《阿里云分布式块存储》专题
-
分布式事务
背景 数据库事务需要满足 ACID(原子性、一致性、隔离性、持久性)四个特性。 原子性(Atomicity)指事务作为整体来执行,要么全部执行,要么全不执行。 一致性(Consistency)指事务应确保数据从一个一致的状态转变为另一个一致的状态。 隔离性(Isolation)指多个事务并发执行时,一个事务的执行不应影响其他事务的执行。 持久性(Durability)指已提交的事务修改数据会被持久
-
分布式主键
实现动机 传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。 数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。 目
-
分布式跟踪
当我将单体应用拆成多个微服务之后,如何监控服务之间的依赖关系和调用链,以判断应用在哪个服务环节出了问题,哪些地方可以优化?这就需要用到分布式追踪(Distributed Tracing)。 CNCF 提出了分布式追踪的标准 OpenTracing,它提供用厂商中立的 API,并提供 Go、Java、JavaScript、Python、Ruby、PHP、Objective-C、C++ 和 C# 这九
-
分布式训练
相关概念 客户端 (Client):客户端是一个用于建立 TensorFlow 计算图并创立与集群进行交互的会话层 tensorflow::Session 的程序。一般客户端是通过 python 或 C++ 实现的。一个独立的客户端进程可以同时与多个 TensorFlow 的服务端相连 (上面的计算流程一节),同时一个独立的服务端也可以与多个客户端相连。 集群 (Cluster) : 一个 Ten
-
分布式容器
在分布式 Web 容器中,HttpSession 实例被限到特定的 JVM 服务会话请求,且 ServletContext 对象被限定到 Web 容器所在的 JVM。分布式容器不需要传播 Servlet 上下文事件或 HttpSession 事件到其他 JVM。监听器类实例被限定到每个 JVM 的每个部署描述符声明一个。
-
分布式应用
定义 在一个包含了若干Erlang节点的分布式系统中,可能需要以分布的方法来控制应用。如果某个节点——上面运行了某个应用——挂了,应用要在另一个节点上被重启。 这样一个应用被称之为一个分布式应用。注意是对于应用的控制是分布的,所有应用当然都可以是分布——比如,使用其它节点上的服务。 因为一个分布式应用可能会在节点之间移动,所以必须有某种寻址机制来确保它可以被其他应用找到,无论它当前运行于哪个节点上
-
分布式安装
Open-Falcon是一个比较大的分布式系统,有十几个组件。按照功能,这十几个组件可以划分为 基础组件、作图链路组件和报警链路组件,其安装部署的架构如下图所示, 在单台机器上快速安装 请直接参考quick_install Docker化的Open-Falcon安装 参考: https://github.com/open-falcon/falcon-plus/blob/master/docker/
-
分布式进程
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封
-
分布式进程
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。 Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封
-
分布式事务
单文档原子性可满足大多数业务需求 在 MongoDB 中,对单个文档的操作是原子操作。 由于 MongoDB 文档数据模型,一个文档中通过嵌入式的文档和数组来表示传统关系数据库模型中的一对一、一对多关系,而不是通过文档之间的复杂关系来描述业务需求中的一对一、一对多关系。 所以单文档原子性可以满足实际生产中大多数关于事务的需求。 对于需要对多个文档(在单个或多个集合中)进行原子读写的情况,Mongo
-
Google云存储多部分上传,最后一个块失败(503)
所以我尝试使用多部分上传将文件上传到谷歌云存储,方法是事先将文件分成块,然后通过http put请求发送。 问题是,当我上传文件的最后一个块时,我得到的是503错误,而不是200完整的消息。 为了简单起见,我使用的是驱动器中的jpeg图像,将其转换为blob和bytes: 根据文档,我首先请求一个可重复的上传URI。 这个很管用。 我开始将文件字节解析为256x1024字节块,并使用上传URL通过
-
使用Hadoop分布式缓存时出现FileNotFoundException
问题内容: 这次有人应该请小我努力使用分布式cahe运行我的代码。我已经在hdfs上保存了文件,但是当我运行以下代码时: 解决了很多问题,任何人都可以告诉我为什么我收到此错误: 问题答案: 问题在于您使用的文件名“〜/ ayush / output / part-00000”依赖于Unix shell(sh,bash,ksh)代字扩展名,将“〜”替换为主目录的路径名。 Java(以及C,C ++和
-
spring boot micro services中的分布式redis缓存
我有两个微服务。Item micro服务将数据填充到redis缓存中。这是成功的,我也能够在同一个微服务中检索数据。另一个微服务是订单服务。为了获得服务,我需要从redis缓存中获取项目服务数据,因为我需要使用分布式缓存。然而,我无法从redis缓存中访问缓存数据以获得服务。 这是我的实现代码 物品服务 重新配置。JAVA 重新发行。JAVA 订单服务 重新配置。JAVA 我在订单服务中创建了It
-
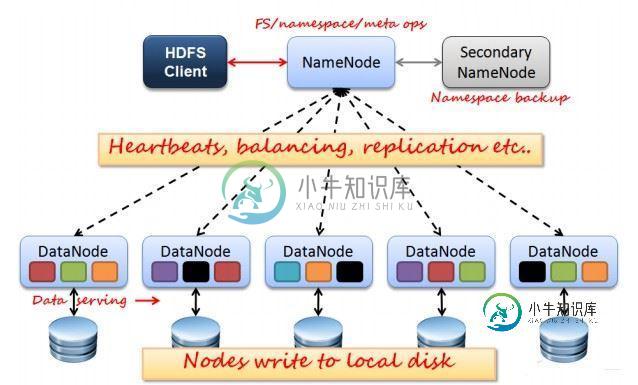 Hadoop 分布式存储系统 HDFS的实例详解
Hadoop 分布式存储系统 HDFS的实例详解本文向大家介绍Hadoop 分布式存储系统 HDFS的实例详解,包括了Hadoop 分布式存储系统 HDFS的实例详解的使用技巧和注意事项,需要的朋友参考一下 HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统。 一、HDFS的优缺点 1.HDFS优点: a.高容错性 .数据保存多个副本 .数据丢的失后自动恢复
-
使用 Azure cosmos 和 blob 存储的分布式事务
我们计划在单个事务中上传blob中的一些文件和Cosmos数据库中的数据 是否可以在Azure Cosmos DB和Azure blob存储之间实现分布式事务?如果任何操作失败,则还应恢复其他操作。 如果不可能,那么是否有任何理想的方法可以通过任何Azure组件实现此功能?