《还愿》专题
-
mysqldump:将单个备份表还原到原始DB
我正在尝试使用mysqldump备份一个特定的表。我使用此批处理命令行执行此操作: 我在结果文件中收到的是这样的命令: 问题是,在这个场景中,表将在默认DB中创建,而不一定在我想要的DB中创建。我想要这样的东西: 我如何使用mysqldump来创建它呢?
-
这段代码是同步的还是异步的?
-
Spring jdbc、jndi还是独立的tomcat jdbc连接池?
我将在应用程序中使用tomcat-jdbc连接池。有两种方法可以添加它: 谢了。
-
Google App Engine灵活部署WAR还是JAR应用?
我在GAE Flexible的许多示例项目中看到,与传统的WAR部署相比,开始接受“胖”JAR的概念(使用嵌入式Web服务器,如码头,Spring靴,SparkJava或Tomcat)。这两种方法都涉及单个 JVM 进程(即,无论向 Tomcat 部署了多少个 WAR,它都是相同的 JVM 进程)。 在什么情况下,在 Google 应用引擎中,任何一种部署方法都优于另一种部署方法?
-
在Kotlin中传递方法还是传递接口
那代码在OOP方式下还是好的吗?还是我应该用接口?我认为直接通过方法是可以的。
-
JWT应该存储在localStorage还是cookie中?[副本]
为了使用JWT保护REST API,根据一些材料(如本指南和本问题),JWT可以存储在本地存储或Cookies中。根据我的理解: localStorage受XSS限制,通常不建议在其中存储任何敏感信息 对于cookie,我们可以应用“httpOnly”标志,以降低XSS的风险。然而,如果我们要从后端的Cookies中读取JWT,那么我们将受到CSRF的约束 因此,基于上述前提,最好将JWT存储在C
-
以编程方式创建火还原触发器?
有没有办法以编程方式创建firestore触发器? 我希望使用火还原触发器来保持复合对象在初始化位置的一致性- 但是,我不需要查看集合中的每个“主要”文档,因为只有有限数量的“主要”对象具有“次要”关系——我的假设是,只查看特定文档而不是整个集合将提高总体性能并降低成本,因为触发器只会为相关的文档触发文档,与集合中的文档总数相比,要侦听的文档数量要少得多 虽然我可以将这些具有该关系的文档放在一个单
-
HTTP补丁是幂等的还是非幂等的?
我读过很多地方说HTTP补丁是非幂等的。有人能解释一下为什么它是非幂等的吗?因为根据定义,幂等方法可以改变资源状态,也可以不改变资源状态,但是重复的请求在第一个请求之后应该不会有进一步的副作用。重复的补丁请求如何改变资源状态?
-
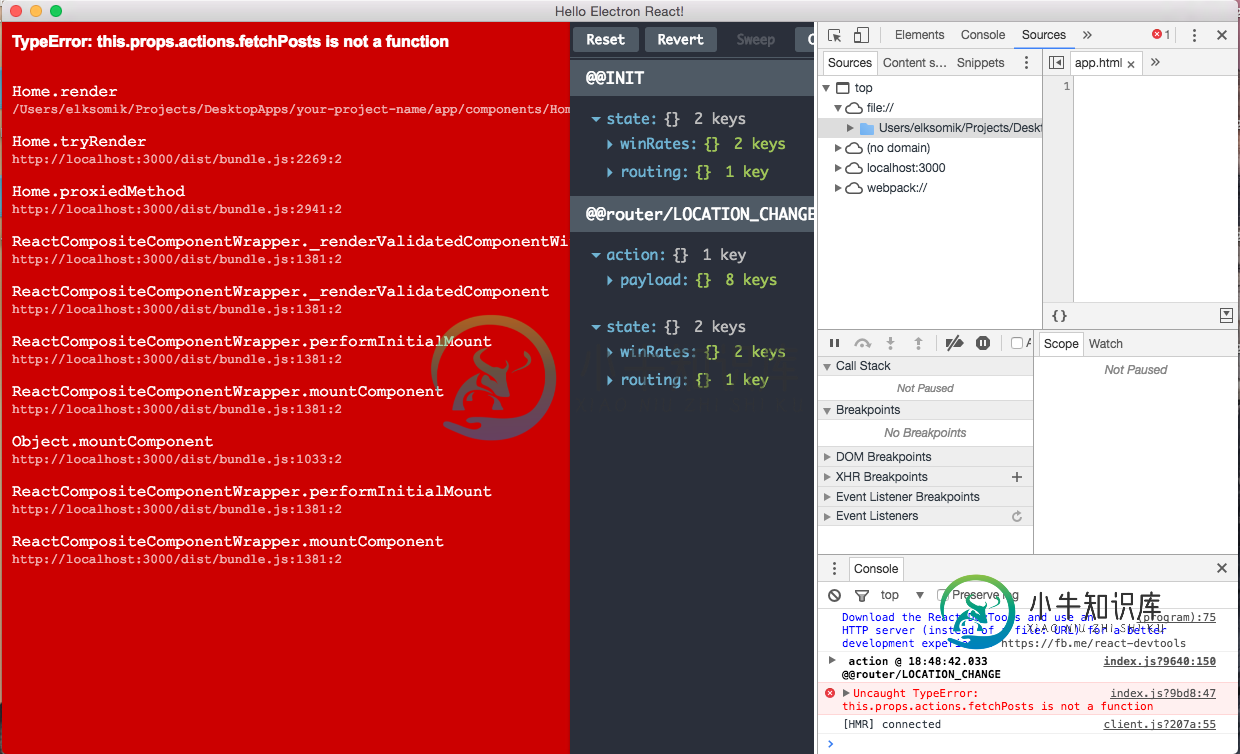 反应还原 - 这个.props.action.fetchposts不是一个函数
反应还原 - 这个.props.action.fetchposts不是一个函数我对从我的组件调用异步操作有问题,我想我做了工作所需的一切,但似乎没有,我使用了: 将调度映射到属性 在里面我回来了 操作:bindActionCreators(fetchPosts,调度) 我把它连接起来。 在所有这些事情之后,我试着在我的组件中调用这个动作- this . props . actions . fetch post() 结果我在控制台中收到这个错误- this.props.act
-
Android同步连接到REST/JSON-Volley、VolleyPlus还是Retrifit?
null 你有什么建议?有关于这个用例的Volley/VolleyPlus示例或教程吗?翻新的举动值得重新工作吗? 更新: 我开始用改型和替换我的一些截击电话。太完美了!它用比Volley更少的代码完成了我想要的事情。到目前为止,我还没有进行自动解析,只是获取JSON格式的原始HTTP响应并发送到我以前的解析器类,但最终当我了解POJOs和GSON时,我会替换它们。我不得不在同步调用的主活动上禁用
-
在PlayStore中还原到以前版本时出错
我不小心在Google Play商店上传了一个更新版本的应用程序。现在我想恢复我的应用程序,我取消了我的应用程序的前一个版本,现在我试图激活前一个,但我得到了以下错误: 谁能指导我怎样才能摆脱这些错误。紧急情况...
-
ANTLR4还支持无扫描解析器语法吗?
我有一个利用CharsAsTokens人造lexer的无扫描解析器语法,它为ANTLR4到4.6版本生成了一个可用的Java解析器类。但是,当更新到ANTLR 4.7.2到4.9.3-Snapshot时,该工具会生成代码,从相同的语法文件产生数十个编译错误,如下所述。 我这里的问题很简单:是否不再支持无扫描解析器语法,或者必须在4.7和更高版本中以不同的方式指定基于字符的终端? 更新: 不幸的是,
-
Spring webflux控制器:使用POJO还是使用Mono?
在控制器中,我可以写: 有什么区别吗?主体解析会在不同的线程中进行吗?在第一种情况下,我会阻塞主反应器线程直到被解析?
-
Azure Cosmos api客户端选择Azure。Cosmos还是Azure.DocumentDB.Core?
我找到了2个官方套餐 Microsoft.Azure.DocumentDB.Core 此客户端库使面向 .NET Core 的客户端应用程序能够通过 DocumentDB (SQL) API 连接到 Azure Cosmos DB。 对于这个包,我们还找到了支持ORM的优秀SDK Cosmonaut 此客户端库使客户端应用程序能够通过SQLAPI连接到Azure Cosmos。 据我所知,第一个是
-
回收器视图还是列表视图?[副本]
编辑:我的问题是ListView有没有比RecyclerView更有优势的地方?如果不是,那么为什么谷歌没有将它标记为贬值。此外,虽然我们可以在库中找到ListView,但如果我们创建了一个新的Project,但要使用RecyclerView,则必须使用另一个依赖项。