《数据分析师》专题
-
Spring数据mongo分页
我想用Spring Data Mongo实现分页。有很多教程和文档建议使用PagingAndSorting Repository,如下所示: 因此,因为PagingAndSorting Repository提供了用于分页查询的api,我可以像这样使用它: 我的问题是这里的findAll方法实际上是在哪里实现的?我需要自己编写它的实现吗?实现StoryRepo的StoryRepoImpl需要实现这个
-
分布式数据库
分布式支持 数据访问层支持分布式数据库,包括读写分离,要启用分布式数据库,需要开启数据库配置文件中的deploy参数: return [ // 启用分布式数据库 'deploy' => 1, // 数据库类型 'type' => 'mysql', // 服务器地址 'hostname' => '192.168.1.1,19
-
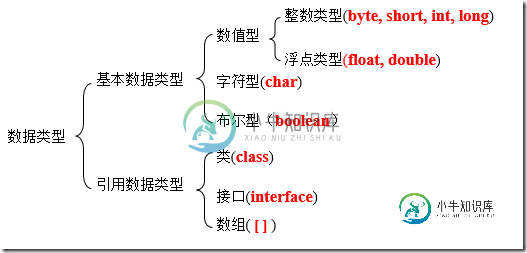 Java基本数据类型与类型转换实例分析
Java基本数据类型与类型转换实例分析本文向大家介绍Java基本数据类型与类型转换实例分析,包括了Java基本数据类型与类型转换实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java基本数据类型与类型转换。分享给大家供大家参考,具体如下: 基本数据类型 整型 浮点型 字符型 布尔型 数据类型转换 数组 首发时间:2017-06-22 21:18 修改时间: 2018-03-16 15:40 :修改了一下文字布局和样
-
 分析Mysql事务和数据的一致性处理问题
分析Mysql事务和数据的一致性处理问题本文向大家介绍分析Mysql事务和数据的一致性处理问题,包括了分析Mysql事务和数据的一致性处理问题的使用技巧和注意事项,需要的朋友参考一下 这篇文章通过安全性,用法,并发处理等方便详细分析了Mysql事务和数据的一致性处理问题,以下就是全部内容: 在工作中,我们经常会遇到这样的问题,需要更新库存,当我们查询到可用的库存准备修改时,这时,其他的用户可能已经对这个库存数据进行修改了,导致,我们查询
-
 vue组件之间数据传递的方法实例分析
vue组件之间数据传递的方法实例分析本文向大家介绍vue组件之间数据传递的方法实例分析,包括了vue组件之间数据传递的方法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了vue组件之间数据传递的方法。分享给大家供大家参考,具体如下: 1、props:父组件 -->传值到子组件 app.vue是父组件 ,其它组件是子组件,把父组件值传递给子组件需要使用 =>props 在父组件(App.vue)定义一个属性(变量)se
-
 JS数据双向绑定原理与用法实例分析
JS数据双向绑定原理与用法实例分析本文向大家介绍JS数据双向绑定原理与用法实例分析,包括了JS数据双向绑定原理与用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS数据双向绑定原理与用法。分享给大家供大家参考,具体如下: 通常在前端开发过程中,经常遇到需要绑定两个甚至多个元素之间的值,比如将input的值绑定到一个h1上,改变input的值,h1的文字也自动更新。 首先是在界面上更改input的值,需要监听i
-
thinkPHP5框架数据库连贯操作之cache()用法分析
本文向大家介绍thinkPHP5框架数据库连贯操作之cache()用法分析,包括了thinkPHP5框架数据库连贯操作之cache()用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了thinkPHP5框架数据库连贯操作之cache()用法。分享给大家供大家参考,具体如下: 介绍 TP5中自带的缓存系统,是File型缓存。也就是文件型缓存。存储地址是:根目录\..\runtime\c
-
通过源码分析Vue的双向数据绑定详解
本文向大家介绍通过源码分析Vue的双向数据绑定详解,包括了通过源码分析Vue的双向数据绑定详解的使用技巧和注意事项,需要的朋友参考一下 前言 虽然工作中一直使用Vue作为基础库,但是对于其实现机理仅限于道听途说,这样对长期的技术发展很不利。所以最近攻读了其源码的一部分,先把双向数据绑定这一块的内容给整理一下,也算是一种学习的反刍。 本篇文章的Vue源码版本为v2.2.0开发版。 Vue源码的整体架
-
Android页面之间进行数据回传的方法分析
本文向大家介绍Android页面之间进行数据回传的方法分析,包括了Android页面之间进行数据回传的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android页面之间进行数据回传的方法。分享给大家供大家参考,具体如下: 要求:页面1跳转到页面2,页面2再返回页面1同时返回数据 页面1添加如下代码: 页面2接收数据添加代码如下: 页面1接收返回数据:(需要重写onActivit
-
数据库中的SELECT语句逻辑执行顺序分析
本文向大家介绍数据库中的SELECT语句逻辑执行顺序分析,包括了数据库中的SELECT语句逻辑执行顺序分析的使用技巧和注意事项,需要的朋友参考一下 引言 这不是一个什么多深的技术问题,多么牛叉的编程能力。这跟一个人的开发能力也没有非常必然的直接关系,但是知道这些会对你的SQL编写,排忧及优化上会有很大的帮助。它不是一个复杂的知识点,但是一个非常基础的SQL根基。不了解这些,你一直用普通水泥盖房
-
SAML2.0身份提供程序AWS IAM无法分析元数据
我已经设置了AD DS、AD FS,并导出了自签名证书。我已从链接中获得元数据文件: 然而,当我尝试加载它以创建用于创建SAML2.0 IAM角色的身份提供程序时, 它指出此错误: 我们在处理您的请求时遇到以下错误:无法解析元数据 你能帮忙吗?ADFS联邦元数据xml内容/文件中需要更改的是什么?
-
解析从post请求接收的多部分/表单数据
我正在使用请求库编写Web服务客户端。我正在获取包含文件和文本json的多部分/表单数据。我不知道如何解析它。是否有合适的库来解析python中的多部分/表单数据格式,或者我应该自己编写解析器? 我的代码: b'\r\n--c00750d1-8ce4-4d29-8390-b50bf02a92cc\r\nContent-Displace: form-data; name="playback Hash
-
Firebase:向不同的项目报告分析和崩溃数据
最近我在firebase上看到了这篇文章,它详细介绍了如何从一个应用程序访问多个项目。这很棒,而且可能非常有用,但我一直无法找到一种方法来将使用分析和崩溃报告分离到单独的项目中。 我们想这样做的原因是,这样我们的客户可以完全访问他们的分析,同时将崩溃日志保存在一个只有我们才能访问的不同项目中。 我确实在文章中看到它说: 注意:在Android和iOS上,只有默认应用程序才会记录分析。 如果我们可以
-
 字节跳动数据分析实习生一面(幸福里)
字节跳动数据分析实习生一面(幸福里)下午四点半打电话问我五点半能面试吗,字节节奏好快,直接就面了 面试形式:下载飞书视频面试 时间:2022/7/18 17:30 0、自我介绍 1、飞书上考了一道SQL,要用窗口函数,case when语句等,写完代码讲思路(解出来了,但面试官提醒我要在外层关联另外一张表,我在内层关联可能会丢失一些数据。没注意到这个小细节) 2、实习相关: 讲一个自己负责的AB test实验分析。 AB test涉
-
 23提前批——蔚来商业数据分析一面面经
23提前批——蔚来商业数据分析一面面经蔚来自动驾驶部门1. 自我介绍 2. 问了项目中AB实验相关的问题,后问如何优化 3. 问了项目中AB实验和机器学习项目的异同点 4. 详细介绍另一个项目 5. 职业规划问题 6. Q&A 问了一些公司自动驾驶的方向 总的来说概念性思考类问题比较多… 可能是面商业数分的关系吧,应该是比较考察思维框架,技术细节抠得不多 #校招##提前批##蔚来##蔚来面试##数据分析师#