《数据分析工程师》专题
-
Android编程ViewPager回弹效果实例分析
本文向大家介绍Android编程ViewPager回弹效果实例分析,包括了Android编程ViewPager回弹效果实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android编程ViewPager回弹效果。分享给大家供大家参考,具体如下: 其实在我们很多应用中都看到当ViewPager滑到第一页或者最后一页的时候,如果再滑动的时候,就会有一个缓冲的过程,也就是回弹效果。之前在
-
ASP.net全局程序文件Global.asax用法分析
本文向大家介绍ASP.net全局程序文件Global.asax用法分析,包括了ASP.net全局程序文件Global.asax用法分析的使用技巧和注意事项,需要的朋友参考一下 本文详细讲述了ASP.net全局程序文件Global.asax用法,分享给大家供大家参考。具体分析如下: 一般来说ASP.NET应用程序只能有一个Global.asax文件,该文件支持许多项。具体分析如下: •Applica
-
MySQL 声明变量及存储过程分析
本文向大家介绍MySQL 声明变量及存储过程分析,包括了MySQL 声明变量及存储过程分析的使用技巧和注意事项,需要的朋友参考一下 声明变量 设置全局变量 set @a='一个新变量'; 在函数和储存过程中使用的变量declear declear a int unsigned default 1; 这种变量需要设置变量类型 而且只存在在 begin..end 这段之内 select .. into
-
在Eclipse中分析Java应用程序?(插件)
问题内容: 我正在寻找Eclipse的 Java应用程序中的瓶颈。我认为这可能有用: http://www.eclipse.org/projects/project_summary.php?projectid=tptp.performance 还有其他好用的插件吗? 编辑 OK,不一定必须是Eclipse插件。但这会很好。而且,我对速度最感兴趣。 问题答案: 如果可以,请在Sun Java 6 J
-
PHP实现的方程求解示例分析
本文向大家介绍PHP实现的方程求解示例分析,包括了PHP实现的方程求解示例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现的方程求解。分享给大家供大家参考,具体如下: 一、需求 1. 给出一个平均值X,反过来求出来,得到这个平均值X的三个数X1 ,X2, X3,最大值与最小值的差值要小于0.4(X1-X3都是保留1位小数的数) 2. 这三个数X1, X2, X3代表了三组数。
-
如何保存JProfiler分析Java进程杀死
当评测应用程序的java进程终止时(例如:kill-9 processId),jprofiler关闭评测并说: 网络连接已断开。JVM可能意外终止。如果JVM崩溃,请尝试以下策略: 减少分析应用程序的-Xmx值 更改分析设置(例如从检测到采样)O不再显示此对话框 进程终止时有什么方法可以立即保存吗 JProfiler版本:11.1.4 编辑:被杀死的进程不是jprofiler的进程,而是正在分析的
-
JProfiler-无法通过隧道分析远程jboss
我无法配置我的远程服务器。这个远程服务器必须通过全局服务器连接,所以我必须使用隧道连接到我的服务器。每当我连接到远程服务器时,jprofiler都会显示以下消息 另一个应用程序正在端口12345上侦听。请检查您的端口配置 最初我可以通过相同的配置连接到这个jboss进行评测,有人能告诉我出现上述情况的原因吗?
-
内存泄漏的java堆和线程分析
我的WebLogic服务器配置了16GB的堆空间,但当大多数用户开始工作时,90%的堆空间在生产使用1小时内就被使用了。我观察到每当这种情况发生时,都有几条线卡住了。 我已经检查了线程转储,没有“等待锁定”对象线程,线程类似于如下所示,线程没有明显的原因被卡住。
-
Azure应用程序洞察或日志分析
Azure应用程序洞察或日志分析的用例是什么? 我正在使用APIM和Azure函数,并希望对请求执行日志记录。应用洞察和日志分析哪一个最合适? https://docs.microsoft.com/en-gb/Azure/Azure-monitor/overview 更新 特别是关于APIM使用的Azure应用程序洞察与日志分析的任何信息?
-
番外篇:Tornado 的多进程管理分析
Tornado的多进程管理我们可以参看process.py这个文件。 在编写多进程的时候我们一般都用python自带的multiprocessing,使用方法和threading基本一致,只需要继承里面的Process类以后就可以编写多进程程序了,这次我们看看tornado是如何实现他的multiprocessing,可以说实现的功能不多,但是更加简单高效。 我们只看fork_process里面的
-
基于工作者、核和数据流大小确定最佳火花分区数
Spark-land中有几个类似但不同的概念,围绕着如何将工作分配到不同的节点并并发执行。具体有: Spark驱动程序节点() Spark群集可用的辅助节点数() Spark executors的数量() 所有工作人员/执行人员同时操作的DataFrame() ()中的行数 () ,最后是每个工作节点上可用的CPU核数() 我相信所有的Spark集群都只有一个Spark驱动程序,然后是0+个工作节
-
Azure数据工厂-按日期筛选Mongodb源数据集
这种情况非常简单,如ADFv2文档和示例中所述,我已经创建了一个复制管道来从MongoDB集合中获取数据,并将其写入AzureSQL数据库。 已成功传输完整采集数据,并且所有映射都已正确设置。当我试图过滤源数据集以仅从MongoDB获取最后n天时,问题就开始了。我尝试了几个查询,并与MongoDB Compass进行了交叉检查,以确定它们是否真的在执行Mongo-side,事实就是这样。归结起来就
-
拆分用于分类问题的数据集的正确程序是什么?
问题内容: 我是机器学习和深度学习的新手。我想澄清我与训练之前有关的疑问 我有一个size的数据集,其中, 属于 属于 我想使用LSTM执行分类(因为序列数据) 由于各类没有相等的分布集,我如何拆分我的数据集进行训练? 选项1 :考虑整个数据,对其进行洗牌,train_test_split,然后进行培训。 选项2: 均等地分割两个班级数据集 ,对其进行洗牌,train_test_split,然后进
-
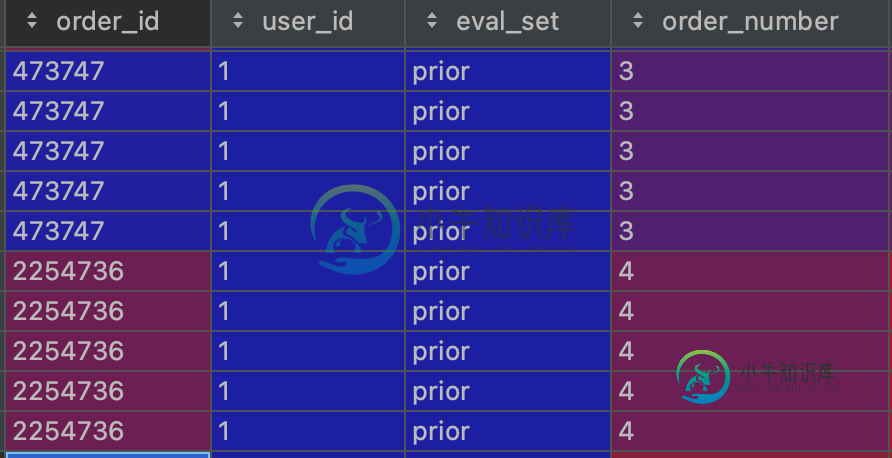 无环路分离数据帧
无环路分离数据帧我有一个包括客户篮子的数据集。我想用一个来分割每个用户篮。因此,我有一个列表,其中我应该使用一个循环来获得一个,以便在pandas矢量化中使用它,如下所示: 我使用函数而不是,但它确实很慢。 根据我的orders列表,它包括百万个元素,我应该使用orders列表的元素来获取用户的篮子。 实际上,我想通过来分割每个用户的篮子,而要这样做,我需要对大小为4000000的orders列表进行迭代,所以这
-
第三部分:衍生数据
在本书的第一部分和第二部分中,我们自底向上地把所有关于分布式数据库的主要考量都过了一遍。从数据在磁盘上的布局,一直到出现故障时分布式系统一致性的局限。但所有的讨论都假定了应用中只用了一种数据库。 现实世界中的数据系统往往更为复杂。大型应用程序经常需要以多种方式访问和处理数据,没有一个数据库可以同时满足所有这些不同的需求。因此应用程序通常组合使用多种组件:数据存储,索引,缓存,分析系统,等等,并实现