《数据仓库与数据分析实习》专题
-
Cassandra容器数据库NoNodeAvailableException
我使用在docker容器上运行的Cassandra docker映像和Spring Boot服务,并使用Datastax Java驱动程序。 我可以连接Cassandra,也可以查看日志,下面是docker compose文件, 我的密钥空间查询是, 以及使用, Cassandra已经启动并运行了,并且验证了它, 问题是在一开始, 我使用了来创建键空间,得到了以下错误: 然后配置和
-
房间数据库迁移
并且我发现了基于数据库版本4的可能场景的迁移varargs。 我的问题是,假设我使用的是db v1的Room,当我的应用程序到达db v10时,我将不得不编写多少迁移方法? 在sqlite中,我们在中获得已安装应用程序的当前db版本,我们只需通过开关大小写而不使用break语句,以便满足所有db升级。
-
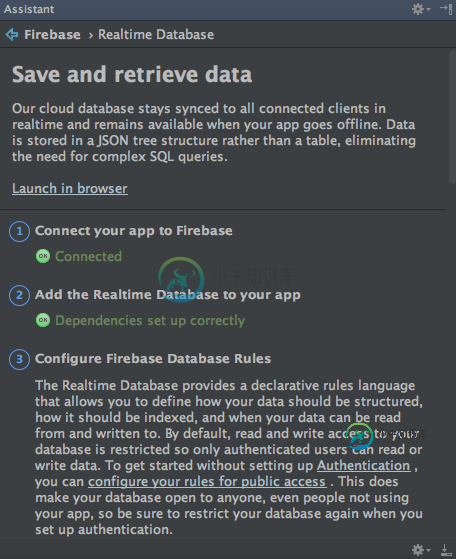 Firebase数据库getInstance崩溃
Firebase数据库getInstance崩溃我见过许多问题,询问为什么一个应用程序会崩溃,错误日志如下:未能获得FirebaseDatabase实例:FirebaseApp对象在其FirebaseOptions对象中没有DatabaseURL。 我通过Android Studio配置了firebase。 我仍然会遇到错误。 我相信google-services.json文件没有错误,因为它是由Android Studio自动创建的。 任何帮
-
数据库时区问题
尝试与数据库MySQL建立连接时出现此错误 与MySQL的连接是这样完成的:
-
房间数据库查询
我是新来的和我试图我的得到一个从它。我试图这样做的它与这是id但问题是我不知道如何返回目标从。 这就是<代码>刀 这是Repository类
-
 度小满数据库岗
度小满数据库岗1、自我介绍 2、项目详细介绍 3、回滚和崩溃恢复是怎么做的? 4、追问具体是怎么恢复,未提交的事务和已提交的事务怎么恢复? 5、语法解析器是怎么实现的?谓词比较 6、tcp三次握手、四次挥手 7、tcp是怎么实现可靠性的 8、http状态码的含义 9、怎么加行锁?具体命令?提示where 条件,我答了等值和非等值锁的变化;如果让你实现行锁你会怎么做? 10、关系型数据库和非关系型数据库的区别 1
-
同步数据库结构
同步能够部分智能的根据结构体的变动检测表结构的变动,并自动同步。目前有两个实现: Sync Sync将进行如下的同步操作: * 自动检测和创建表,这个检测是根据表的名字 * 自动检测和新增表中的字段,这个检测是根据字段名 * 自动检测和创建索引和唯一索引,这个检测是根据索引的一个或多个字段名,而不根据索引名称 调用方法如下: err := engine.Sync(new(User), ne
-
获取数据库信息
DBMetas() xorm支持获取表结构信息,通过调用 engine.DBMetas() 可以获取到数据库中所有的表,字段,索引的信息。 TableInfo() 根据传入的结构体指针及其对应的Tag,提取出模型对应的表结构信息。这里不是数据库当前的表结构信息,而是我们通过struct建模时希望数据库的表的结构信息
-
数据库系统 - 索引
数据库创建索引能够大大提高系统的性能。 第一,通过创建唯一性的索引,可以保证数据库表中每一行数据的唯一性。 第二,可以大大加快数据的检索速度,这也使创建索引的最主要的原因。 第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 第四,在使用分组和排序子句进行数据检索时,同样可以显著的减少查询中查询中分组和排序的时间。 第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,
-
1.7.1.2 关系型数据库
Discovering models from relational databases(关系型数据库连接) 简介 基础步骤 discovery 案例 添加 discovery 方法 简介 Loopback可以很方便地从现有的关系型数据库创建model, 这个过程被称为 discovery ,由以下连接器的支持. MySQL 连接器 PostgreSQL 连接器 Oracle 连接器 SQL Se
-
ItemReaders和ItemWriters - 数据库Database
和大部分企业应用一样,数据库也是批处理系统存储数据的核心机制。 但批处理与其他应用的不同之处在于,批处理系统一般都运行于大规模数据集基础上。 如果一条SQL语句返回100万行, 则结果集可能全部存放在内存中m直到所有行全部读完。 Spring Batch提供了两种类型的解决方案来处理这个问题: 游标(Cursor) 和 可分页的数据库ItemReaders.
-
从远程数据库 pull
Windows 我们把在上一页面中从“tutorial2”推送到远程数据库的内容拉取到数据库目录“tutorial”吧。 用tutorial进行的操作 右击tutorial目录,然后从右击菜单中选择’拉取‘,即可执行pull操作。 用tutorial进行的操作 在以下画面点击“确定”。 用tutorial进行的操作 pull操作将在以下画面开始进行。完成pull后请点击“关闭”以退出画面。 用tu
-
克隆远程数据库
假设您是其中一位团队成员,把现有的远程数据库克隆到另一个目录( tutorial2 )。 Windows 请双击桌面上的任意地方,然后从右击菜单中选择“Git克隆”。 点击“Clone Repository" 按钮,再输入要克隆的远程数据库的URL和要保存的本地数据库的目录,然后点击“确定”。 这样就把上一页面中创建的数据库,以“tutorial2”的名称进行了克隆。 克隆将在以下画面开始进行。完
-
push 到远程数据库
Windows 请右击“tutorial”目录,然后选择“推送”。 在以下画面点击‘管理’。 将出现以下画面,在"远端"输入"origin",在"URL"输入上一页中生成的远程数据库的URL,然后点击"添加/保存"。这样,"origin"将被添加到远程列表,然后点击"OK"。 Tips 执行推送或者拉取的时候,如果省略了远程数据库的名称,则默认使用名为”origin“的远程数据库。因此一般都会把远
-
从远程数据库 pull
若是共享的远程数据库由多人同时作业,那么作业完毕后所有人都要把修改推送到远程数据库。然后,自己的本地数据库也需要更新其他人推送的变更内容。 Pull 进行拉取(Pull) 操作就可以把远程数据库的内容更新到本地数据库。 进行拉取(Pull) 操作,就是从远程数据库下载最近的变更日志,并覆盖自己本地数据库的相关内容。 接下来就是新手教程哦!学习一下怎样使用贝格乐远程数据库来共享数据库吧!