《数据库开发工程师》专题
-
无法连接到数据库服务器mysql工作台
我正在尝试连接到mysql工作台,但遇到以下错误 错误消息无法连接到数据库服务器 用户“root”从主机到服务器的连接尝试失败(位于127.0.0.1:3306:无法打开数据库)。 请:1。检查mysql是否正在服务器127.0.0.1上运行 检查mysql是否在端口3306上运行(注意:3306是默认值,但可以更改) 检查root是否具有从您的地址连接到127.0.0.1的权限(mysql权限定
-
 DBeaver一款替代Navicat的数据库可视化工具
DBeaver一款替代Navicat的数据库可视化工具本文向大家介绍DBeaver一款替代Navicat的数据库可视化工具,包括了DBeaver一款替代Navicat的数据库可视化工具的使用技巧和注意事项,需要的朋友参考一下 对于很多开发者来说,Navicat这个软件并不陌生, 相信这个彩虹色图标的软件,有效的帮助了你的开发工作。从前上学的时候,我都是用的都是从网上找来的密钥进行破解的,但是一直在寻找有没有一个能找到一个免费的能完美替代Navicat
-
JavaFX TableView用于SQL数据库访问-有多少工厂?
我的团队正在评估JavaFX作为数据库应用程序的平台,该应用程序将大量使用TableView。我们的印象是,为了在表中显示数据,我们必须对TableView进行子类化,并为我们需要的每个列数据类型和表示模式编写我们自己的ValueFactory类。 例如,如果我们想将位字段显示为是/否文本和开/关复选框,我们需要2个ValueFactory或1个ValueFactory和2个CellFactory
-
MySQL工作台会话看不到数据库的更新
我使用 .deb 在 Ubuntu 系统中安装了 MySQL Workbench(community-6.2.3)。 工作台会话似乎看不到其他会话(应用程序/命令行客户端)对数据库的更新(DML)。 新会话能够在其启动时看到数据库的正确状态,但之后发生的更改对它不可见。似乎工作台 会话在工作台提交后确实与数据库同步。 我得到。 非工作台会话似乎没有任何这些问题。 我这是少了个配置什么的吗 更新:
-
使用数据库在工作区之间切换-连接
是否可以使用databricks连接来切换工作区? 我目前正在尝试切换: 但这会返回以下错误:< code>AnalysisException:无法修改Spark配置的值:spark.driver.host
-
从spring工具套件连接到数据库时出错
创建名为“org.springframework.boot.autocconfigure.orm.jpa.Hibernatejpaconfiguration”的bean时出错:通过构造函数参数0表示的依赖项不满足;嵌套异常为org.springframework.beans.factory.beanCreationException:创建类路径资源[org/springframework/boot
-
房间数据库在mac book pro m1中无法工作
房间数据库在mac book pro m1中不工作,我已经添加了id“kotlin kapt” android studio控制台日志的屏幕截图 哪里出错了:任务': app: kaptDebugKotlin'执行失败。 执行org.jetbrains.kotlin.gradle.internal时出错。KaptWithoutKotlincTask$KaptExecutionWorkAction
-
SQL Server 2008 备份数据库、还原数据库的方法
本文向大家介绍SQL Server 2008 备份数据库、还原数据库的方法,包括了SQL Server 2008 备份数据库、还原数据库的方法的使用技巧和注意事项,需要的朋友参考一下 SQL Server 2008 备份数据库: 1.打开SQL , 找到要备份的数据库 , 右键 >> 任务 >>备份 2.弹出 [ 备份数据库对话框 ] ,如图: 3.点击添加 [ 按钮 ] . 如下图: 4.选择要
-
区分关系型数据库与非关系型数据库
一种是关系数据库,典型代表产品:DB2; 另一种则是层次数据库,代表产品:IMS层次数据库。 非关系型数据库有MongoDB、memcachedb、Redis等。
-
什么时候将数据库称为嵌入式数据库?
问题内容: 术语“嵌入式数据库”与“数据库”具有不同的含义吗? 问题答案: 我已经看到了嵌入式数据库的两个定义: 嵌入式数据库,例如专门为“嵌入式”空间(移动设备等)设计的数据库系统。这意味着它们在紧凑的环境中(在内存/ CPU方面)表现合理。 嵌入式数据库,就像不需要服务器的数据库一样,并且嵌入在应用程序中(例如SQLite)。这意味着所有内容都由应用程序管理。 我个人从未见过该术语完全按照Wi
-
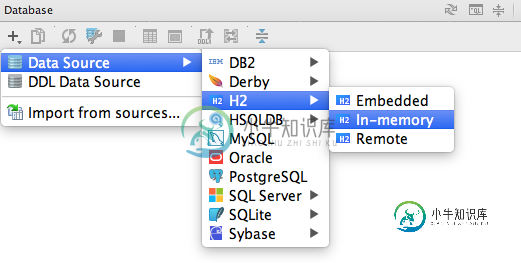 使用IntelliJ数据库客户端连接到H2数据库
使用IntelliJ数据库客户端连接到H2数据库我的Grails应用程序在开发模式下使用h2数据库(Grails应用程序的默认行为)。中的DB连接设置是 我正在尝试使用IntelliJ IDEA的数据库客户端工具为此数据库建立连接。我开始这样创建连接 然后在下面的对话框中,输入JDBC URL 并选择“模式”上的所有可用数据库 “Test Connection”(测试连接)按钮表示成功,但从红色圆圈中可以看到,没有找到任何表格。似乎我已经正确地
-
实时数据库和“普通”数据库有什么区别?
我正在研究一些用于开发Web应用程序的后端即服务(BaaS)解决方案,并且我经常看到Firebase将他们的数据库称为“实时数据库”,而例如Backawa没有提到短语“实时”任何地方。 我知道实时意味着数据会立即得到处理,但我认为所有数据库都会这样做?例如,如果我有一个MySQL/SQLite/PostgreSQL数据库和insert数据,我希望它能在(毫秒)秒内检索到,而且肯定是在“insert
-
拉威尔从原始数据库到雄辩的数据库
我正在尝试将我的laravel原始查询改为eloquent,因为现在我已经掌握了eloquent的一些基本知识,并且尝试在laravel中创建博客。但有些复杂性仍然存在。 第一:这是我的原始SQL: 我在Laravel中的原始查询: 现在我正试图把这个原始的问题变成雄辩的问题。我已经做过模型了。下面是我在控制器中的雄辩提问。 我的问题: 1:我有群体一致性(不同的q.sku)。那么如何用雄辩的口才
-
Oracle数据库将数据库还原到以前的状态
我有一些自动测试,可以插入一些数据,并将其保存到Oracle XE数据库,版本11g。目前,测试完成后,通过SQL手动删除数据。但是我想知道有没有其他方法可以使回滚更容易,更有效?我正在阅读关于恢复点,想知道这是我正在寻找的功能吗? 恢复的过程会消耗多少内存?使用它来满足我的需要是一种良好的做法吗?或者它可能是回滚数据插入的其他方式吗? 谢谢
-
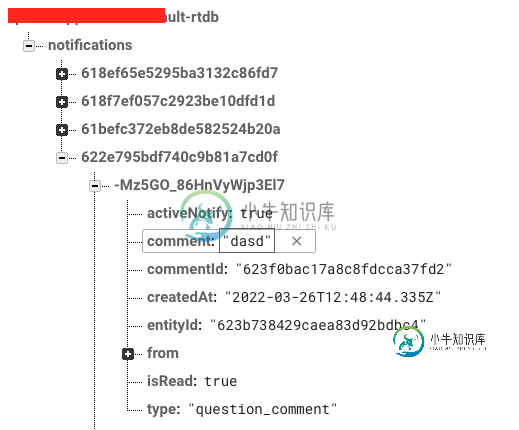 火库实时数据库,如何只读自己的数据?
火库实时数据库,如何只读自己的数据?我的nextjs webapp中有一个实时数据库,我用它来发送通知。 我的数据库的架构如下: 我仅以管理员身份从服务器端写入数据,但按以下方式从客户端读取数据: 在这一刻,我有以下规则: 正如您所看到的,每个经过身份验证的人都可以阅读所有内容。我希望用户只阅读他自己的通知。ObjectID是我的mongoDB中的引用。 例如,如果我的我只想访问路径的数据,如果我试图从,那么我什么也得不到(或错误)