《数据分析面试》专题
-
PHP数据对象映射模式实例分析
本文向大家介绍PHP数据对象映射模式实例分析,包括了PHP数据对象映射模式实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP数据对象映射模式。分享给大家供大家参考,具体如下: 将对象和数据存储映射起来,对一个对象的操作映射为对数据存储的操作。 例如在代码中new 一个对象,使用数组对象映射模式可以将对象的一些操作,比如设置一些属性,就会自动保存到数据库,跟数据库表的一条记录对应
-
SQL数据库中的维度和单位分析
问题内容: 问题: 关系数据库(Postgres),用于存储各种测量值的时间序列数据。每个测量值可以具有特定的“测量类型”(例如,温度,溶解氧等),并且可以具有特定的“测量单位”(例如,华氏/摄氏度/开尔文,百分数/毫克/升等)。 问题: 有没有人建立过类似的数据库以保持尺寸完整性? 有什么建议吗? 我正在考虑建立一个measurement_type和一个measurement_unit表,这两个
-
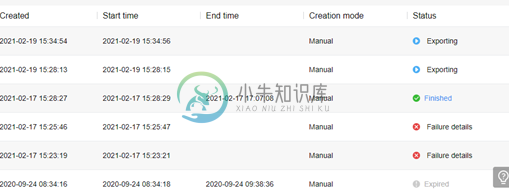 华为分析控制台导出数据失败
华为分析控制台导出数据失败试图在以下日期导出数据,但我错误地说“失败详细信息”。为什么这个导出数据会失败?我们对数据导出有限制吗?
-
如何利用Cytoscape分析“一对多”数据值
我对使用Cytoscape分析基因之间的分子关系很感兴趣,我一直在阅读Cytoscape网站上的教程,但不确定如何使用Cytoscape进行“一对多”比较。 例如,每个基因通常被指定为一个“节点”,具有与其他基因相互作用对应的“边缘”。Cytoscape使用“属性”将节点或边缘名称映射到特定的数据值。在一个简单的“一对一”比较中,你可能有一个10个基因及其表达值的列表,这样每个基因的属性将是1)基
-
 滴滴-国际化部门数据分析-凉经
滴滴-国际化部门数据分析-凉经写在前面:jd只写了滴滴国际化部门招实习生,并不知道是数分,所以答得稀烂,很多数理统计知识都忘光了。。。。 一、自我介绍 1、上一段实习中主要使用到的数据分析工具,是否会建模进行数据分析 2、在上一段实习中觉得自己做的最好的一个case 二、概率统计部分: 1、z检验和t检验分别是什么 2、大数定律和中心极限定理的内容和条件 3、假设检验的原理,两类错误分别是什么,之间的关系,怎样使两类错误的概率
-
 OPPO数据分析师 GPT等AI技术洞察
OPPO数据分析师 GPT等AI技术洞察共34min 两个面试官,一个应该是业务负责人,另一个是懂技术的~ 首先一来就是自我介绍,然后他们详细地介绍了该岗位干嘛的。 首先深挖了一个实习项目,问了一些项目的具体细节,然后还有我主要负责的部分。 然后问我了不了解爬虫,我说学过但是用的不多。(谢谢MKT3310) 问我平时数据分析工具,我说Mysql python R。 最后问了一个开放性的问题:GPT怎么对人们的生活、工作产生积极影响? 真
-
数据分区
Redisson 仅在集群模式中支持数据分区(分片)。 它使得可以使用整个 Redis 集群的内存而不是单个节点的内存来存储单个数据结构实例。 Redisson 默认将数据结构切分为 231 个槽。槽的数量可在 3 和 16834 之间。槽会一致地分布在所有的集群节点上。这意味着每个节点将包含近似相等数量的槽。如默认槽量(231) 和 4 个节点的情况,每个节点将包含接近 57 个数据分区,而对
-
分组数据
用GROUP BY 跟 HAVING子句,分组数据来汇总表内容子集。 创建分组 分组在SELECT语句的GROUP BY子句中建立。 mysql> SELECT vend_id, COUNT(*) AS num_prods -> FROM Products -> GROUP BY vend_id; +---------+-----------+ | vend_id | num_pr
-
数据分页
$Wxch_indent = M("Wxch_indent"); // 实例化Wxch_indent对象 $count = $Wxch_indent->where($where)->count();// 查询满足要求的总记录数 $Page = $this->Page($count,25);// 实例化分页类 传入总记录数和每页显示的记录数(25) $show = $Page->sho
-
数据分片
ShardingAlgorithm SPI 名称 详细说明 ShardingAlgorithm 分片算法 已知实现类 详细说明 BoundaryBasedRangeShardingAlgorithm 基于分片边界的范围分片算法 VolumeBasedRangeShardingAlgorithm 基于分片容量的范围分片算法 ComplexInlineShardingAlgorithm 基于行表达式的
-
数据分片
配置项说明 命名空间:http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding-5.0.0.xsd <sharding:rule /> 名称 类型 说明 id 属性 Spring Bean Id table-rules (?) 标签 分片表规则配置 auto-table-rules (?) 标签 自动化分片表规
-
数据分片
配置项说明 spring.shardingsphere.datasource.names= # 省略数据源配置,请参考使用手册 # 标准分片表配置 spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes= # 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用
-
数据分片
配置项说明 dataSources: # 省略数据源配置,请参考使用手册 rules: - !SHARDING tables: # 数据分片规则配置 <logic-table-name> (+): # 逻辑表名称 actualDataNodes (?): # 由数据源名 + 表名组成(参考Inline语法规则) databaseStrategy (?): #
-
数据分片
配置入口 类名称:org.apache.shardingsphere.sharding.api.config.ShardingRuleConfiguration 可配置属性: 名称 数据类型 说明 默认值 tables (+) Collection<ShardingTableRuleConfiguration> 分片表规则列表 - autoTables (+) Collection<Shardin
-
数据分片
数据分片是 Apache ShardingSphere 的基础能力,本节以数据分片的使用举例。 除数据分片之外,读写分离、数据加密、影子库压测等功能的使用方法完全一致,只要配置相应的规则即可。多规则可以叠加配置。 详情请参见配置手册。