《巨衫数据库》专题
-
Spring将quartz数据持久化到Oracle数据库中的多个模式
我正在使用Quartz与Spring集成来安排工作。为了保存quartz数据,我在spring配置中提供了一个数据源。 以上内容将把数据持久化到datasource中配置的一个模式中。我需要做的是将quartz数据存储到多个模式中。 我怎么做得到?
-
如何在活动spring事务中将数据刷新到数据库中?
我想使用spring测试框架测试hibernate Session的save()方法。@测试方法为: 我想刷新用户到数据库。我希望我的用户在此方法后在数据库中 然后我要使用spring data framework转到database并通过下一行获取这个保存的用户: 非常感谢您的回应。问题是方法flush()没有将我的用户放入数据库,我尝试了isolation.read_uncommitted,但
-
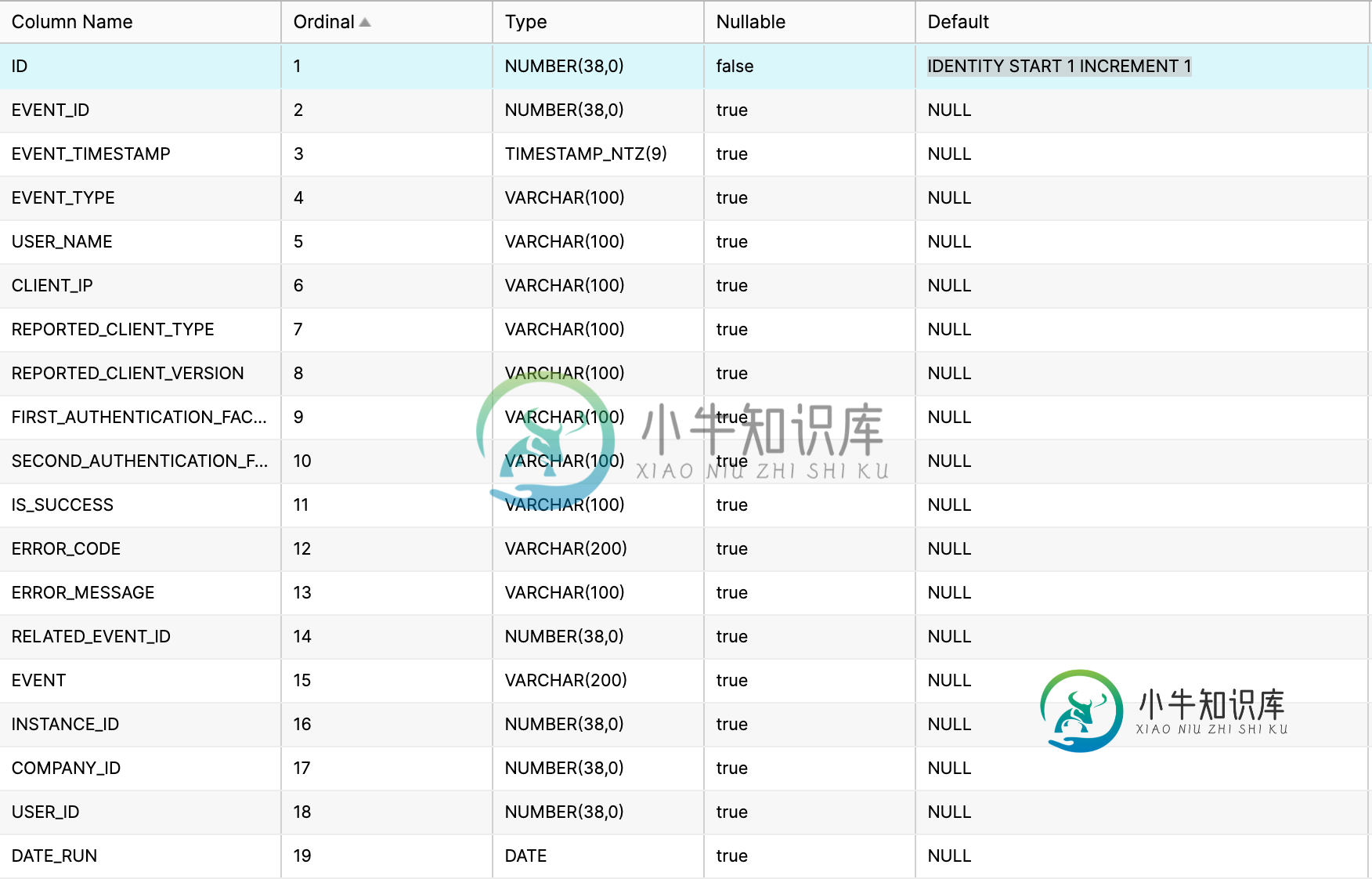 无法使用pandas to_sql()方法将数据插入雪花数据库表
无法使用pandas to_sql()方法将数据插入雪花数据库表我的雪花实例上有一个数据库。数据库有两个模式和。 模式使用SQLAlchemy- 我有一个列的dataframe,如下所述,需要插入到上面创建的表中- 因此,为了插入数据帧,我使用了方法,如下所示- 数据帧。to_sql(table_name,self.engine,index=False,method=pd_writer,if_exists=“append”) 这会给我一个错误- 这个错误是因为
-
Android Studio在Android设备上保存和查看数据库中的数据
我使用android studio创建了一个数据库,并通过DB查看它。但是为了查看我的数据库,我需要从设备文件资源管理器中拉出。我如何保存和查看我的数据库在实际设备而不拉出设备文件资源管理器,我的android studio版本是3.5。
-
java - Springboot打包jar运行找不到数据库,请求不到数据?
Springboot在IDEA运行没有问题,但是打包jar后在本地终端java -jar就无法访问数据库请求数据了 这是我的applocation.yml 我的application.properyies spring.application.name=demo 我IDEA上无论连的自己本地库还是云服务宝塔上面的公网都可以,就是内网不行,但是应该接公网就可以吧?我该怎么解决?
-
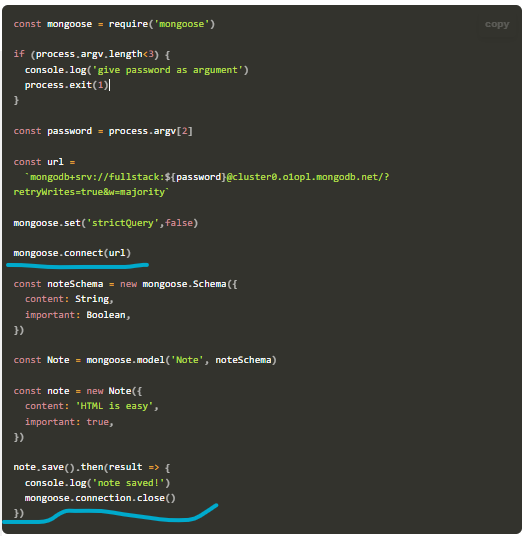 javascript - 连接数据库和往数据库中写是异步执行的?
javascript - 连接数据库和往数据库中写是异步执行的?连接数据库和往数据库中写是异步执行的? 在fullstackopen part3看到这样一段代码,没有等到连接数据库完之后就执行了往数据库中写的操作,这样写合理吗? 还有下面这段代码我也觉得不合理,它将上面这段代码封装成了一个module。但是如果连接失败的话,返回的这个构造函数还是会被使用,直到报错为止。 我们写一段代码来使用这个module看看会发生什么 连接 通过Note构造函数创建一个实体
-
尽管有足够的可用内存,但巨大的数组仍将导致内存不足
问题内容: 使用该标志提供一个1 GB的堆,以下功能可以正常工作: 该阵列应代表约600 MB。 但是,以下引发OutOfMemoryError: 尽管该阵列应代表约800 MB,因此很容易装入内存。 丢失的记忆在哪里消失了? 问题答案: 在Java中,堆中通常有多个区域(和子区域)。您拥有一个年轻且历久弥新的地区,拥有最多的收藏家。大阵列会立即添加到租用区域,但是根据您的最大内存大小,将为年轻空
-
如何过滤2个包含数百万个相同id项目的巨大列表[重复]
这是我的2个清单上有超过百万的项目。两者都具有相同ID的相同项。ID在字符串中。我只需要一个不一样的ID的项目。我是这样做的。但我确信一定有更好的解决办法,而且具有高度的持久性:- 我尝试使用流,但我做不到。我想用流API应该更好。请建议我有什么改进之处。
-
有人能解释一下如何将巨大的秒数转换为可读的分秒吗?
编辑:非常感谢所有回复的人,并展示了其他获得他们的方法:D
-
MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?
本文向大家介绍MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?相关面试题,主要包含被问及MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?时的应答技巧和注意事项,需要的朋友参考一下 redis 配置文件 redis.conf 中有相关注释,大家可以自行查阅或者通过这个网址查看: http://do
-
一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 MySQL 数据库,又插入了一条数据,此时 id 是几?
本文向大家介绍一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 MySQL 数据库,又插入了一条数据,此时 id 是几?相关面试题,主要包含被问及一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 MySQL 数据库,又插入了一条数据,此时 id 是几?时的应答技巧和注意事项,需要的朋友参考一下 表类型如果是 MyISAM ,那 id 就是 8。 表类型如果是 InnoD
-
Java:一张自增表里面总共有 7 条数据,删除了最后 2 条数据,重启 mysql 数据库,又插入了一条数据,此时 id 是几?
一般情况下,我们创建的表类型是InnoDB。 不重启MySQL,如果新增一条记录,id是8; 重启,ID是6;因为InnoDB表只把自增主键的最大ID记录在内存中,如果重启,已删除的最大ID会丢失。 如果表类型是MyISAM,重启之后,最大ID也不会丢失,ID是8; InnoDB必须有主键(建议使用自增主键,不用UUID,自增主键索引查询效率高)、支持外键、支持事务、支持行级锁。 系统崩溃后,My
-
Pandas-根据日期将数据框拆分为多个数据框?
问题内容: 我有一个带有多个列以及一个日期列的数据框。日期格式为15年12月31日,我将其设置为日期时间对象。 我将datetime列设置为索引,并希望对数据框的每个月执行回归计算。 我相信实现此目的的方法是将数据框基于月份拆分为多个数据框,存储到数据框列表中,然后对列表中的每个数据框执行回归。 我使用过groupby可以按月成功拆分数据框,但是不确定如何正确地将groupby对象中的每个组转换为
-
根据数据类型获取熊猫数据框列的列表
问题内容: 如果我有一个包含以下列的数据框: 我想说:这是一个数据框,请给我列出对象类型或日期时间类型的列的列表吗? 我有一个将数字(Float64)转换为两位小数的函数,并且我想使用此数据框列的特定类型的列表,并通过此函数运行它以将它们全部转换为2dp。 也许: 问题答案: 如果您想要某种类型的列的列表,可以使用:
-
如何在dask数据帧内将xarray数据集转换为熊猫数据帧
我有一个需要一个数据帧作为输入的计算。我想对存储在扩展到51GB的netCDF文件中的数据运行此计算-目前,我一直在使用打开文件,并使用块(我的理解是,此打开的文件实际上是一个dask数组,因此一次只能将数据块加载到内存中)。但是,我似乎无法利用这种延迟加载,因为我必须将xarray数据转换为pandas数据帧才能运行我的计算——我的理解是,在这一点上,所有数据都加载到内存中(这是不好的)。 所以