《欢聚时代》专题
-
Oracle聚合功能分配金额
问题内容: 假设我有2张表,如下所示 : : 表格中的每个记录代表一个袋子及其容量,这里我有5个袋子。我想编写一个将表中的项目分配到具有相同类型的每个包中的SQL ,即结果应如下所示 因此, 我正在寻找某种聚合函数,我们称其为,它可以产生如上的列。我猜想,如果存在,它可能会像这样使用 我当前的解决方案是使用临时表和PL / SQL循环进行计算,但是我希望我可以使用一个简单的SQL来实现。 问题答案
-
Django 1.11注释子查询聚合
问题内容: 这是我目前最喜欢使用的一项前沿功能,并且很快就会消失。我想将子查询聚合注释到现有查询集上。在1.11之前执行此操作意味着自定义SQL或修改数据库。这是this的文档以及其中的示例: 他们在总体上进行注释,这对我来说似乎很奇怪,但是无论如何。 我正在为此而苦苦挣扎,所以我将其沸腾回到我拥有数据的最简单的真实示例中。我有,其中包含许多Space。使用会使你更快乐,但是-暂时-我仅想使用 注
-
解释Spark中的聚合功能
问题内容: 我正在寻找有关通过python中的spark可用的聚合功能的更好解释。 我的示例如下(使用来自Spark 1.2.0版本的pyspark) 输出: 我得到的预期结果是和4个元素的总和。如果我将传递给聚合函数的初始值更改为from, 则会得到以下结果 输出: 该值增加9。如果将其更改为,则该值为,依此类推。 有人可以向我解释该值是如何计算的吗?我希望该值增加1而不是9,希望看到相反的值。
-
MongoDB聚合分组多个结果
本文向大家介绍MongoDB聚合分组多个结果,包括了MongoDB聚合分组多个结果的使用技巧和注意事项,需要的朋友参考一下 要聚合多个结果,请在MongoDB中使用$group。让我们创建一个包含文档的集合- 在find()方法的帮助下显示集合中的所有文档- 这将产生以下输出- 以下是汇总组多个结果的查询- 这将产生以下输出-
-
使用Java 8流聚合信息
我仍在努力完全掌握如何使用Java 8中的流包,并希望得到一些帮助。 我有一个类,如下所述,我在列表中接收到作为数据库调用一部分的实例。 为了生成一些可能有用的信息,我有一个类,它保存所有访问的总和(在给定的时间范围内): 我希望构建一个列表 有没有一种方法可以在单个操作中使用流来实现这一点?或者我是否需要将其分解为多个操作?我能想到的最好方法是: 并计算误差 并将这两张地图合并,得出我要查找的列
-
聚合物-webpack-loader:如何导入
我对Polymer和Webpack都是新手,正在尝试解决如何让Polymer Webpack loader正确传输。根据新的聚合物3。x将HTML导入JS的方式(Polymer 2.x是另一种方式),我创建了一个单独的。html文件,并试图将其导入我的“extends Polymerement”类。 这是我的简单template.html文件: 这是我的聚合物指数。js文件: 这是我的webpac
-
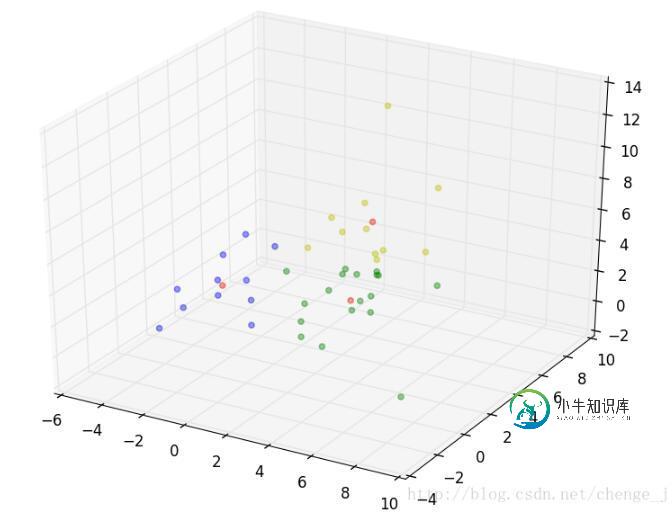 python实现k-means聚类算法
python实现k-means聚类算法本文向大家介绍python实现k-means聚类算法,包括了python实现k-means聚类算法的使用技巧和注意事项,需要的朋友参考一下 k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法。 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重
-
子聚合导致数据丢失
问题内容: 简而言之,问题 :执行带有子聚合的查询时,内部聚合为什么在某些情况下会丢失数据? 详细问题 :我有一个带有子聚合(存储桶中的存储桶)的搜索查询,如下所示: 如果我执行此查询,对于某些external_docs,我不会收到与之关联的所有inner_docs。在下面的输出中,有三个用于外部文档key_1的内部文档。 现在,我添加了一个查询,以单选一个反而应该在前20个中使用的externa
-
Elastic Search 6嵌套查询聚合
问题内容: 我是elasticsearch查询和聚合的新手。我有一个带有以下映射的嵌套文档 我已插入示例数据,如下所示 我如何为以下内容构建查询DSL 员工人数最多的部门 大多数部门的员工 我正在使用Elastic Search 6.2.4 问题答案: 您的第一个问题答案是在此链接中嵌套的内部文档数哪个统计信息 这回答了您的第二个问题,同时也阅读了链接。 阅读嵌套的Agg 我希望这能给您您所需要的
-
Maven JavaDoc插件:聚合依赖项
我试图编译JavaDocs,使用: 我不断出现以下错误: 和 显然,我对多模块/聚合项目的依赖性没有得到认可。在我的一个模块pom中,这两个都标记为依赖项。xml文件。我需要在父pom中为maven javadoc plugin提供额外的参数吗。xml? 编辑: 我运行了mvn安装,它似乎可以工作。我的父母是pom。xml是: 这个版本已经过时了,但这似乎不是问题。
-
如何在org.springframework.data.elasticsearch.core.FacetedPage中获取聚合
我必须在弹性搜索中使用聚合执行搜索。因为刻面将在不久的将来被删除,所以我不能使用刻面。 当然,我被鼓励使用聚合。 下面的代码给了我想要的输出: 聚合聚合=elasticsearch chTemplate.query(搜索查询,新的结果提取器(){@覆盖公共聚合提取(搜索响应响应){返回response.get聚合(); 但问题是,它成为了我的弹性搜索查询之外的第二个查询,这使得它变得非常慢。 我正
-
两项聚合后的ElasticSearch顺序
假设我在ES中有以下文档,每个文档都有3个字段:f1、f2和分数。我想找到所有文档,按f1、f2分组,按组最大分数排序,在SQL我可以简单地这样做: elasticsearch中的等价物是什么?嵌套术语聚合不会给出正确的顺序,因为返回的f2术语桶都嵌套在同一个f1术语桶中。
-
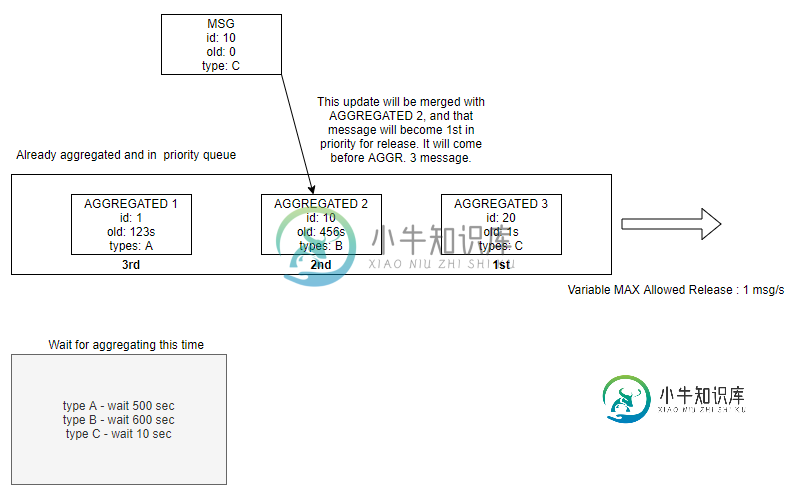 Spring集成-优先级聚合器
Spring集成-优先级聚合器我有以下应用程序要求: 从RabbitMq接收消息,然后根据一些更复杂的规则进行聚合,例如基于属性(具有预先给定的类型时间映射)和基于消息在队列中等待的现有时间(属性) 正如您在图中看到的一个用例:三条消息已经聚合并等待下一秒发布(因为当前速率为),但就在那时,以到达,并更新了,使其成为优先级最高的第一条消息。因此,在下一个选项中,我们不再发布聚合3,而是发布聚合2,因为它现在具有更高的优先级。
-
Java中对象的聚合列表
我们在Java中有任何聚合器函数来执行下面的聚合吗?
-
Apache Flink自定义窗口聚合
我想将一个交易流聚合成相同交易量的窗口,这是区间内所有交易的交易规模之和。 我能够编写一个自定义触发器,将数据分区到Windows中。代码如下: 上面的代码可以将其划分为大致相同大小的窗口: 现在我喜欢对数据进行分区,以便卷与触发器值完全匹配。为此,我需要稍微修改一下数据,方法是将区间结束时的交易分成两部分,一部分属于正在触发的实际窗口,剩余的超过触发器值的数量必须分配给下一个窗口。 那可以用一些