:1.数仓高内聚低耦合,2.多重粒度,3.如何提高查询效率,4.数仓数据域划分几种方式,5.粒度操作,6.SQL实现,7.数仓中ODS层命中多少为合理,8.数仓价值链的体现和实现,9.建立数仓的步骤,10.指标生命周期的评估,11.数据治理,12.数仓的目的1.数仓高内聚低耦合 一般复杂的公共逻辑可以采用抽象类和抽象方法的方式下沉到共有模块中,然后由相关子类去实现抽象方法,来实现不同的功能。这样可以将复杂的逻辑拆分成各个子类,使得类之间的耦合度降低,提高代码的可维护性。 2.多重粒度 在
-
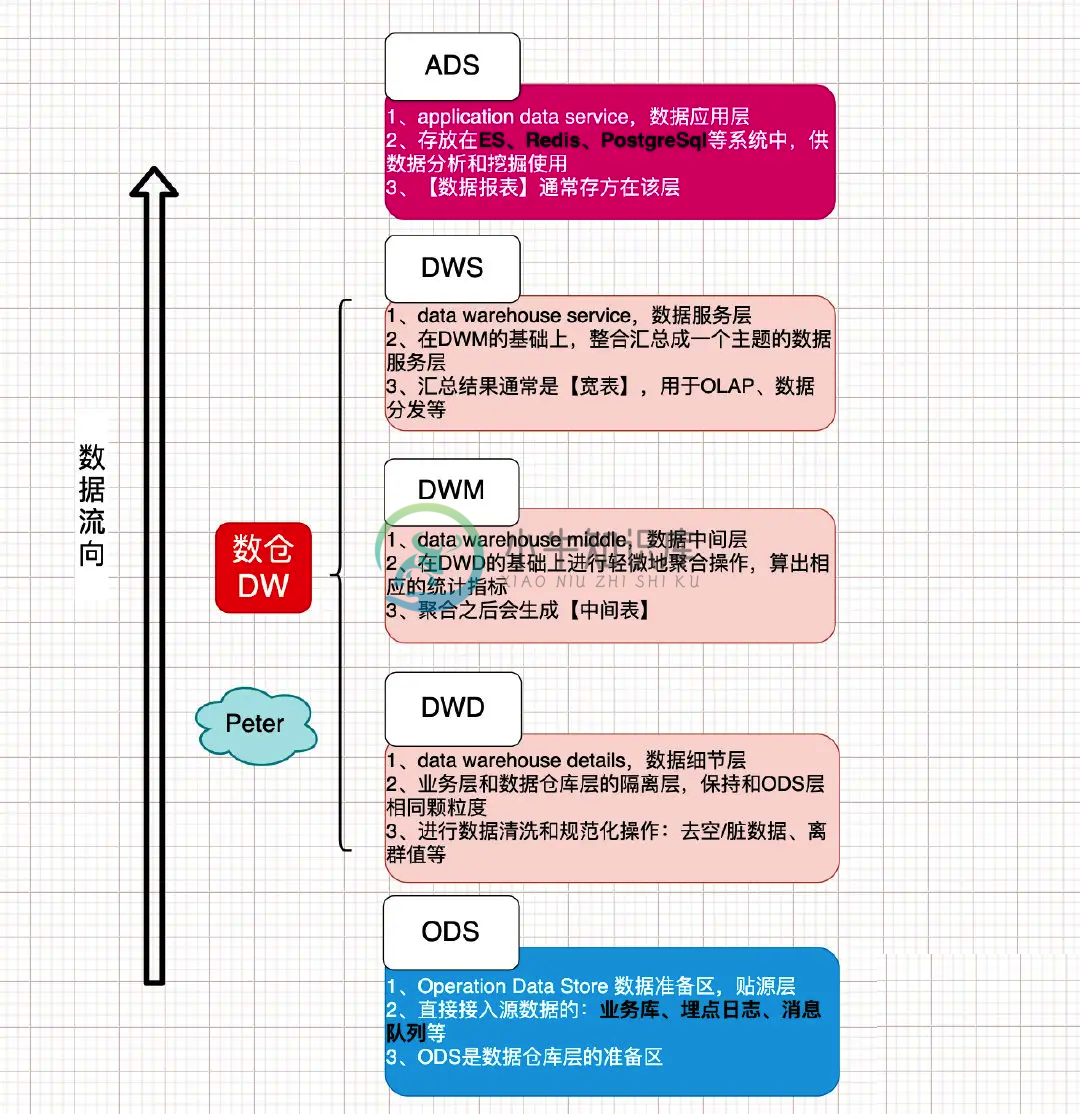 大数据数仓高级面试题 4
大数据数仓高级面试题 4主要内容:1.数仓构建,2.数仓最重要的是什么,3.如何保证数据的准确性,4.如何做数据治理?数据资产管理呢,5.如何控制数据质量,6.元数据的理解?元数据管理系统,7.数仓如何分层的?及每一层的作用,8.为什么要分层1.数仓构建 1). 前期业务调研 需求调研 数据调研 技术选型 2). 提炼业务模型,总线矩阵,划分主题域; 3). 定制规范 命名规范、开发规范、流程规范 4). 数仓架构分层:一般分为操作数据层(ODS)、公共维度模型层(CDM)和应用数据层(ADS),其中公共维度模型层包括
-
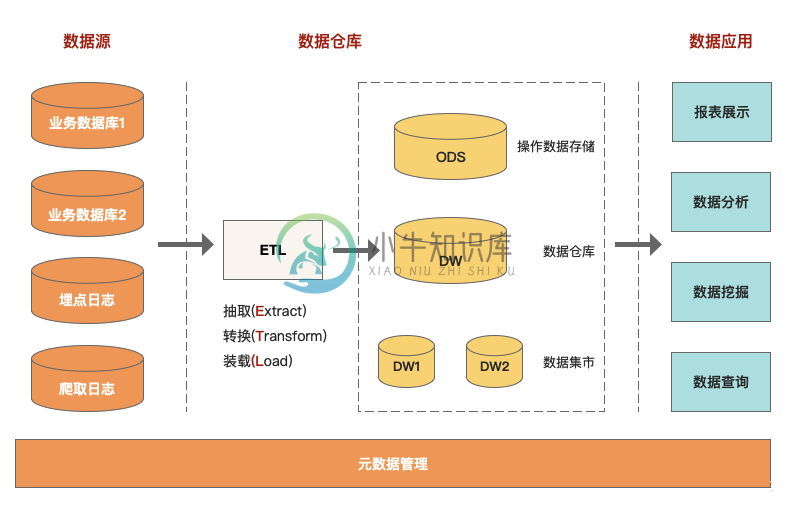 大数据数仓高级面试题 2
大数据数仓高级面试题 2主要内容:1、什么是数据仓库?,2、数据仓库和数据库的区别?,3、如何构建数据仓库?,4、什么是数据中台?,5、数据中台、数据仓库、大数据平台、数据湖的关键区别是什么?,6、大数据有哪些相关的系统?,7、如何建设数据中台?,8、数据仓库最重要的是什么?,9、概念模型、逻辑模型、物理模型分别介绍一下?,10、SCD常用的处理方式有哪些?,11、怎么理解元数据?,12、数仓如何确定主题域?,13、如何控制数据质量?,,,,1、什么是数据仓库? 权威定义:数据仓库是一个面向主题的、集成的、相对稳定的、
-
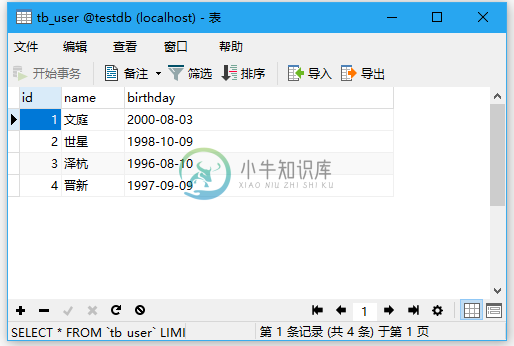 JMeter数据库测试计划
JMeter数据库测试计划主要内容:创建JMeter测试计划,添加JDBC请求,保存并执行测试计划,验证输出在本节中,将学习如何创建测试数据库服务器的基本测试计划。 为了我们的测试目的,这里将创建一个数据库。 可以根据自己的方便使用任何其他数据库服务器。还可以参考我们的MySQL数据库教程:https://www.xnip.cn/mysql 来了解有关数据库创建的更多信息。 在系统上安装数据库服务器之后。 按着这些次序: 创建名为testdb的数据库。 创建表 - 。 将记录插入到表中。 下图显示了创建
-
 A/B测试收集数据
A/B测试收集数据主要内容:Google Analytics / Mix面板(分析工具),鼠标流/疯狂蛋(重播工具),WebEngage(测量工具),其他工具 - 聊天,电子邮件来自Google Analytics的数据可以帮助您找到访问者的行为。 总是建议从网站收集足够的数据。 尝试找到转化率较低或可以提高的高丢弃率的网页。 在本章中,我们将讨论一些可用于收集A/B测试数据的工具。 Google Analytics / Mix面板(分析工具) 大多数网站都安装了Google Analytics,以了解访问者与网