《大数据研发实习》专题
-
 京东数据开发一面
京东数据开发一面为啥官网上写着java 数据库,结果面试全问我C++,这几天看的数据库都没问啥 30min 1. 自我介绍 2. 说一下Linux和常用命令,线程和进程的区别 线程和进程的本质区别是什么 3. Linux如何查看是哪一个进程占用率指定端口 4. C++了解到什么程度 5. C++中的const和底层const 的区别 fun(int i) fun(const int i)有什么区别,编译器怎么看
-
 滴滴数据开发面试
滴滴数据开发面试状态最不好的一次,面试官说话温温柔柔的我本来中午就没睡感觉快要睡着了 腾讯会议,对方没开摄像头(整个屏幕都是我的脸) 自我介绍 然后问了对数据开发的了解 数据建模、数据分层 然后就开始共享屏幕写sql(本来让我写hive sql,我说我不会) 三道题,写的稀碎... 主要是问题的逻辑我理解不了,再加上自己sql写的没那么熟练,在加上我真的好困啊 然后写完了 他就和我说,多练练sql,别搭虚拟机框架
-
 团子数据开发oc了
团子数据开发oc了顺带分享面经 9.05到家一面: 自我介绍 实习相关 画像表和指标维度表的区别 标签体系 数据结构基础。dag如何排序 算法,删除链表重复元素 9.18美团平台一面: 数仓分层 spark任务提交 数据倾斜,如何处理 数仓好坏 开发完成之后如何做数据验证,如何确保是对的 反转链表 9.20二面: 学校 实习 在实际工作中对数仓理论的认识 如何对订单数据建模,考虑哪些维度 任务跑得慢怎么分析 如何估
-
 滴滴 数据开发面经
滴滴 数据开发面经一面 经典的自我介绍 我看你实习经历挺多的,你挑一个项目讲讲看吧?我希望听到的是背景,目的以及你做了什么 balabala 嗯嗯,这么看我了解你的业务背景了,那你觉得你项目的目的是什么呢? 我:balabala,为了看a,b,这几个指标 拆解之后是看这些内容,但是主要是为了什么呢?是不是为了提升用户的体验 (面试官真的一步步引导) 再说说你做了哪些表吧,涉及到哪些层?有哪些比较重要的指标。 bal
-
 京东数据开发一面
京东数据开发一面#软件开发笔面经# 1、自我介绍 2、面试官:你倾向于数仓还是数开。我:实习做的数仓,所以更倾向于数仓。面试官:好的,我们是做后端开发相关的 3、说一下实习期间做的工作 4、介绍下你的第一个项目 5、了解过zookeeper吗 6、spark中dataframe和dataset的区别 7、简单说一下kafka是干什么的,消息能保证全局有序吗 8、了解容器吗,docker和kubernetes 9、
-
 数据开发快手一面
数据开发快手一面1.挖项目 2.jvm垃圾回收 3.找问题,String类型循环内使用+= 4.mysql 聚簇索引和非聚簇索引 5.hashmap原理 6.索引数据结构(b+树),特点 7.hive数据倾斜 8.hive mapjoin ,bucket map join ,SMB join 9.flink watermark 10.flink checkpoint. 三种分布式快照算法 11.flink 状态
-
 tplink 数据开发 一面 20min
tplink 数据开发 一面 20min1.自我介绍、成绩排名、读研计划、奖学金、是否挂科、有无数模竞赛经历 2.介绍项目,数仓设计中主要考虑的点 3.开发用的语言 4.项目数据量多少,报表用什么软件做的 5.实习工作介绍,dqc怎么用的 6.实习最难的一点是什么 7.机器学习和深度学习了解吗 8.python常用的包 9.rdd和dataframe和dataset的区别 10.hive查询过程怎么优化 11.你的性格在工作中的优势 总
-
 金山云 数据开发 oc
金山云 数据开发 oc聊项目 面相对象三大特性 JVM内存结构 Hashmap springIOC AOP 缓存雪崩 sql问题
-
 众安在线——数据开发
众安在线——数据开发已Offer 技术面(1h,已过) 1. 自我介绍 2. 问了一下实习,开始挖项目 - 说说你的项目架构,整个流程是什么样的 - 如果让你构建一个大数据分析平台,你会选择哪些组件?(主要是数据存储、计算等) - 如果是要求实时处理呢? 3. 问Flink(不会,直接跳过) 4. 为什么选Clickhouse?和其他OLAP数据库相比有啥特点? 5. 八股 - 进程与线程区别 - 说一下Spring
-
休眠保存或更新大数据
问题内容: 我正在尝试使用Hibernate插入或更新大数据。我有一个包含350k对象的列表,当我使用Hibernate时,要花费数小时才能插入所有数据。 我正在使用以下代码进行此操作。我的开发环境是JDK1.4和Oracle数据库。 我正在使用批处理更新,还设置了属性50,但这并没有帮助。 我的对象与另一个对象具有一对一的关系,因此在这种情况下使用StatelessSession可能会出现问题。
-
标准化大熊猫中的数据
问题内容: 假设我有一个熊猫数据框: 我想计算数据框的列均值。 这很简单: 然后按列范围max(col)-min(col)。这又很容易: 现在,对于每个元素,我要减去其列的均值并除以其列的范围。我不确定该怎么做 任何帮助/指针将不胜感激。 问题答案:
-
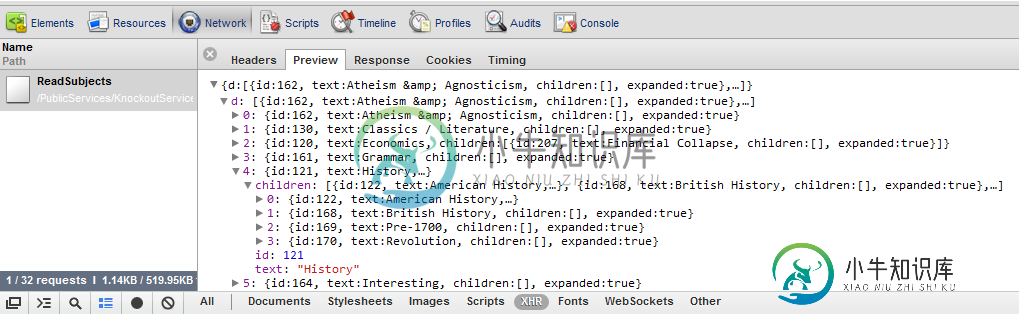 在Chrome中检查大型JSON数据
在Chrome中检查大型JSON数据问题内容: 我的网站上有一个页面,该页面使用jquery AJAX从PHP后端请求JSON数据。我想查看返回给浏览器的JSON,并尝试使用Chrome浏览器的开发人员工具(位于下)进行操作。 问题: 尽管我可以通过在其中选择XHR项来查看JSON数据,但是响应似乎在途中中断了。根据Chrome的说法,此JSON响应大小为300-400KB。我想知道网页是否接收到了完整的JSON响应而没有截断,如果
-
 滴普一面 大数据测试 10.13
滴普一面 大数据测试 10.13群面(轮流技术面,还好) (4候选者+1hr+1负责人+2技术面试官) 1.自我介绍 2.问测试项目(好久没看了,记不清。。。) 3.输入网址到出现页面的过程? 4.DNS 6.什么是合理的测试用例? 7.为什么想要做测试?未来的职业规划? #秋招##测试#
-
使用pandas的“大数据”工作流
几个月来,我在学习熊猫的过程中,一直在努力想出这个问题的答案。我在日常工作中使用SAS,它的核心支持很棒。然而,SAS作为一个软件是可怕的,还有许多其他原因。 有一天我希望用python和pandas取代我对SAS的使用,但我目前缺少一个用于大型数据集的非核心工作流。我说的不是需要分布式网络的“大数据”,而是大到内存放不下但小到硬盘驱动器放不下的文件。 我的第一个想法是使用在磁盘上保存大型数据集,
-
大数据技术栈思维导图