《数据分析实习》专题
-
无法解析Android数据绑定类
我的布局名称是。我还看到了Android-DataBinding-绑定类将如何和何时生成?但这帮不了我。
-
带Django的Alpha Vantage API-解析数据
我正在使用django框架构建某种股票市场网络应用程序。我正在从Alpha Vantage API获取数据,但在解析所需数据时遇到了问题。 1-我可以成功调用API,但在尝试获取所需数据时总是出错(查看我在上使用的代码): 在上,我使用以下代码来显示信息或错误: 使用这段代码,我得到了以下内容,正如您所看到的,有两个独立的字典元数据和时间序列(每日): {“元数据”:{“1。信息“:”包含拆分和红
-
 JDK1.8上解析android-21数据失败
JDK1.8上解析android-21数据失败我在10.9.5 Mac OS X上,我目前在JDK 1.8上,请参阅 我尝试过切换JDK版本,也安装/卸载过eclipse、SDK和SDK工具。 在Android Studio中一切正常,但不是日食。不幸的是,我必须让它在Eclipse上工作。 感谢您对此问题的任何指点!
-
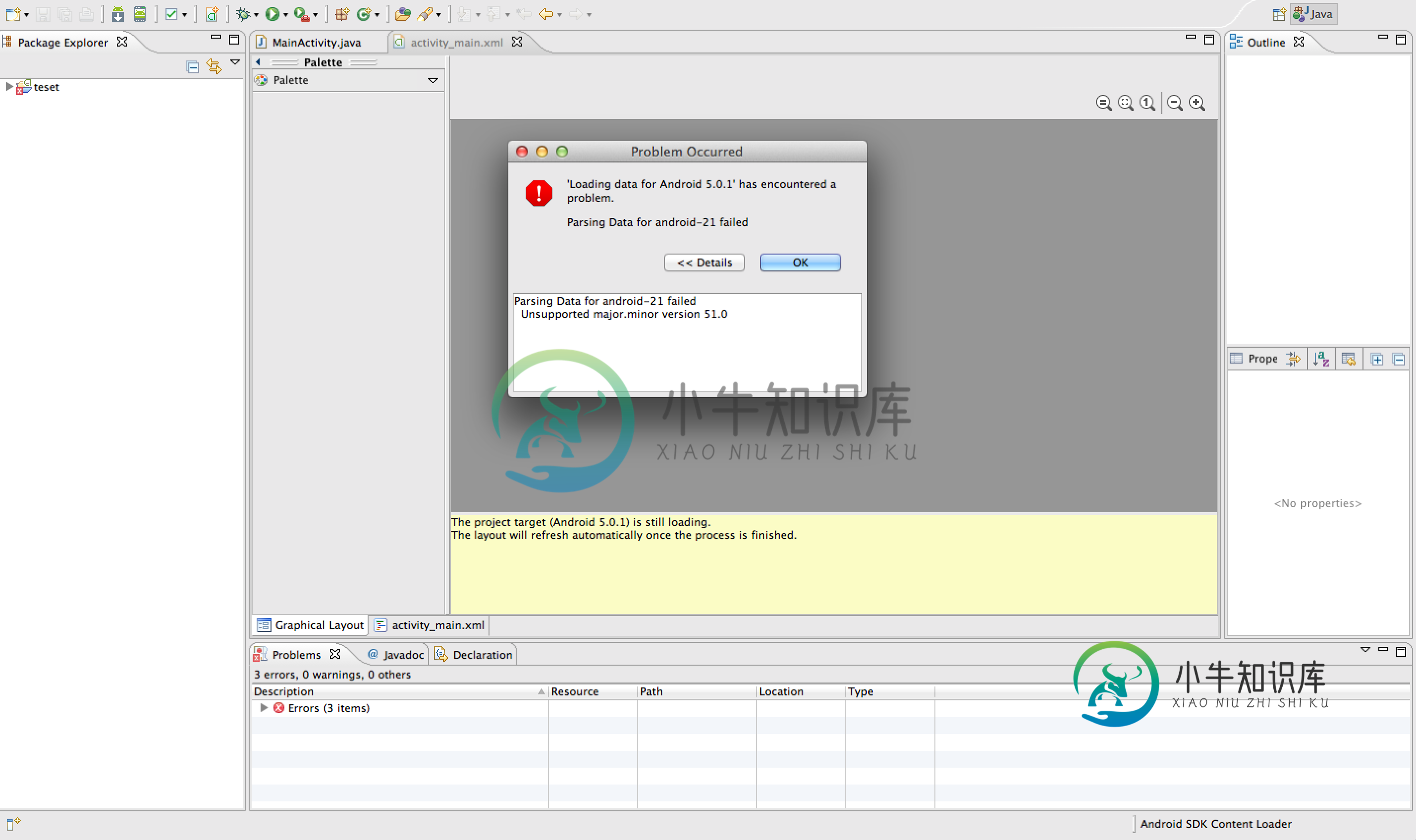
Android-“解析android-21的数据失败”
安装Android 5.0(SDK 21)后,在Eclipse中出现以下错误 “Android5.0加载数据”遇到问题了。 分析android-21的数据失败 不受支持的专业。次要版本51.0
-
Android应用程序解析json数据
您好,我有这个代码,我想将此数据解析为对象,现在我得到了一个 anyType 的字符串 我想分别得到描述对象纬度对象和经度对象
-
顶点位置数据解析渲染
如果你没有WebGL基础,可以先不用记忆每个的threejs 具体内容,有一个大致印象即可,学习本节课的重点是建立顶点的概念。如果你建立了顶点的概念,那么对于你深入理解学习Three.js很有帮助。 如果你已经有WebGL基础或者说图形学基础,说明你肯定有顶点的概念,本节课重点可以放在学习threejs的API使用细节,threejs引擎是如何封装webgl的。 JavaScript类型化数组 本
-
 百融-数分实习面经,找不到实习版
百融-数分实习面经,找不到实习版1. bagging和boosting(集成学习) 2. xgboost和lightgbm的涉及哪些参数,防止过拟合怎么调参 3. sql执行计划,追问spark的rdd是什么,rdd是否可变,spark是否惰性运算等 4. sql优化是否了解,平常怎么做sql优化的 5. transformer原理 6. 用过哪些深度学习模型 7. pandas的细节(numpy,df.a.values是np.
-
PHP中数据库单例模式的实现代码分享
本文向大家介绍PHP中数据库单例模式的实现代码分享,包括了PHP中数据库单例模式的实现代码分享的使用技巧和注意事项,需要的朋友参考一下 首先我们要知道明确单例模式这个概念,那么什么是单例模式呢? 单例模式顾名思义,就是只有一个实例。 作为对象的创建模式, 单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类我们称之为单例类。 单例模式的要点有三个: 一是某个类只能有一个
-
PHP实现根据数组的值进行分组的方法
本文向大家介绍PHP实现根据数组的值进行分组的方法,包括了PHP实现根据数组的值进行分组的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现根据数组的值进行分组的方法。分享给大家供大家参考,具体如下: PHP根据数组的值分组,php array中没有自带这个函数但是很常用,今天写了出来记录一下。 代码: 运行结果如下: 更多关于PHP相关内容感兴趣的读者可查看本站专题:《PHP
-
C#基于数据库存储过程的AJAX分页实例
本文向大家介绍C#基于数据库存储过程的AJAX分页实例,包括了C#基于数据库存储过程的AJAX分页实例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#基于数据库存储过程的AJAX分页实现方法。分享给大家供大家参考。具体如下: 首先我们在数据库(SQL Server)中声明定义存储过程 因为是直接访问数据库的,所以我们将下面这条方法写入到DAL层中,这里我将它写入到SqlHelper中
-
持久化分离实体时,Spring数据JPA审核失败
我已经使用Spring Data JPA AuditingEntityListener和AuditorAware bean设置了JPA审计。我想要的是即使在具有预定义标识符的实体上也能够持久化审计师详细信息。问题是,当具有预定义id的JPA实体被持久化和刷新时,它的审计师详细信息无法持久化: 对象引用未保存的临时实例-在刷新之前保存临时实例:me。审计道。审计详情 有趣的是,当保存具有生成id的实
-
降维 - PCA(主成分分析)
1 主成分分析原理 主成分分析是最常用的一种降维方法。我们首先考虑一个问题:对于正交矩阵空间中的样本点,如何用一个超平面对所有样本进行恰当的表达。容易想到,如果这样的超平面存在,那么他大概应该具有下面的性质。 最近重构性:样本点到超平面的距离都足够近 最大可分性:样本点在这个超平面上的投影尽可能分开 基于最近重构性和最大可分性,能分别得到主成分分析的两种等价推导。 1.1 最近重构性
-
Python中的主成分分析
问题内容: 我想使用主成分分析(PCA)进行降维。是否已经有numpy或scipy,或者我必须使用自己滚动? 我不只是想使用奇异值分解(SVD),因为我的输入数据具有很高的维数(约460个维数),因此我认为SVD比计算协方差矩阵的特征向量要慢。 我希望找到一个预制的,已调试的实现,该实现已经对何时使用哪种方法以及哪些可能进行的其他优化进行了正确的决策,而这些优化我都不知道。 问题答案: 您可以看看
-
快速排序:分区分析
我正在学习快速排序在第四算法课程,罗伯特塞奇威克。 我想知道quicksort代码的以下分区是长度为n的数组中比较的个数。
-
拆分pyspark数据帧列并限制拆分
我有下面的spark数据框架。 我必须将上面的数据帧列拆分为多个列,如下所示。 我尝试使用分隔符进行拆分;和限制。但是它也将主题拆分为不同的列。姓名和年龄被组合在一起成一列。我要求所有主题在一列中,只有姓名和年龄在单独的列中。 这在Pyspark有可能实现吗?