《欢聚时代》专题
-
事件时间上的聚合函数和过程函数
在这里输入代码需要在kafka流中使用flink和out聚合数据值放一个新的主题。 聚合应该发生在eventtime,而不是进程时间,这意味着数据对象中的时间戳。 遵循Flink教程中的示例,使用TumblingEventTimeWindow,但根本不调用聚合getResult方法。 如果我更改为TumblingProcessingTimeWInow,getResult将被调用并将结果下沉。 由于
-
通过 Junit 执行测试时生成 Serenity 聚合报告
我正在使用Junit运行cucumber宁静测试: 代码片段: 对于每个测试执行,都会生成单独的html报告,但不会直接使用HtmlAggregate StoryReport生成聚合(组合)报告(参考:https://github.com/serenity-bdd/serenity-core/issues/244) 这是我使用的代码片段,它被挂起并且聚合未完成。在所有cucumber宁静测试完成后
-
Python Pandas:将datetime列分组为小时和分钟聚合
这似乎是一个相当直接的前进,但几乎一整天后,我没有找到解决办法。我已经用read_csv加载了我的数据帧,并且很容易地将日期和时间列解析、组合和索引到一个列中,但是现在我希望能够根据小时和分钟分组来重新塑造和执行计算,类似于您可以在excel Pivot中所做的。 我知道如何重新采样到小时或分钟,但它维护与每个小时/分钟相关联的日期部分,而我只想将数据集聚合到小时和分钟,这类似于在excel数据透
-
停止JTable仅在聚焦并按下键时可编辑
我编写了一个自定义的,这样当我键入示例的列时,除了数字之外什么都不能输入。 如果用户单击单元格一次,然后开始键入,同时仍然允许用户双击单元格开始编辑,我如何防止用户能够编辑单元格?
-
执行聚合时如何获得搜索点击结果?
在Elasticsearch中,您可以执行返回点击的搜索,同时在一个响应中返回与点击分开的聚合结果。这是非常强大和有效的,因为您可以运行查询和多个聚合,并一次获得两个(或其中一个)操作的结果,避免使用简洁和简化的API进行网络往返。 我想执行搜索,当我对聚合有查询时返回点击。但我不确定如何才能做到以上几点? 我正在使用以下查询:
-
什么时候提高程序内聚会恶化耦合?
我最近参加了一次设计原理考试 据我所知,内聚性是指一个类/模块如何专注于解决它创建时要解决的问题,或者更好地说,它在完成it工作方面有多出色。它做了不该做的工作吗?然后将该部分移动到另一个类/模块。 耦合是许多类/模块之间的依赖程度。这意味着,无论我们是否对不同的模块/类进行重大更改,一个好的类/模块都会起作用。 我曾经这样向自己解释:调酒师的工作是煮咖啡和其他饮料。一个好的调酒师应该做好自己的工
-
在视区上显示聚焦的DIV&使用纯普通JavaScript在滚动时隐藏未聚焦的DIV
我正在使用纯普通JavaScript创建一个HTML表单,其效果与SurveyMonkey.com/r/online-product-feedbed-survey-template-new类似 我想实现的是让我的表单题的不透明度变轻,让一个屏幕上的题不透明度:0;以便在上下滚动时,从用户获得焦点并使该表单的所有其他问题变暗,这将是完全可见的。 为此,我尝试了我的代码后,从不同的资源得到不同的提示,
-
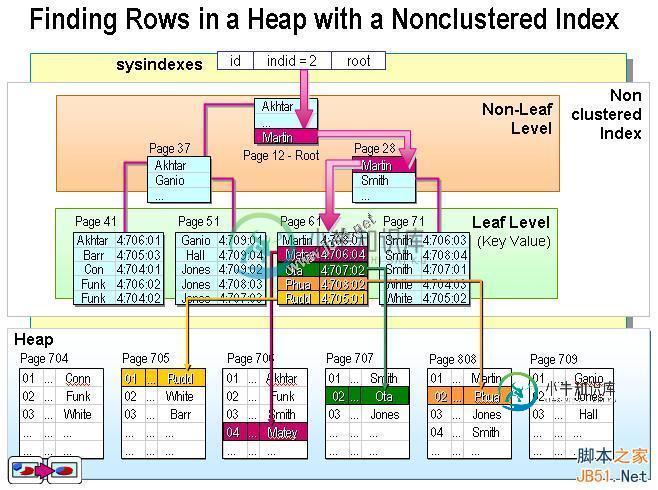 sql 聚集索引和非聚集索引(详细整理)
sql 聚集索引和非聚集索引(详细整理)本文向大家介绍sql 聚集索引和非聚集索引(详细整理),包括了sql 聚集索引和非聚集索引(详细整理)的使用技巧和注意事项,需要的朋友参考一下 聚集索引 一种索引,该索引中键值的逻辑顺序决定了表中相应行的物理顺序。 聚集索引确定表中数据的物理顺序。聚集索引类似于电话簿,后者按姓氏排列数据。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索
-
应用聚合后过滤elasticsearch中的术语聚合桶
以下是数据集的快照: 我想获得员工名单以及employeeStatus和employeeAddr。 所以我在employeeId上使用术语聚合,然后使用employeeStatus和employeeAddr的子聚合来获得这些详细信息。下面的查询正确返回结果。 现在我只想要永久身份的员工。所以我正在应用过滤器聚合。 现在的问题是雇员地址聚合没有为雇员地址返回存储桶,因为记录2在聚合完成之前就被过滤掉
-
获取最大术语桶聚合(使用管道聚合)
我想知道如何在Elasticsearch中使用聚合时获得具有最高doc_count的存储桶。我正在使用Kibana示例数据kibana_sample_data_flights: 如果有一个存储桶具有最大文档计数,我可以将术语聚合的大小设置为1,但是如果有两个存储桶具有相同的最大文档计数,则这不起作用。 自从我涉足管道聚合以来,我觉得应该有一种简单的方法来实现这一点。最大桶聚合似乎能够处理多个最大桶
-
python中kmeans聚类实现代码
本文向大家介绍python中kmeans聚类实现代码,包括了python中kmeans聚类实现代码的使用技巧和注意事项,需要的朋友参考一下 k-means算法思想较简单,说的通俗易懂点就是物以类聚,花了一点时间在python中实现k-means算法,k-means算法有本身的缺点,比如说k初始位置的选择,针对这个有不少人提出k-means++算法进行改进;另外一种是要对k大小的选择也没有很完善的理
-
Java 聚合与构成
问题内容: 我很难理解UML中的组合和聚合之间的区别。有人可以给我一个很好的比较和对比吗?我也很想学习识别代码之间的区别和/或看一个简短的软件/代码示例。 编辑:我问的部分原因是因为我们在工作中正在进行反向文档活动。我们已经编写了代码,但是我们需要返回并为代码创建类图。我们只想正确捕获关联。 问题答案: 聚集与构成之间的区别取决于上下文。 以另一个答案中提到的汽车示例为例-是的,确实汽车尾气可以“
-
Python Pandas聚合函数
主要内容:应用聚合函数在《 Python Pandas窗口函数》一节,我们重点介绍了窗口函数。我们知道,窗口函数可以与聚合函数一起使用,聚合函数指的是对一组数据求总和、最大值、最小值以及平均值的操作,本节重点讲解聚合函数的应用。 应用聚合函数 首先让我们创建一个 DataFrame 对象,然后对聚合函数进行应用。 输出结果: 1) 对整体聚合 您可以把一个聚合函数传递给 DataFrame,示例如下: 输出结果: 2)
-
Neo4j中的聚集图
我手头有多个Neo4j图,比如G1、G2和G3。如何有效地将所有图迁移到一个图中。在图中,G1、G2和G3具有标签G1、G2和G3,并且从不相互连接。 我使用Neo4j 2.3,但3.0也将被考虑。 谢谢 编辑 好的。我实际上使用的是Spring Date Neo4j,它很难连接到多个Neo4j实例。所以我决定把所有的图放到一个实例中,用标签来区分它们。这够清楚了吧?
-
MongoDB聚合、MongoDB查询
我使用Nodejs和MongoDB与expressjs和mongoose库,创建一个具有用户、文章和评论模式的博客API。下面是我使用的模式。