《字节跳动商业化》专题
-
 信也科技商业分析笔试(用户运营)
信也科技商业分析笔试(用户运营)40min 全选择题(行测+统计学问题) 19个单选 1个多选 4道逻辑行测 16道计算题/概率题/假设检验/abtest概念 尊嘟不难 dbq我忘带草稿纸了乱写一通😭
-
 小红书商业产品运营岗一面面经
小红书商业产品运营岗一面面经一面: 1. 自我介绍 2. 你在滴滴的实习可以展开说说吗? 3. 你在蘑菇街的实习可以展开说说吗?面试官:“打断一下,展开说说是想听到项目经历、实习中的具体你的策略和思考,而不是重复简历里的内容”如怎么进行人群分层的?新人侧,会对其进行年龄、渠道来源进行分类,再进行push么?怎么AB测试的,你的策略是什么?希望实x生能有更多的自主思考。” 4. 你的过往经历(教育、实习)都和该岗位实x方向没什
-
 小红书商业产品运营岗二面面经
小红书商业产品运营岗二面面经一面结束后,很快HR给我打说,这边需要加面一轮,然后约了隔天的上午11点。 二面(实习生面的我) 对sql能力的考察。 Inner join和left join是什么 平时有写过嘛,熟悉程度怎么样? 代码写的时候的顺序,想听到的是where、having、group by、order by的顺序 我追问了一下最快多久能有面试结果,说是还会有三面,因为这个岗位是有转正机会的 隔了一天,+V问了一下H
-
 阿里国际商业暑期实习一面凉经
阿里国际商业暑期实习一面凉经自我介绍。还特意强调简历上有得就不要说了,讲一下在学校的经历。 仔细问了下成绩 说一下你之前用Java语言做的过的项目的结构是怎样的 问了下比赛经历 读研,考公,就业怎么看的,你为啥选择直接就业 你说要走算法方向需要扎实的数理基础,你觉得不适合自己,我是否可以理解为你数理基础不好(纯纯给自己挖的坑) 你简历上的那个项目你都做啥了 竟然开始讨论之前的笔试题了,真麻了。没写的题还非让说思路,写了的题还
-
 美团二面-核心本地商业-前端凉经
美团二面-核心本地商业-前端凉经把整理过的面经发出来攒攒人品,许愿接一个offer(腾讯云智,腾讯金融科技,淘天,快手还在流程中) 面试时间:5.9下午 前言 昨天晚上一面,今天早上九点多,淘天通知三面改期,突然收到美团二面,约的当天下午,翘课开干! 面经 还是主要写印象深的,没答好的 上来先自我介绍,考研吗,到岗时间,实习到什么时间 后面开始挖项目,和一面一样集中在技术选型,为什么选这个,有考虑过类似的技术吗 项目最困难的点,
-
 字节日常实习生·风控运营岗-国际电商·面经分享
字节日常实习生·风控运营岗-国际电商·面经分享端午前面试了风控运营实习生这个岗位 一面是hr面,更多是体现在实习项目和个人经历的发掘 hr小姐姐人很好,态度非常友善,整个过程交流很顺畅,没有什么压力 总时长:28min 面试问题 1.自我介绍 2.问题对答 Q1:简单概况一下两段实习主要做的工作。【业务细节】 Q2:你在中国建行这段实习中,有遇到什么样的困难吗?【业务细节】 Q3:你是如何解决这些困难的,或者说如何培养与客户的沟通能力呢?【岗
-
通过套接字Java发送字节数组、字符串和字节
我需要通过Java socket发送一个文本消息到服务器,然后发送一个字节数组,然后是一个字符串等等。到目前为止,我所开发的内容还在工作,但客户端只读取发送的第一个字符串。 从服务器端:我使用发送字节数组,使用发送字符串。 问题是客户机和服务器不同步,我的意思是服务器发送字符串然后字节数组然后字符串,而不等待客户机消耗每个需要的字节。 我的意思是情况不是这样的:
-
从字节数组中删除前16个字节
问题内容: 在Java中,如何获取byte []数组并从数组中删除前16个字节?我知道我可能必须通过将阵列复制到新阵列中来执行此操作。任何例子或帮助将不胜感激。 问题答案: 参见Java库中的类:
-
字节vs字节数组在Python 2.6和3中
问题内容: 我正在Python中测试vs。我不明白某些差异的原因。 一个迭代器返回的字符串: 给出: 但是迭代器返回s: 给出: 为什么会有所不同? 我想编写可以很好地转换为Python 3的代码。那么,Python 3中的情况是否相同? 问题答案: 在Python中,2.6字节只是str的别名 。 引入此“伪类型”是为了(部分地)准备要与Python 3.0转换/兼容的程序(和程序员!),在Py
-
 字节 字节云 测试开发 面经 社招
字节 字节云 测试开发 面经 社招部门:字节云 岗位:测试开发 社招 3年 有点紧张 流程 1自我介绍 2你未来岗位有啥要求?(给我问懵逼了)为啥想要离职? 3以下问题偏测试(没问项目,可能项目差异太大了) 如何提升产品质量之类 你负责的产品质量怎么样 自动化有啥好处? 4编程语言python 你知道哪些类型 dict是怎么实现的 5做一个SQL题,大概用子查询吧 6编程题,最长回文子串 7你的优势,劣势 许愿,梦想还是
-
jupyterlab互动情节
问题内容: 我正在使用Jupyter笔记本中的Jupyterlab。在我以前使用的笔记本中: 用于交互式地块。现在给我(在jupyterlab中): 我还尝试了魔术(安装了jupyter-matplotlib): 但这只是返回: 内联图 工作正常,但我想要交互式地块。 问题答案: 完成步骤 1. 安装nodejs,例如。 2. 安装ipympl,例如。 3. [可选,但推荐;更新JupyterLa
-
多节点环境中的计划作业
我正在进行一项预定的工作,该工作将以一定的间隔运行(例如每天下午1点),通过Cron安排。我正在使用Java和Spring。 编写计划作业非常简单 - 它确实如此:从db中抓取人员列表将某些条件,为每个人做一些计算并触发消息。 我正在本地和测试中开发单节点环境,但是当我们投入生产时,它将是多节点环境(带有负载均衡器等)。我关心的是多节点环境会如何影响计划的作业? 我的猜测是,我可能(或很可能)最终
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
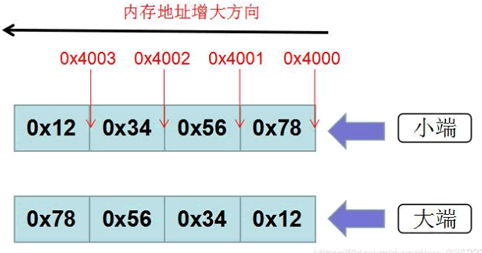 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x