《数据开发工程师》专题
-
 马上着手开发 iOS 应用程序
马上着手开发 iOS 应用程序马上着手开发 iOS 应用程序 给 iOS 开发带来一个完美开局。在 Mac 上,您可以创建在 iPad、iPhone 和 iPod touch 上运行的 iOS 应用程序。本指南四个简短的部分为您构建自己的首个应用程序提供了入门指导,包括需要的工具、主要概念以及助您上路的最佳实践。
-
 给 iOS 开发者的 Sketch 入门教程
给 iOS 开发者的 Sketch 入门教程作为一名iOS开发者,我经历过几个没有设计师的项目,结果就是,痛苦的一逼。 做这种类型的项目,设计是非常重要的,特别是迭代设计。 在每个项目最开始的时候,客户其实并不知道自己想要什么。直接堆码之前我们还是有点小小的设计知识更有助于你跟客户撕逼的时候占上风,其实我们只是想更完美,难道不是吗?
-
42. IntelliJ IDEA 插件开发视频教程
重要说明 IntelliJ IDEA 的插件理论上是同时也适用于 JetBrains 公司下的其他大多数 IDE 的,因为这些 IDE 都是基于 IntelliJ IDEA 的基础平台进行开发的,请牢记这一点。 教程视频下载和介绍 视频章节结构: 01_AS插件是什么_和IntellijIDEA关系 02_常见的AS开发插件 03_创建第一个Plugin插件 04_翻译插件需求 05_翻译开发过程
-
 携程后端开发实习生二面
携程后端开发实习生二面面了接近一个小时,先自我介绍,面试官先问了几个关于业务的问题,接下来全程问操作系统相关知识,基础不扎实真是难顶,大概率是无了,不过面试官人很好,继续加油吧 面试大概内容: 1. 对chatgpt怎么看,技术层面和应用层面 2. 对互联网怎么看,以后打算去哪里发展 3. 对携程海外业务怎么看 4. 进程和线程的区别 5. 用户级线程和内核级线程的区别 6. 线程池和线程开销 7. 线程切换的到底是什
-
 太初 算法工程化工程师一面
太初 算法工程化工程师一面1自我介绍 2职业规划 3模型部署(pt转onnx转plan部署) 4讲一下transformer原理,怎么部署 5讲一下encoder decoder,哪些模型只用了其中一个? 6.拷打项目 7.平时怎么学习的 手撕 牛客链接: 判断链表是否有环 忘了快慢指针了,思路错了代码竟然跑过了(面试官说测试用例不全)hhhh。 面试官人很好,没有故意为难,但我觉得是寄了。
-
库工程 - 普通工程和库工程的区别
4.3.2 普通工程和库工程的不同 库工程的 main 输出是一个 .aar 报(这个一个标准的 Android 存档).它由编译后的代码(比如 jar 文件或者 .so 文件)以及资源文件( manifest, res, assets )组成。 库工程也可以生成一个测试apk,可以独立于应用进行测试。 它有相同的引导任务( assembleDebug , assembleRelease ),所以
-
BadPaddingException:数据必须以零开头
我用RSA实现了数据加密/解密。如果我只是在本地加密/解密,它可以工作,但是如果我发送加密的数据,我会得到BadPaddingException:数据必须从零开始。 为了通过网络发送数据,我需要在客户端将数据从字节数组改为字符串(我以报头的形式发送),然后在服务器端检索数据并将其改回字节数组。 这里是我的本地加密/解密代码(我使用私钥加密,使用公钥解密): DecryptedString和mess
-
开源数据访问组件DAC
项目描述: 数据访问组件,提供了一组类库和一个代码生成工具,使.net项目中数据访问更简化. 功能: 多种数据库支持. 提供DataSet, DataTable 和数据实体查询. 执行SQL脚本及存储过程. 条件表达式. 常用SQL方法, 如MAX, MIN等可能被应用在查询中. 数据实体代码及XML文件生成. 使用: 基本功能:1. 使用 "EntitiesGenerator" 生成工具生成实体
-
用于本地主机,开发和生产的Spring数据源配置
问题内容: 我试图弄清楚我的Spring应用程序如何确定它的部署位置并加载适当的数据源。我们有3个环境…我的本地环境,开发服务器和生产服务器。到目前为止,我有3个名为 我让他们像这样配置: 当我在本地主机上时,这工作正常。如果我将war文件部署到开发中,则它仍在读取localhost属性,因为它位于列表的最后,并且出现错误。实现此目的的最佳方法是什么? 谢谢 问题答案: 对于数据源,最简单的方法是
-
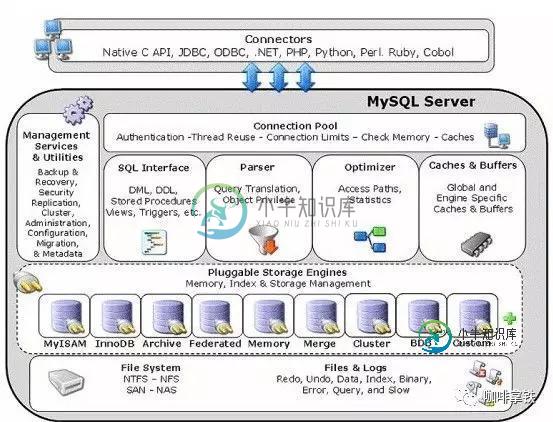 开发人员为什么必须要了解数据库锁详解
开发人员为什么必须要了解数据库锁详解本文向大家介绍开发人员为什么必须要了解数据库锁详解,包括了开发人员为什么必须要了解数据库锁详解的使用技巧和注意事项,需要的朋友参考一下 1.锁? 1.1何为锁 锁在现实中的意义为:封闭的器物,以钥匙或暗码开启。在计算机中的锁一般用来管理对共享资源的并发访问,比如我们java同学熟悉的Lock,synchronized等都是我们常见的锁。当然在我们的数据库中也有锁用来控制资源的并发访问,这也是数据库
-
如何修复 CORS 错误以提供虚假开发数据 [重复]
有没有办法避免我遇到的CORS错误? 我正在写一门关于d3的课程。我希望学生能够将JSON、CSV和其他数据加载到他们的网页。他们被指示在本地打开他们的html页面,通过右键单击并使用打开 这是提供给学生的虚假数据,仅用于开发目的。有什么方法可以改变github上dev文件的设置吗?或者有什么方法可以在本地实现? 谢谢艾玛
-
 2022/07/27 星环科技一面 (数据库开发 已感谢信)
2022/07/27 星环科技一面 (数据库开发 已感谢信)一面45min 实习数据开发 但是研究数据挖掘 有什么区别联系 实习技术栈中哪个比较熟 spark和mapreduce区别 flink和spark区别 flink窗口、状态 统计一个小时内用户点击量 端到端exactly once 水位线 savepoint checkpoint 数据量很大 只给一台机器怎么处理 热点数据怎么存 怎么判断热点数据 Java 堆内存说一下 两个线程对一个变量进行++
-
 奇瑞汽车-雄狮科技 大数据开发一面(15分钟)
奇瑞汽车-雄狮科技 大数据开发一面(15分钟)面试官是个小姐姐,很温柔 自我介绍 了解大数据组件吗 不了解 了解数据仓库吗 不了解 简单讲一下项目 rabbitMQ 在项目中怎么用的 了解kafka吗 不了解 springboot 打包方式 jar包、war包 怎么部署Linux 没部署过 说一下慢sql排查以及优化手段 慢查询日志,explain,索引
-
 银泰百货-银泰星-数据开发岗一二三面凉经
银泰百货-银泰星-数据开发岗一二三面凉经一面 30min 电话面试 非常温柔,也很有水平的面试官,主要是挖简历。 结束的时候还和我说了我的简历中可以优化的地方。体验很好。 二面 1h 视频面试 先挖简历 大概15min 问了许多机器学习和建模的知识,比如SVM、聚类一些基础模型的步骤 过拟合产生的原因以及如何解决 大概30min 根据我的本科专业背景问了一个开放问题 15min 之后闲聊了几分钟 是部门交叉面试,这位面试官是算法部门的,
-
 北京蔚来大数据开发实习一面、二面(回忆版)
北京蔚来大数据开发实习一面、二面(回忆版)个人情况简述:本硕双非,acm银牌 群友(cpp实习生)内推投递 因为是之前面的,时间也有1个多月了,可能记不太清一些细节了 一面(总时长90分钟) 聊简历项目,一个离线大数据处理项目,flume+hadoop+hive+spark+azkaban,两个后端项目 项目扣细节,主要问设计思路,比如数仓各层的设计、flume和kafka之间如何结合使用,spark的算子等 项目一共问了40多分钟 接下