《大数据求职》专题
-
 Oracle的CLOB大数据字段类型操作方法
Oracle的CLOB大数据字段类型操作方法本文向大家介绍Oracle的CLOB大数据字段类型操作方法,包括了Oracle的CLOB大数据字段类型操作方法的使用技巧和注意事项,需要的朋友参考一下 一、Oracle中的varchar2类型 我们在Oracle数据库存储的字符数据一般是用VARCHAR2。VARCHAR2既分PL/SQL Data Types中的变量类型,也分Oracle Database中的字段类型,不同场景的最大长度不同。
-
如何在MAMP上导出/导入大型数据库
问题内容: 如何在MAMP上导出/导入大型数据库?使用PHPMyAdmin无法正常工作。 问题答案: 应该通过如下所示的终端来完成。 在终端中,使用以下命令导航到MAMP的文件夹 使用此命令导出文件。EG将是 行应该出现在说。在这里输入MySQL密码。请记住,这些字母不会出现,但是它们在那里。 如果需要导入,请使用BigDump,这是一个MySQL Dump Importer。
-
一种基于scikit-learn的大数据集热编码
我有一个大数据集,我计划对其进行逻辑回归。它有很多分类变量,每一个都有成千上万的特征,我计划在这些特征上使用一个热编码。我将需要处理小批量的数据。我的问题是如何确保一个热编码在第一次运行时看到每个分类变量的所有功能?
-
tf.data.数据集如何动态传递tf.io.FixedLenFeature的大小
我们有tfrecord文件,其中每个tfrecord文件都包含一个示例,但其中的功能包含一个值列表。我们正在使用以以下方式: 我们希望查找给定文件路径的行数,而不是对使用固定常量。 关于如何实现这一点有什么想法吗? 我们试着用这样的东西 但这失败了,因为tf。直到需要时,数据才会急切地评估文件路径(即,它仍然是一个tf.Tensor)
-
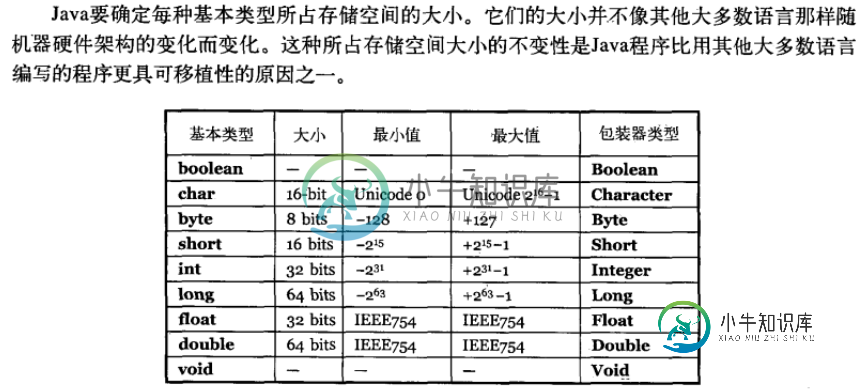 Java 的8种基本数据类型 及其大小?
Java 的8种基本数据类型 及其大小?本文向大家介绍Java 的8种基本数据类型 及其大小?相关面试题,主要包含被问及Java 的8种基本数据类型 及其大小?时的应答技巧和注意事项,需要的朋友参考一下
-
Spark如何处理大于集群内存的数据
如果我只有一个内存为25 GB的执行器,并且如果它一次只能运行一个任务,那么是否可以处理(转换和操作)1 TB的数据?如果可以,那么将如何读取它以及中间数据将存储在哪里? 同样对于相同的场景,如果hadoop文件有300个输入拆分,那么RDD中会有300个分区,那么在这种情况下这些分区会在哪里?它会只保留在hadoop磁盘上并且我的单个任务会运行300次吗?
-
Cloud SQL中大容量加载数据的ETL方法
我需要将数据ETL到云SQL实例中。这些数据来自API调用。目前,我正在Kubernetes中用Cronjobs运行一个自定义Java ETL代码,它请求收集这些数据并将其加载到Cloud SQL上。这个问题与管理ETL代码和监视ETL作业有关。当合并更多ETL进程时,当前的解决方案可能无法很好地扩展。在这种情况下,我需要使用ETL工具。 我的Cloud SQL实例包含两种类型的表:公共事务性表和
-
向Cassandra写入大火花数据帧-性能调整
我在Spark 2.1.0/Cassandra 3.10集群(4台机器*12个内核*256个RAM*2个SSD)上工作,很长一段时间以来,我一直在努力使用Spark Cassandra connector 2.0.1向Cassandra写入特定的大数据帧。 这是我的表的模式 用作主键的散列是256位;列表字段包含多达1MB的某种结构化类型的数据。总共,我需要写几亿行。 目前,我正在使用以下写入方法
-
使用熊猫的“大数据”工作流[已关闭]
在学习熊猫的过程中,我已经尝试了好几个月来找出这个问题的答案。我在日常工作中使用SAS,这是非常好的,因为它提供了非核心支持。然而,SAS作为一个软件是可怕的,原因还有很多。 有一天,我希望用python和熊猫取代SAS,但我目前缺乏大型数据集的核心外工作流。我说的不是需要分布式网络的“大数据”,而是文件太大,无法放入内存,但又小到足以放入硬盘。 我的第一个想法是使用在磁盘上保存大型数据集,只将我
-
使用Sqoop将大型机数据摄取到Hadoop中
我发现SQOOP1.4.6可以连接到大型机,它可以从大型机PDS中提取数据,并将其放入hdfs/hive/hbase或accolumo中。 我想知道它是支持打包的十进制数据类型还是只支持简单的数据类型?有人能帮我了解一下SQOOP1.4.6支持什么大型机文件格式吗? 提前致谢 参考https://sqoop.apache.org/docs/1.4.6/sqoopuserguide.html
-
分析Protobuf与JSON并遇到数据大小问题
在Java,我的任务是查看JSON格式与Protobuf格式相同的数据的数据大小和处理速度(创建数据的速度)。 对于JSON,我使用了jackson,创建了一个类,其中包含一个字段,称为subscriptionlist。每个将对应于一个订阅。我从一个文件中读取,每一行都是“”字段分隔的,有523个字段。我遍历每个字段,为键指定订阅列名,为值指定列值。我遍历每一行以创建所有1000个订阅,将它们放入
-
Cucumber:场景大纲-在运行时访问数据表
在我们的cucumber特性文件中,我们使用了场景大纲,在运行脚本之前,我们需要在运行时填充数据。 基于数据文件中传递的城市路线,我们使用一个API创建PNR,该API返回给我一个实际的PNR。创建的PNR值需要存储在场景数据表中。 如果我们有场景,我们可以使用DataTable函数访问函数内部的值。我们有任何类与场景大纲数据表交互吗 例如。 请让我知道如果现有的类或替代方案来解决这个问题。
-
处理大型数据对象,应该释放CLOB吗?
我使用Oracle数据库和驱动程序,我使用从ResultSet获取Clob,然后在方法中将其转换为String:
-
不同大小数据帧的合并和重复值
我需要合并两个不同大小的数据帧。较大的一个()有一列有几个重复的值(),较短的一个()有列,但其值不重复。df2还有一个ID列。我需要在中使用中的ID的新列,根据中的重复值重复。下面的例子可能会让它更清楚。 .
-
 2022/08/22 宁德时代大数据开发(已OC)
2022/08/22 宁德时代大数据开发(已OC)2022/08/13 一面 时长15min 感觉啥也没问 自我介绍 项目主要是大数据相关,你对算法方面了解多少 实习在做什么 想做偏算法还是偏数据的工作 如果其他部门提的取数需求做不了 你会怎么做 面试官介绍他们的电池时序数据 反问:业务部门多少人,入职后做的工作偏算法还是数据 ------------------------------------------- 2022/08/13 面试刚结