《大数据研发实习》专题
-
大数据与 MapReduce
大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。 对于你来说,可能很想识别那些有购物意愿的用户。 那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。 接下来:我们讲讲 MapRedece 如何来解决这样的问题 MapRedece Hadoop 概述 Had
-
 歌尔大数据
歌尔大数据自我介绍 数仓分层 为什么分层 为什么建模 星型模型,雪花模型 数据库的三范式 范式建模和维度建模的区别,优缺点 如果给你一个任务,一个月完成,你怎么规划 反问 oc
-
 博世大数据
博世大数据一面 英文自我介绍 mr的shuffle zookeeper选举 spark内存管理 hbase中region的拆分 数仓中都有什么表 怎么处理缓慢变化维,拉链表有用过吗 yarn的架构 namenode ha的实现 namenode启动过程中怎么确定哪个是active哪个是standby spark sql用的多吗 手撕 中等leetcoode,合并区间 二面 自我介绍 家哪里的 对博世有什么了
-
 ZDNS大数据岗
ZDNS大数据岗一面:55min 0、自我介绍 1、介绍一下项目,一个离线,一个实时。离线Hive on Spark 实时:Flink + Kafka 2、Spark作业流程、Client,Cluster模式 3、Flink水位线,窗口,FlinkSQL,时间语义和SparkStreaming区别 4、Hive事实表、应用场景 5、实时项目怎么做的,FlinkSQL怎么用的 6、查找算法,排序算法有啥,说说冒泡,
-
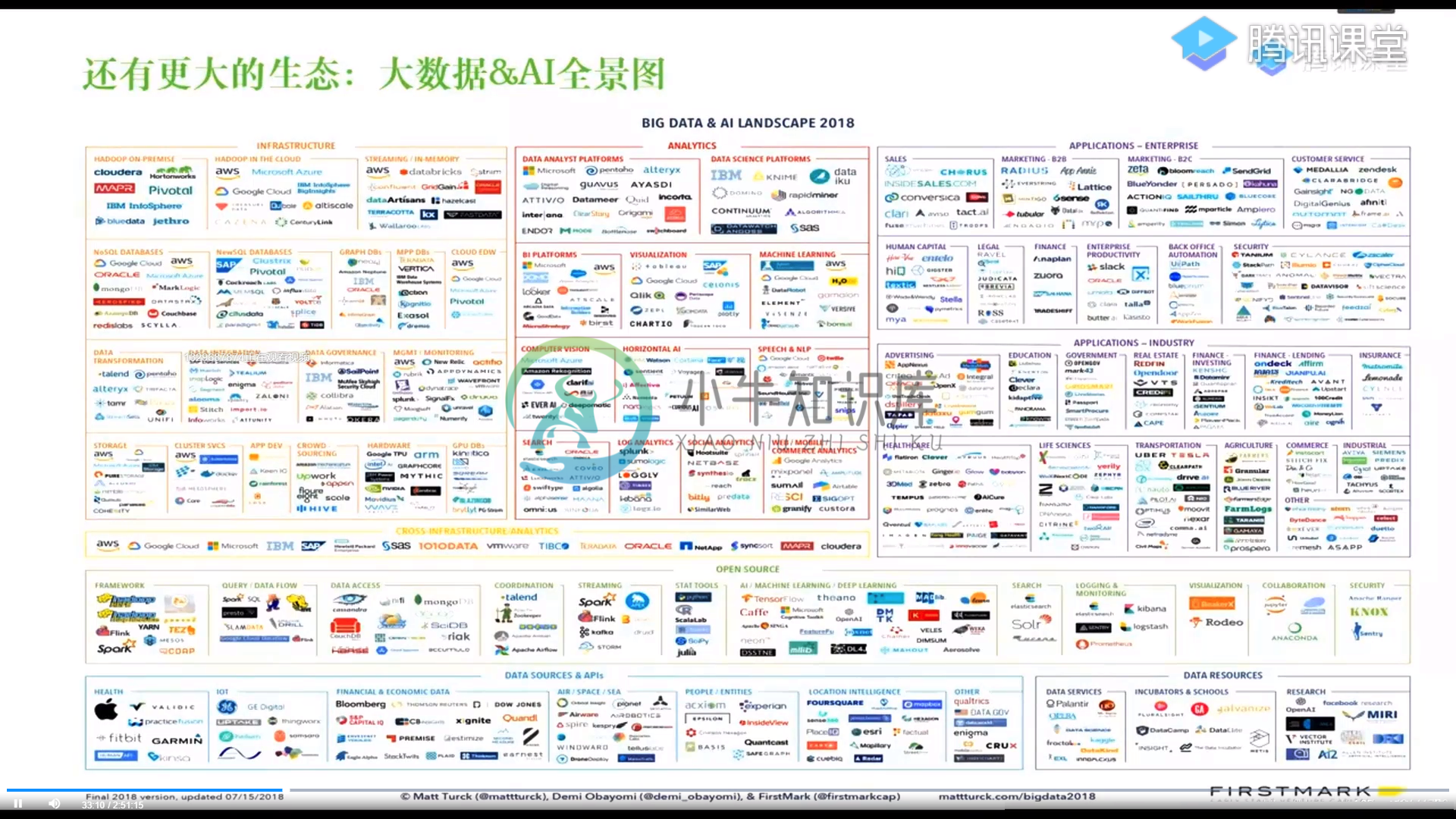 大数据生态
大数据生态fink生态 spark生态 hadoop生态 大数据技术体系与主流技术栈
-
大数据认证
2018年的20个主要的大数据认证 “大数据”一词反映了一个非常实际的增长趋势。到2020年,每个人每秒将产生1.7MB数据。根据调研机构IDC公司的调查,2020年全球数据量将增加到44万亿GB。数以亿计的智能手机和数十亿台物联网(IoT)设备每分钟产生的近300万个Facebook帖子和近300万个视频,每秒约有40,000次谷歌搜索查询。 而大数据认证的数量也在不断增加,尽管不尽相同。这些资
-
 腾讯 - 大数据
腾讯 - 大数据投的 Teg 云架构平台,结果被大数据捞了,一面就挂了。 一面 3.28 自我介绍 介绍冷存储项目 介绍阿里tianchi比赛 线程和进程区别,协程和线程区别? 页表实现 如果访问进程地址空间,在page table 中找不到,会发生什么? 做题 输入一串0和1组成的字符串。重新排列这个字符串使得任何一个字符都不是它前面两个字符的和。比如011就不满足,因为0+1=1。 010,110,111都是
-
 腾讯云智研发公司-后台开发-暑期实习一面
腾讯云智研发公司-后台开发-暑期实习一面#24暑期# 1.自我介绍 2.了解BIO、NIO、AIO的区别吗? 3.接口和抽象类有什么区别? 4.==和equals有什么区别? 5.讲一下什么是线程安全? 6.什么是反射? 7.讲一下jvm的内存模型 8.讲一下GC的基本原理 9.线程池 10.你用redis来干嘛 11.了解MySQL吗 12.讲一下三范式 13.binlog了解吗 14.Hash索引和B+树索引有什么区别? 15.设计
-
 快手-数据开发日常实习-一面
快手-数据开发日常实习-一面1、自我介绍 2、MR的执行过程,用了几次排序,Reduce怎么知道拉取哪些数据 3、RDD的底层实现(Spark用的不多就没问了) 4、项目介绍(没有针对项目进行提问) 5、SQL优化思路,具体讲了关于数据倾斜这块 6、SQL题:包含班级、学生、课程、分数的表,查询每个班每门课前三的学生 7、SQL题:包含user_id和target_id的表,找到互相关注的用户,优化不用join实现 8、SQ
-
 快手-数据开发日常实习-二面
快手-数据开发日常实习-二面1、自我介绍 2、为什么要去北京 3、MR的原理 4、为什么环形缓冲区到80%之后才反向溢写 5、SQL中哪些函数走MR,max走不走 6、select a,count(distinct b) from table group by a,MR的流程 7、SQL优化,如果给你两张表,用户视频表和用户粉丝表,怎么处理数据倾斜 8、SQL题:每个用户都有5门成绩,总计6列。请生成两列,其中1列是用户ID
-
 快手-数据开发日常实习-三面
快手-数据开发日常实习-三面1、自我介绍 2、看我用Java,问我Java程序的执行过程,然后Java怎么跨平台 3、基本数据类型,是否可以相互转换 4、自动装箱自动拆箱,Integer i = 100 是什么过程 5、深拷贝浅拷贝 6、Java是值传递还是引用传递 7、JVM的理解 8、堆是怎么划分的,实际有没有用到有关JVM的地方 9、垃圾清除算法说一下,什么时候FullGC 10、多线程,线程安全,线程通信之类的 11
-
 数据开发实习-蔚来一面面经
数据开发实习-蔚来一面面经岗位:数据开发 体验还不错,面试过程偏向聊天,会问一些新技术,从基础的框架为起点延申出一些问题,面试官也很友好,有些问题答不上来也说没关系 问的相对基础,但但范围较广 (忘记录屏以下为回忆,面试时长1h [蔚来数开一面] 自我介绍 实习介绍(因为前一份实习和数开相关性不是很大,只是写过sql就简单带过了没深挖 kafka相关: kafka的结构 优点,和其他消息队列相比优势在哪 数仓项目(自己做的
-
 面经|滴滴出行-数据开发实习
面经|滴滴出行-数据开发实习1.自我介绍 2.两道SQL 3.mapreduce中map阶段和reduce阶段的task的数量怎么确定 4.了解哪些建模方式,了解维度建模吗,说说他们的区别 5.rdd有哪些shuffle类算子 6.shuffle的本质是什么 7.为什么数仓要分层,分层的意义在哪 8.四个排序的区别 9.spark的提交流程 10.hive中的元数据存储了哪些内容 已过
-
 面经|字节跳动-数据开发实习
面经|字节跳动-数据开发实习一面: 1.自我介绍 2.数仓分层 3.来了新的业务怎么建模 4.选用的什么模型,有什么考量 5.如果现在一张事实表一对多一个维度表,此维度表又一对多一个维度表,怎么设计模型 6.实习过程中用的什么计算引擎 7.spark UI会看哪些内容 8.数据倾斜问题怎么解决 9.介绍一下项目 10.为什么有的指标在下沉的时候要拆开来 11.SQL调优,讲一个具体的例子 12.SQL题:求中位数 二面: 1
-
 美团数据开发实习二面面经
美团数据开发实习二面面经时间:一个小时 数据采集通道的搭建要用到什么能力 离线数仓项目几个人,后端做啥 datax和sqoop的区别(应用场景上的区别) maxwell的底层原理是啥 怎么理解mysql的主库和从库 主从延迟比较严重对数据的影响 数据量级,条数 在日志采集项目中有什么收获 这块是新开发的还是迭代的 现在数据采集已经封装很成熟了,那做数据采集对后面数仓开发有什么优势吗 hive中内部表和外部表怎么转换 多张