《数据分析师》专题
-
7.分析
分析 通视分析 在“分析”菜单栏中点击“通视分析”,在地面或者建筑物表面选择一点,然后鼠标移动到另一个位置点击结束,即可判断出两点间是否有障碍物,是否可见。通视分析结果显示空间距离、垂直距离、水平距离、起点海拔及两点之间是否可视。 可视域分析 在“分析”菜单栏中点击“可视域分析”,在地面上选择一个视野中心点,然后鼠标移动绘制一个可视圆弧,绘制出分析范围,可以判断出这片区
-
9.2分析
通视分析 在“分析”菜单栏中点击“通视分析”,在地面或者建筑物表面选择一点,然后鼠标移动到另一个位置点击结束,即可判断出两点间是否有障碍物,是否可见。通视分析结果显示空间距离、垂直距离、水平距离、起点海拔及两点之间是否可视。 可视域分析 在“分析”菜单栏中点击“可视域分析”,在地面上选择一个视野中心点,然后鼠标移动绘制一个可视圆弧,绘制出分析范围,可以判断出这片区域哪些
-
9.分析
测量 距离测量 LSV可以量算出两个或多个点之间的地表距离、空间距离和投影距离。 测量地表距离 地标距离为两点间在通过地表上相连的长度,其数值与地形有关。在“分析”菜单栏中点击“距离测量”,选择测量地表距离,在地表上连续点击,测量地表距离。图上会显示各分段的长度和地表总长。 测量空间距离 空间距离为两点间不计地形而直接相连的限度长度。在“分析”菜单栏中点击
-
分析(Analysis)
在前面的一章中,我们已经看到Lucene使用IndexWriter使用Analyzer分析Document(s) ,然后根据需要创建/打开/编辑索引。 在本章中,我们将讨论分析过程中使用的各种类型的Analyzer对象和其他相关对象。 了解Analysis过程以及分析器的工作原理可以让您深入了解Lucene如何为文档编制索引。 以下是我们将在适当时候讨论的对象列表。 S.No. 类和描述 1 To
-
profile分析
算法工程师将算法移到 vsp_simulate 工程上来,除了将算法跑通,还有一项重要的功能就是优化算法,要尽可能节省内存空间,尽可能的提升算法的执行效率,本章就讲讲如何利用 profile 来快速定位哪个算法函数效率低下。 性能评测工具 gprof gprof 是 GNU Binutils 之一,它能为 Linux 程序精确分析性能瓶颈,能精确地给出函数被调用的时间和次数以及函数的调用关系,堪称
-
云分析
服务类型 SuperMap Online提供多种在线分析服务来满足您的位置分析需求。这些云分析服务支持GET和HEAD请求,返回格式支持json\xml\jsonp格式。您可以直接在业务系统中通过HTTP\HTTPS请求调用这些服务,也可以将GIS云存储的数据服务和上述云分析服务结合在一起进行应用开发。 这些分析服务包括: 路径导航 地理编码 逆地理编码 本地搜索 坐标转换 动态标绘 使用限制 调
-
profile 分析
算法工程师将算法移到 vsp_simulate 工程上来,除了将算法跑通,还有一项重要的功能就是优化算法,要尽可能节省内存空间,尽可能的提升算法的执行效率,本章就讲讲如何利用 profile 来快速定位哪个算法函数效率低下。 性能评测工具 gprof gprof 是 GNU Binutils 之一,它能为 Linux 程序精确分析性能瓶颈,能精确地给出函数被调用的时间和次数以及函数的调用关系,堪称
-
数据是否跨分区分割?
我读过Kafka文档,但当有人谈论数据和分区时,我仍然感到困惑。在文档中,我看到客户机将向分区发送消息。然后将消息分区复制到副本(跨代理)。和使用者从分区读取数据。 我有一个有两个分区的主题。假设我有一个生产者,它向分区#1发送消息。但我有两个消费者,一个从分区1读取,另一个从分区2读取。这是否意味着我的分区1将有50%的消息,分区2将有50%的消息。或者,当客户端将数据发送到分区#1时,分区#1
-
第二部分:分布式数据
一个成功的技术,现实的优先级必须高于公关,你可以糊弄别人,但糊弄不了自然规律。 ——罗杰斯委员会报告(1986) 在本书的第一部分中,我们讨论了数据系统的各个方面,但仅限于数据存储在单台机器上的情况。现在我们到了第二部分,进入更高的层次,并提出一个问题:如果多台机器参与数据的存储和检索,会发生什么? 你可能会出于各种各样的原因,希望将数据库分布到多台机器上: 可扩展性 如果你的数据量、读取负载、写
-
 Mysql数据库中数据表的优化、外键与三范式用法实例分析
Mysql数据库中数据表的优化、外键与三范式用法实例分析本文向大家介绍Mysql数据库中数据表的优化、外键与三范式用法实例分析,包括了Mysql数据库中数据表的优化、外键与三范式用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Mysql数据库中数据表的优化、外键与三范式用法。分享给大家供大家参考,具体如下: 数据表优化 将商品信息表进行优化 1.创建商品种类表: 2.将商品种类写入商品种类表中: 注意:插入另一个表的查询结果不需要加
-
将数据从文件解析为Java,然后解析为mysql数据库
问题内容: 我有以上述格式给出的.Data文件。我正在用Java编写程序,该程序将从.data文件中获取值并将其放入缓冲区中。我的Java程序通过JDBC连接到Mysql(windows)。所以我需要从上述格式的文件中读取值,并将其放入缓冲区 这样,我将存储这些值,并且jdbc将填充Mysql(windows)上的数据库表。请告诉我最好的方法。 问题答案: 查看此问题的答案,以读取文件行并将其拆分
-
Spark数据帧的分区数
有人能解释一下将为Spark Dataframe创建的分区数量吗。 我知道对于RDD,在创建它时,我们可以提到如下分区的数量。 但是对于创建时的Spark数据帧,看起来我们没有像RDD那样指定分区数量的选项。 我认为唯一的可能性是,在创建数据帧后,我们可以使用重新分区API。 有人能告诉我在创建数据帧时,我们是否可以指定分区的数量。
-
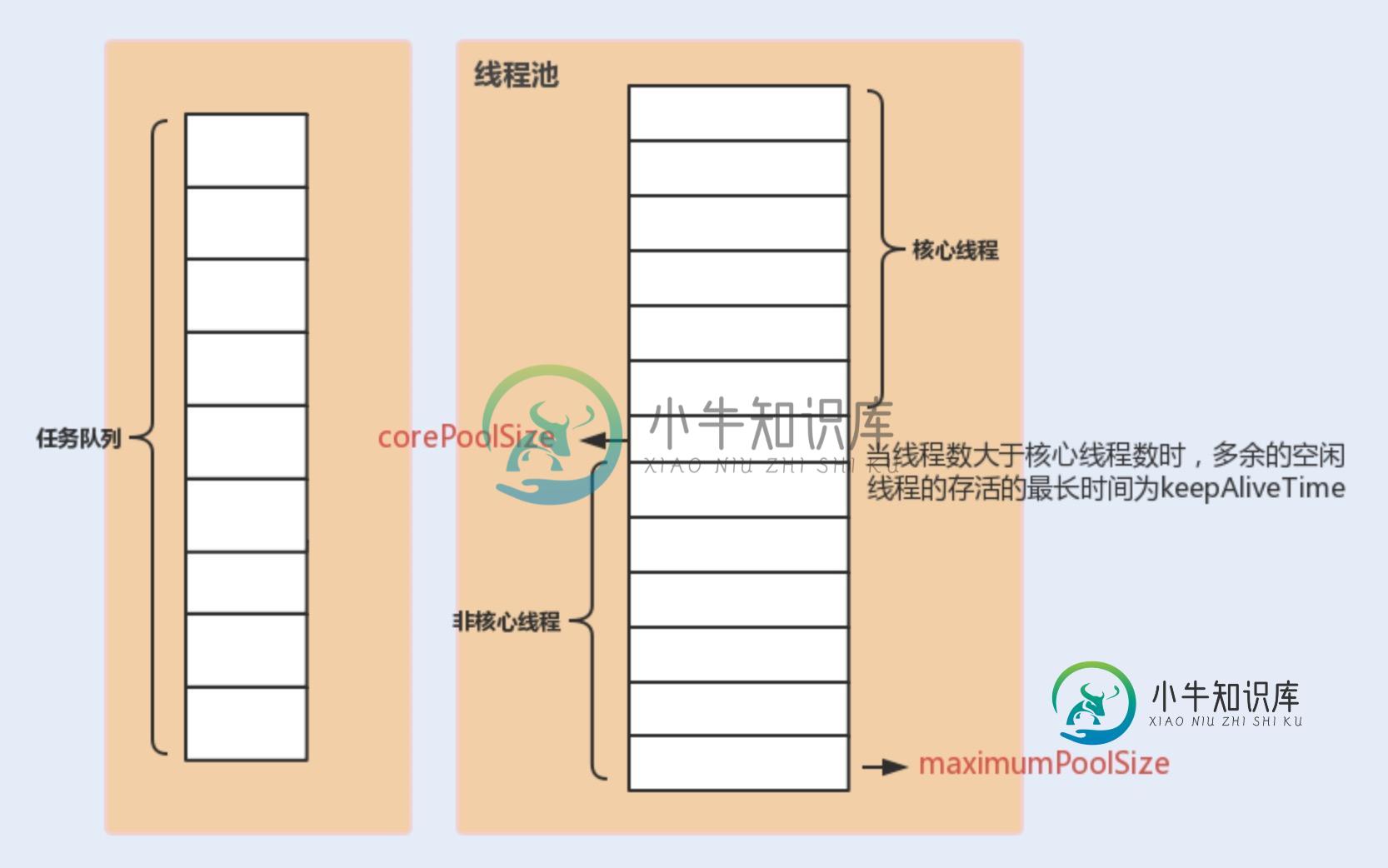 ThreadPoolExecutor 构造函数重要参数分析?
ThreadPoolExecutor 构造函数重要参数分析?本文向大家介绍ThreadPoolExecutor 构造函数重要参数分析?相关面试题,主要包含被问及ThreadPoolExecutor 构造函数重要参数分析?时的应答技巧和注意事项,需要的朋友参考一下 : : 核心线程数线程数定义了最小可以同时运行的线程数量。 : 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。 : 当新任务来的时候会先判断当前运行的线程数量是否
-
分析或未分析,选择什么
问题内容: 我仅使用kibana搜索ElasticSearch,并且我有几个只能接受几个值的字段(最坏的情况,服务器名,30个不同的值)。 我确实了解分析对像这样的更大,更复杂的字段执行的操作,但是对于那些简单的小字段,我却无法理解分析/未分析字段的优点/缺点。 那么,对于“有限的一组值”字段(例如,服务器名:server [0-9] *,没有特殊字符可以打破),使用analyd和not_anal
-
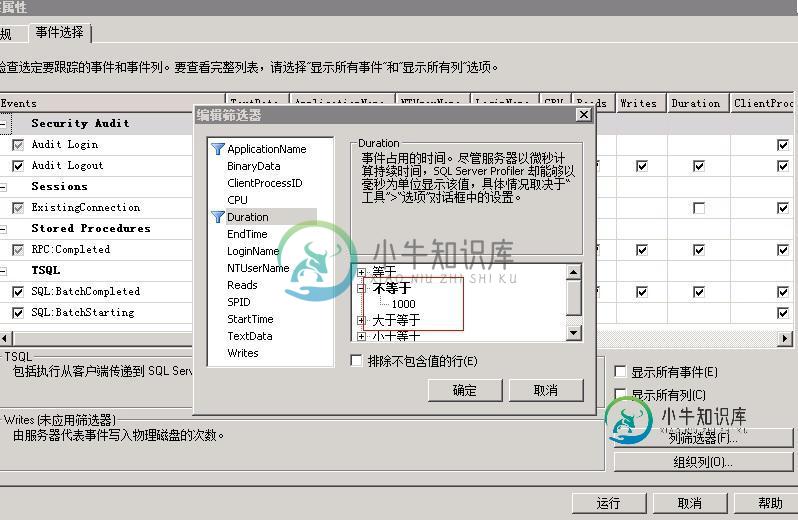 sqlserver数据库优化解析(图文剖析)
sqlserver数据库优化解析(图文剖析)本文向大家介绍sqlserver数据库优化解析(图文剖析),包括了sqlserver数据库优化解析(图文剖析)的使用技巧和注意事项,需要的朋友参考一下 下面通过图文并茂的方式展示如下: 一、SQL Profiler 事件类 Stored Procedures\RPC:Completed TSQL\SQL:BatchCompleted 事件关键字段 EventSequence、EventClass