《字节跳动日常实习》专题
-
 javascript实现文字无缝滚动
javascript实现文字无缝滚动本文向大家介绍javascript实现文字无缝滚动,包括了javascript实现文字无缝滚动的使用技巧和注意事项,需要的朋友参考一下 效果如图: html:( 一个div 包裹两个ul ) js代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
 Java实现动态数字时钟
Java实现动态数字时钟本文向大家介绍Java实现动态数字时钟,包括了Java实现动态数字时钟的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Java实现动态数字时钟的具体代码,供大家参考,具体内容如下 构建: Clock继承 JFrame 为运行页面 ClockText 测试类 创建 Clock 对象 运行效果: 具体实现: 一、Clock类 四个JPnal 三个放时间 最后一个放日期 放时间的三个JP
-
vue实现数字滚动效果
本文向大家介绍vue实现数字滚动效果,包括了vue实现数字滚动效果的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了vue实现数字滚动的具体代码,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
Alexa For Business Private Skill不会出现在日常活动中
我通过alexa for business organization成功发布了一项个人技能。 如本文所述:https://docs.aws.amazon.com/a4b/latest/ag/manage-users.htmlA4B用户可以使用组织中的私人技能,以便在自己的设备上使用。 事实上,我能够在我的Alexa应用程序中的“技能”下找到并启用该技能 事实上,我曾经以某种方式让它出现在一个套路中
-
jupyterlab互动情节
问题内容: 我正在使用Jupyter笔记本中的Jupyterlab。在我以前使用的笔记本中: 用于交互式地块。现在给我(在jupyterlab中): 我还尝试了魔术(安装了jupyter-matplotlib): 但这只是返回: 内联图 工作正常,但我想要交互式地块。 问题答案: 完成步骤 1. 安装nodejs,例如。 2. 安装ipympl,例如。 3. [可选,但推荐;更新JupyterLa
-
如何将字符串日期的格式设置为 yyyy-MM-dd'T'HH:mm:ss 格式为正常日期的颤动 (dart) [重复]
我只找到了与此相反的答案(正常日期为yyyy-MM-dd'T'HH:MM:ss),但在我的例子中,我有一个yyyymm-dd'T'HH:MM:ss格式的字符串,我想将其转换为日期,以便显示类似于dd/MM/yyyydy的内容。 有人知道吗?谢谢
-
swagger日期字段与日期-时间字段
我有一个java实体类TimeEntry.java它的属性之一是Date,它看起来像这样。 对于该字段,在swagger UI模型模式上,字段日期显示为“日期”:“2016-01-08T22:34:22.337Z”,但我需要该字段作为“日期”:“2016-01-08”。 我尝试了以下方法: 请帮帮忙。
-
通过分析日期字符串实现DateTimeParseException
我试图用Java解析一个日期字符串,但我得到了异常。 字符串如下所示: 我的方法是这样的: 我得到: java.time.format.DateTimeParseException:....在索引17中找到未分析的文本 有什么想法吗?:)
-
日期的字符串日期
问题内容: 如何将字符串日期格式转换为日期,我的日期字符串格式为 接下来,我没有运气尝试。 以上所有语句都给出了解析错误。 问题答案: 请阅读的文档time.Parse: 该布局通过显示参考时间(定义为 2006年1月2日星期一15:04:05-0700 如果它是值,将被解释;它用作输入格式的示例。然后将对输入字符串进行相同的解释。 所以正确的格式是
-
从docplex获取节点日志
CPLEX打印出漂亮的节点日志,如何使用docplex获取它们?我尝试过改变内容。解算器。详细和日志输出,但我没有得到要打印的信息(当前解决方案、间隙)。 我正在使用以下代码: 当verbose=5时,将打印所有分支决策(大量垃圾),而verbose=4时,不会打印间隙
-
计算复活节的日期
问题 你需要在给出的年份中找到复活节的月份和日期。 解决方案 下面的函数返回数组有两个要素:复活节的月份( 1-12 )和日期。如果没有给出任何参数,给出的结果是当前的一年。这是 在CoffeeScript 的匿名公历算法实现的。 gregorianEaster = (year = (new Date).getFullYear()) -> a = year % 19 b = ~~(year
-
无法在主节点上启动配置单元:SafeMode异常
当我在master note上运行此命令时 然而,Hadoop multinode运行良好
-
了解Java字节
问题内容: 因此,在昨天的工作中,我不得不编写一个应用程序来计算AFP文件中的页数。因此,我整理了我的MO:DCA规范PDF,找到了结构化字段及其3个字节的标识符。该应用程序需要在AIX机器上运行,所以我决定用Java编写它。 为了获得最大效率,我决定读取每个结构化字段的前6个字节,然后跳过该字段中的其余字节。这会让我: 因此,我检查字段类型,如果是,则增加页面计数器,如果不是,则不增加。然后,我
-
Concat字节数组
问题内容: 有人可以指出以下更有效的版本吗 每个变量都是一个字节片,大小不一 : 码: : 基准测试结果: 问题答案: 如果已经分配了内存,则x = append(x,a …)的序列在Go中非常有效。 在您的示例中,初始分配(制造)的成本可能比附加序列的成本高。这取决于字段的大小。考虑以下基准: 在我的盒子上,结果是: 系统地重新分配缓冲区(甚至是很小的缓冲区)会使此基准测试速度至少慢5倍。 因此
-
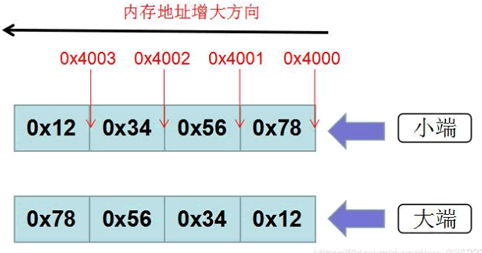 NumPy字节交换
NumPy字节交换主要内容:numpy.ndarray.byteswap()数据以字节的形式存储在计算机内存中,而存储规则可分为两类,即小端字节序与大端字节序。 小端字节序(little-endian),表示低位字节排放在内存的低地址端,高位字节排放在高地址段,它与大端字节序(big-endian)恰好相反。 对于二进制数 0x12345678,假设从地址 0x4000 开始存放,在大端和小端模式下,它们的字节排列顺序,如下所示: 图1:字节存储模式 小端存储后:0x