《数据分析面试》专题
-
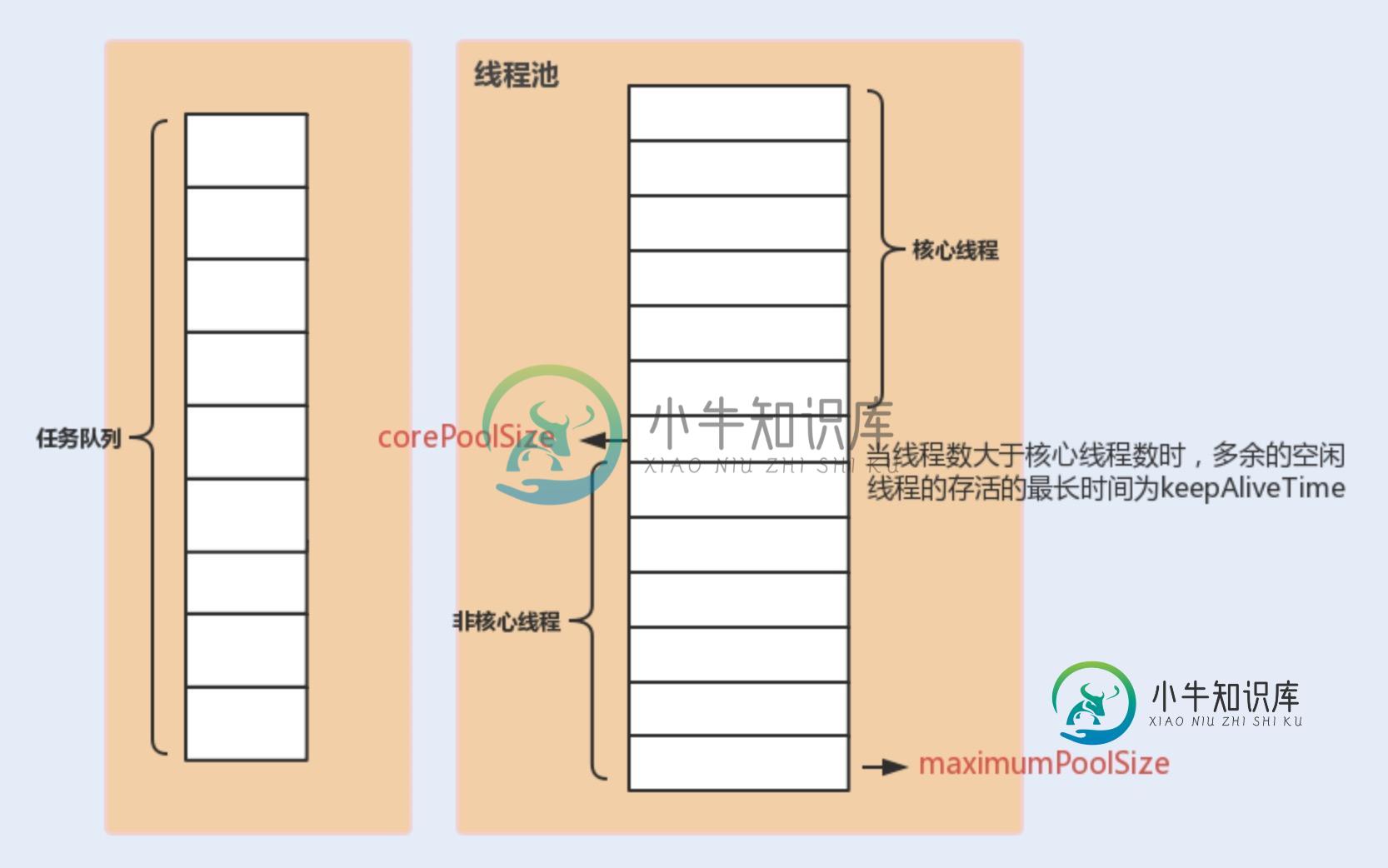 ThreadPoolExecutor 构造函数重要参数分析?
ThreadPoolExecutor 构造函数重要参数分析?本文向大家介绍ThreadPoolExecutor 构造函数重要参数分析?相关面试题,主要包含被问及ThreadPoolExecutor 构造函数重要参数分析?时的应答技巧和注意事项,需要的朋友参考一下 : : 核心线程数线程数定义了最小可以同时运行的线程数量。 : 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。 : 当新任务来的时候会先判断当前运行的线程数量是否
-
 美团商业分析一面凉经
美团商业分析一面凉经八月份面试 笔试后第三天收到了一面通知 查了下面经准备了很多abtest sql 业务情景相关 费米估计等问题 首先自我介绍 接着面试官介绍部门具体业务 具体工作方向是机器学习 (感觉是算法方向 当时已经有点懵了) 之后询问我对于部门有没有问题 能不能做这个方向 (算法的一点没准备 硬着头皮面了) 一道coding 十分钟时间 简单题 跟lt88 差不多 合并两个有序数组 当时比较紧张用了
-
 美团商业分析校招面经
美团商业分析校招面经timeline:9.20一面-9.21二面-9.27HR面-已offer 业务部门:到店事业群 感觉美团的面试官真的非常非常专业,而且会很积极地给一些反馈和建议,每一场面试下来都能学到很多!btw,看别的面经说HR面可能会比较偏行为面,但好像不是的,面我的HR小哥业务能力还挺强的。以及今年的面试流程好像比较短,不知道咋回事,等开奖吧。。。。。。 【一面】 1.商业分析业务价值是什么?能为业务提供
-
 快手-策略运营分析一面
快手-策略运营分析一面怎么一共才面不到20min呀,有点像KPI面。。 面试官: 自我介绍 实习经历提问 没有问什么通用型的业务类问题 反问 部门情况 面试表现
-
分析或未分析,选择什么
问题内容: 我仅使用kibana搜索ElasticSearch,并且我有几个只能接受几个值的字段(最坏的情况,服务器名,30个不同的值)。 我确实了解分析对像这样的更大,更复杂的字段执行的操作,但是对于那些简单的小字段,我却无法理解分析/未分析字段的优点/缺点。 那么,对于“有限的一组值”字段(例如,服务器名:server [0-9] *,没有特殊字符可以打破),使用analyd和not_anal
-
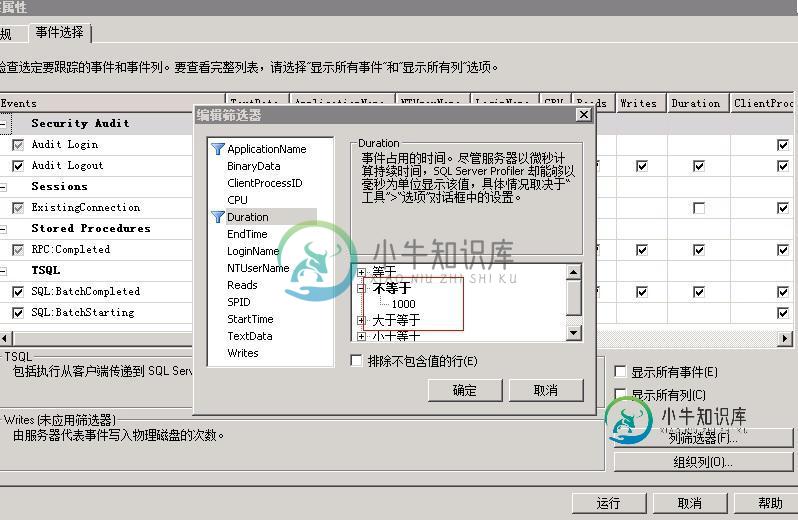 sqlserver数据库优化解析(图文剖析)
sqlserver数据库优化解析(图文剖析)本文向大家介绍sqlserver数据库优化解析(图文剖析),包括了sqlserver数据库优化解析(图文剖析)的使用技巧和注意事项,需要的朋友参考一下 下面通过图文并茂的方式展示如下: 一、SQL Profiler 事件类 Stored Procedures\RPC:Completed TSQL\SQL:BatchCompleted 事件关键字段 EventSequence、EventClass
-
JavaScript匿名函数用法分析
本文向大家介绍JavaScript匿名函数用法分析,包括了JavaScript匿名函数用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript匿名函数用法。分享给大家供大家参考。具体如下: 一、定义一个函数 在JavaScript中,可以通过“函数声明”和“函数表达式”来定义一个函数,比如 1、通过“函数声明”来定义一个函数 2、通过“函数表达式”来定义一个函数 但是两
-
php中in_array函数用法分析
本文向大家介绍php中in_array函数用法分析,包括了php中in_array函数用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了php中in_array函数用法。分享给大家供大家参考。具体如下: PHP是弱类型语言 在使用IN_ARRAY函数时尽量带上第三个参数,代码如下: 从上面的三个函数可以看出来当,第一个:in_array(0,array('s','sss'),true
-
浅谈jQuery构造函数分析
本文向大家介绍浅谈jQuery构造函数分析,包括了浅谈jQuery构造函数分析的使用技巧和注意事项,需要的朋友参考一下 在我的上一篇文章里面 阐述了jQuery的大致框架,知道了所有代码都是写在了一个自调用匿名函数里面,并且传入了window对象,源码是这样的: 我们通过alert(jquery) 知道它是一个对象,那么这个对象是怎么构造出来的呢?我们使用$(document)类似的写法获取元素,
-
JavaScript数组方法总结分析
本文向大家介绍JavaScript数组方法总结分析,包括了JavaScript数组方法总结分析的使用技巧和注意事项,需要的朋友参考一下 由于最近都在freecodecamp上刷代码,运用了很多JavaScript数组的方法,因此做了一份关于JavaScript教程的整理,具体内容如下: 一、普通方法 1、join() 将数组元素连接在一起,并以字符串形式返回 参数:可选,指定元素之间的分隔符,没有
-
php数组使用规则分析
本文向大家介绍php数组使用规则分析,包括了php数组使用规则分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了php中数组的使用规则。分享给大家供大家参考。具体分析如下: 数组在php中处于灰常重要的地位。字符串、图片、数码、视频等值都以数组的形式存在,所以了解清楚数组的各种规则十分必要。 1、键、值。 数组的基本形式: key=>value,其中,key只能是两种,integer、s
-
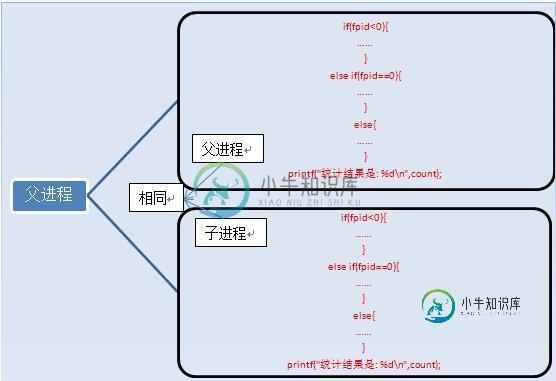 Linux中fork()函数实例分析
Linux中fork()函数实例分析本文向大家介绍Linux中fork()函数实例分析,包括了Linux中fork()函数实例分析的使用技巧和注意事项,需要的朋友参考一下 一、fork 入门知识 一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。 一个进程调用fork()函数后
-
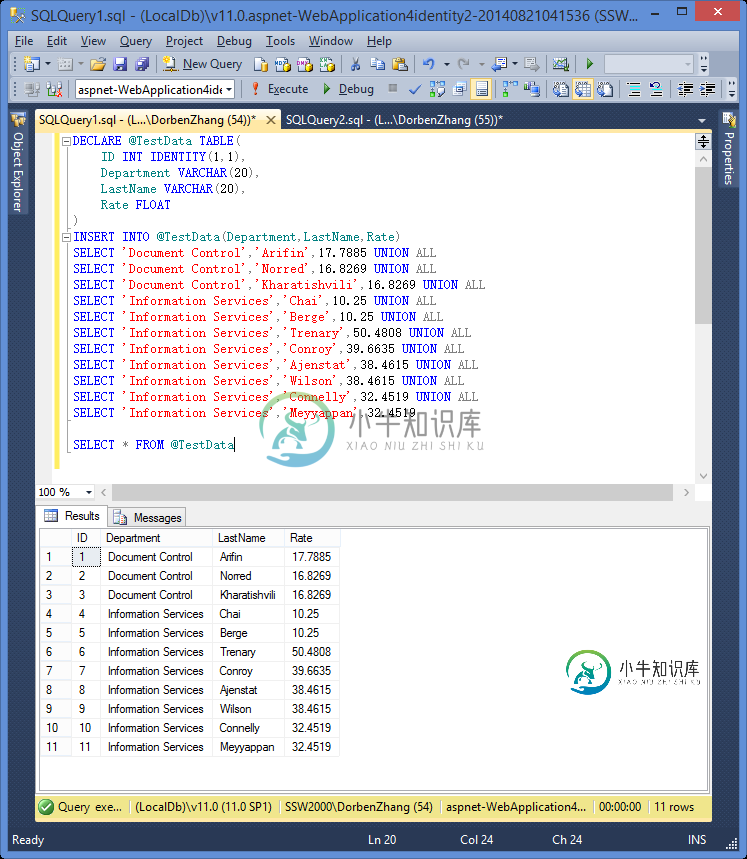 SqlServer2012中First_Value函数简单分析
SqlServer2012中First_Value函数简单分析本文向大家介绍SqlServer2012中First_Value函数简单分析,包括了SqlServer2012中First_Value函数简单分析的使用技巧和注意事项,需要的朋友参考一下 First_Value返回结果集中某列第一条数据的值,跟TOP 1效果一样,比较简单的一个函数 先贴测试用代码 下边使用FIRST_VALUE函数,创建一列新列,返回结果集中第一行的LastName值,这个所谓的
-
javascript数组去重方法分析
本文向大家介绍javascript数组去重方法分析,包括了javascript数组去重方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了javascript数组去重方法。分享给大家供大家参考,具体如下: 方法一. 思路:创建一个新的空数组,循环遍历旧数组,用indexOf()方法,可以取得元素在数组中的位置,如果值为-1表示不存在。那么新数组用indexOf去获取老数组的每一个元素,
-
Spring数据r2dbc和分组依据
我正在使用DatabaseClient执行sql查询,我不知道如何通过以下方式进行分组: