《大数据求职》专题
-
大数据
Kubernetes community中已经有了一个Big data SIG,大家可以通过这个SIG了解kubernetes结合大数据的应用。 在Swarm、Mesos、kubernetes这三种流行的容器编排调度架构中,Mesos对于大数据应用支持是最好的,spark原生就是运行在mesos上的,当然也可以容器化运行在kubernetes上。当前在kubernetes上运行大数据应用主要是sp
-
Rails数据表ajax json 414请求URI太大
因此,我尝试了Railscasts教程,以及ajax-datatables-rails gem的教程。我正在从数据库创建客户端列表--而不是用户。我相信我已经将其缩小到这样一个事实,即当通过Datatables使用方法时,我收到一个带有“Request-URI太大”的414。当我使用方法时,我只是获得除之外的所有属性的空值,这是有道理的,因为POST json用于创建客户端。任何帮助都非常感谢!
-
数据请求
本文介绍如何在 Rax 中创建网络请求。大多数前端应用都需要通过 HTTP 协议或 MTOP 协议与后端服务器通讯,例如你可能需要给某个接口发起 POST 请求以提交用户数据,或者可能需要从某个服务器上获取一些静态内容。 HTTP 请求 request 模块已支持多端发送请求,要发起简单的 GET 请求的话,只需简单地将网址作为 url 参数即可。 import request from 'uni
-
数据请求
在 Rax 的 Web 应用中,尤其是 SSR 应用中,我们推荐在页面入口组件中定义 getInitialProps 属性,来处理数据请求的工作。这是因为: 一旦代码运行在 Server 端,无法像在 Client 那样,异步获取数据后,再通过 setState 来更新页面 UI。渲染引擎需要预先获取数据,然后执行 render 操作。因此,组件的数据请求必须是可被独立调用的。 基于 getIni
-
JavaScript对大整数求和
问题内容: 在JavaScript中,我想使用以下方法创建大型布尔数组(54个元素)的二进制哈希: 简而言之:它创建了最小的整数来存储布尔数组。现在我的问题是javascript显然使用 浮点数 作为默认值。我必须创建的最大数量是2 ^ 54-1,但是一旦javascript达到2 ^ 53,它就会开始做一些奇怪的事情: 有没有办法在JavaScript中使用整数而不是浮点数?还是大整数求和? 问
-
Fetch 数据请求
Fetch 是一个支持下拉刷新及滚动加载的组件。因为这两个操作最终目的都是为了做数据请求,所以取名“Fetch”。 使用 <template> <div class="fetch-demo" style="position:absolute;top:0;left:0;bottom:0;right:0;"> <Fetch @fetch="handleFetch">
-
FIELDDATA数据太大
问题内容: 我打开kibana并进行搜索,但出现碎片失败的错误。我查看了elasticsearch.log文件,然后看到此错误: 有什么办法可以增加593.9mb的限制? 问题答案: 您可以尝试在配置文件中将fielddata断路器的限制提高到75%(默认值为60%),然后重新启动集群: 或者,如果您不想重启群集,则可以使用以下方法动态更改设置: 试试看。
-
大数据与 MapReduce
大数据 概述 大数据: 收集到的数据已经远远超出了我们的处理能力。 大数据 场景 假如你为一家网络购物商店工作,很多用户访问该网站,其中有些人会购买商品,有些人则随意浏览后就离开。 对于你来说,可能很想识别那些有购物意愿的用户。 那么问题就来了,数据集可能会非常大,在单机上训练要运行好几天。 接下来:我们讲讲 MapRedece 如何来解决这样的问题 MapRedece Hadoop 概述 Had
-
 歌尔大数据
歌尔大数据自我介绍 数仓分层 为什么分层 为什么建模 星型模型,雪花模型 数据库的三范式 范式建模和维度建模的区别,优缺点 如果给你一个任务,一个月完成,你怎么规划 反问 oc
-
 博世大数据
博世大数据一面 英文自我介绍 mr的shuffle zookeeper选举 spark内存管理 hbase中region的拆分 数仓中都有什么表 怎么处理缓慢变化维,拉链表有用过吗 yarn的架构 namenode ha的实现 namenode启动过程中怎么确定哪个是active哪个是standby spark sql用的多吗 手撕 中等leetcoode,合并区间 二面 自我介绍 家哪里的 对博世有什么了
-
 ZDNS大数据岗
ZDNS大数据岗一面:55min 0、自我介绍 1、介绍一下项目,一个离线,一个实时。离线Hive on Spark 实时:Flink + Kafka 2、Spark作业流程、Client,Cluster模式 3、Flink水位线,窗口,FlinkSQL,时间语义和SparkStreaming区别 4、Hive事实表、应用场景 5、实时项目怎么做的,FlinkSQL怎么用的 6、查找算法,排序算法有啥,说说冒泡,
-
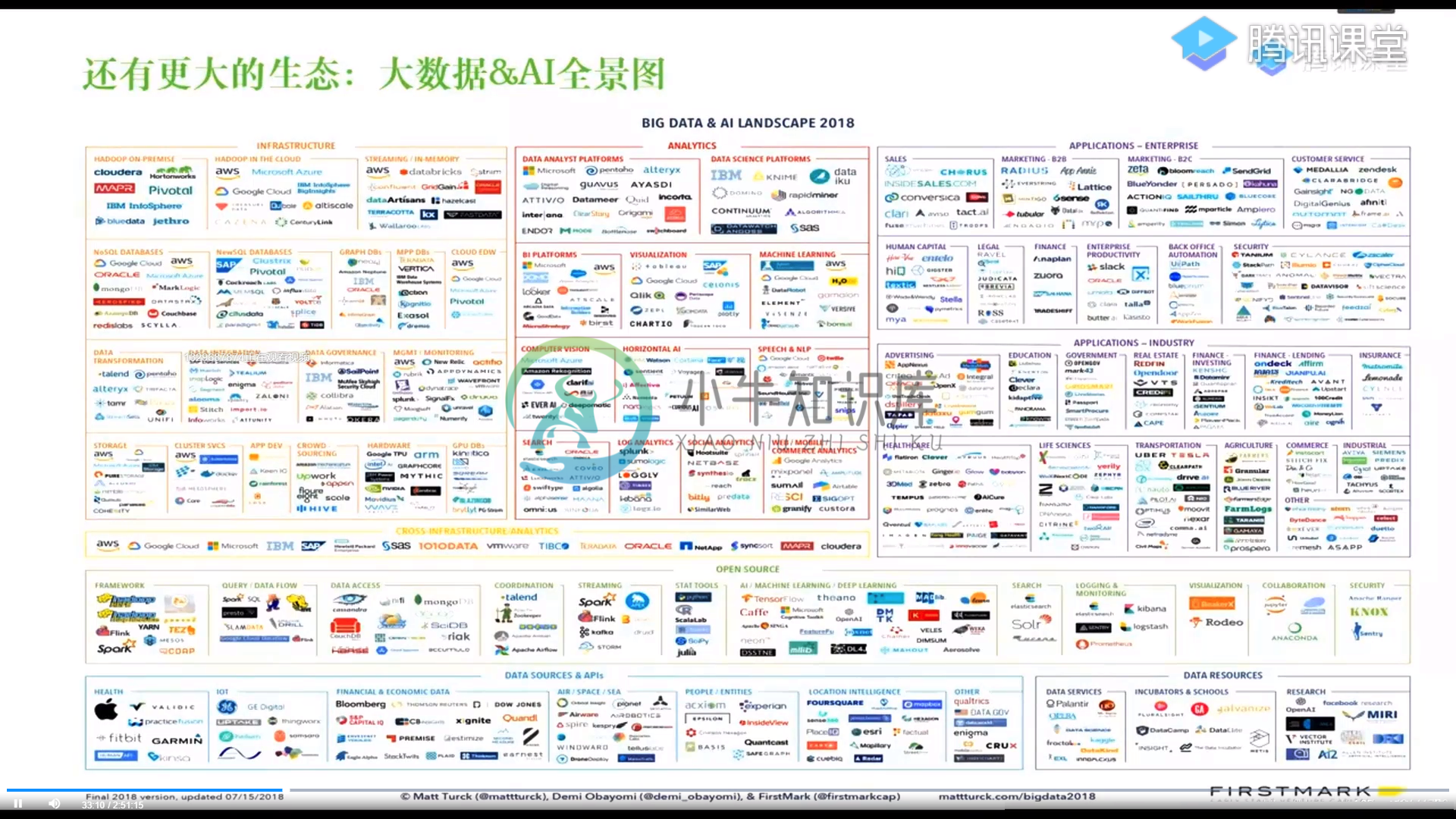 大数据生态
大数据生态fink生态 spark生态 hadoop生态 大数据技术体系与主流技术栈
-
大数据认证
2018年的20个主要的大数据认证 “大数据”一词反映了一个非常实际的增长趋势。到2020年,每个人每秒将产生1.7MB数据。根据调研机构IDC公司的调查,2020年全球数据量将增加到44万亿GB。数以亿计的智能手机和数十亿台物联网(IoT)设备每分钟产生的近300万个Facebook帖子和近300万个视频,每秒约有40,000次谷歌搜索查询。 而大数据认证的数量也在不断增加,尽管不尽相同。这些资
-
 腾讯 - 大数据
腾讯 - 大数据投的 Teg 云架构平台,结果被大数据捞了,一面就挂了。 一面 3.28 自我介绍 介绍冷存储项目 介绍阿里tianchi比赛 线程和进程区别,协程和线程区别? 页表实现 如果访问进程地址空间,在page table 中找不到,会发生什么? 做题 输入一串0和1组成的字符串。重新排列这个字符串使得任何一个字符都不是它前面两个字符的和。比如011就不满足,因为0+1=1。 010,110,111都是
-
3. 请求数据获取 - 3.2 POST请求数据获取
原理 对于POST请求的处理,koa2没有封装获取参数的方法,需要通过解析上下文context中的原生node.js请求对象req,将POST表单数据解析成query string(例如:a=1&b=2&c=3),再将query string 解析成JSON格式(例如:{"a":"1", "b":"2", "c":"3"}) 注意:ctx.request是context经过封装的请求对象,ctx.