《数据分析面经》专题
-
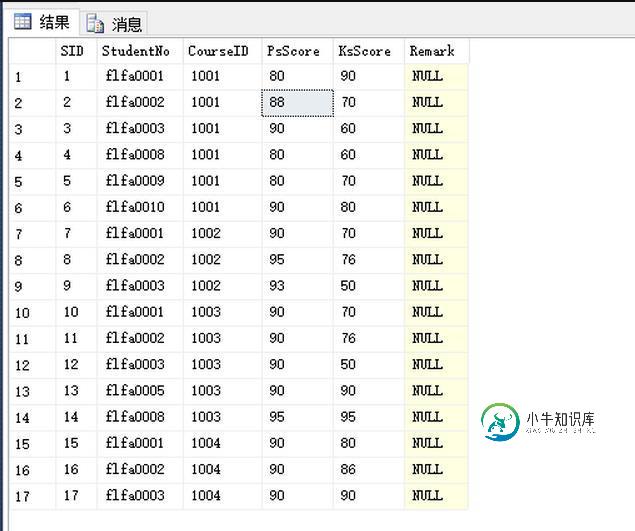 SQL数据分页查询的方法
SQL数据分页查询的方法本文向大家介绍SQL数据分页查询的方法,包括了SQL数据分页查询的方法的使用技巧和注意事项,需要的朋友参考一下 最近学习了一下SQL的分页查询,总结了以下几种方法。 首先建立了一个表,随意插入的一些测试数据,表结构和数据如下图: 现在假设我们要做的是每页5条数据,而现在我们要取第三页的数据。(数据太少,就每页5条了) 方法一: 结果: 此方法是先取出前10条的SID(前两页),排除前10条数据的S
-
Angularjs数据表服务器端分页
我试图使Angularjs服务器端分页在这个链接https://l-lin.github.io/angular-datatables/#/serverSideProcessing 所以我用这个暗号 我在dataSrc参数中手动添加了recordsTotal、recordsFiltered和row 这是添加recordsTotal、recordsFiltered和row之前和之后的json数据 添加
-
在数据帧上按操作分组
我有一个熊猫数据框,如下所示。 我根据按数据帧分组。分组数据框在概念上如下所示。 现在,我正在寻找一个内置API,它将给我最大作业数的。对于上面的示例,-2具有最大计数。 更新:我希望具有最大作业计数,而不是具有最大作业计数的。对于上述示例,如果,则输出为。这能做到吗?
-
SQL:聚合函数和分组依据
问题内容: 考虑Oracle表。我想用顶薪与获得职工和。还假定没有“ empno”列,并且主键涉及许多列。您可以使用以下方法执行此操作: 这可行,但我必须重复测试deptno = 20和job =’CLERK’,这是我想避免的。有没有更优雅的方式编写此代码,也许使用?顺便说一句,如果这很重要,我正在使用Oracle。 问题答案: 以下内容经过了精心设计,但对于“ top x”查询而言,这是一个很好
-
Python-将行拆分为列-csv数据
正在尝试从csv文件中读取数据,将每行拆分为各自的列。 但是,当某个列本身带有逗号时,我的正则表达式就失败了。 例如:a, b, c,"d, e, g,", f 我想要的结果是: 也就是5列。 下面是用逗号分隔字符串的正则表达式am ,(?=(?:“[^”]?(?:[^”])*)),(?=[^”](?:,),$) 但是它对少数字符串失败,而对其他字符串有效。 我想要的是,当我使用pyspark将c
-
将数据分组后筛选行[duplicate]
我有下面的数据 我必须根据(a)列对数据进行分组,然后我必须删除具有相同(b)值的行。下面我展示了它应该是什么样子, 熊猫有什么简单的方法可以做到这一点吗?
-
狂饮6发送多部分数据
我想向Guzzle Http请求添加一些数据。有文件名、文件内容和带有授权密钥的头。 但我得到错误 可捕获的致命错误:传递给guzzle http \ PSR 7 \ multipart stream::add element()的参数2必须是数组类型,字符串给定,在vendor \ guzzle http \ PSR 7 \ src \ multipart stream . PHP的第70行调用
-
用DPLYR向分组数据添加行?
我试过了 但这行不通。在我最初的方法中,我通过将每周编号1-4的dataframe与我的rawdata文件合并来解决这个问题。这样,我每篇文章有4周的时间(行),但是使用for循环的实现效率非常低,所以我试图用dplyr(或任何其他更高效的包/函数)做同样的事情。任何建议都将不胜感激!
-
火花分区数据多个文件
我有5个表存储为CSV文件(A.CSV、B.CSV、C.CSV、D.CSV、E.CSV)。每个文件按日期分区。如果文件夹结构如下:
-
Spring数据JPA。子实体的分页
我在Spring boot版本1.3.6中使用Spring Data JPA。 null 这将返回父实体,而不是子实体。 知道怎么做吗?
-
JSOUP+多部分/表单-数据响应
通常,我需要通过JSOUP将数据以响应multipart/form-data的形式发送到站点 作为一个示例,使用一个简单的窗体来sgeniriruet您的查询。 <表单操作=«localhost:8000»方法=«post»enctype=»多部分/表单数据» <输入类型=»文本»名称=»文本»值=»文本默认值» <输入类型=»文件»名称=»文件1» <输入类型=»文件»名称=»文件2» 提交 通
-
多部分/表格数据邮递员
如何使用POSTMAN对具有自定义头的多部分/表单数据进行测试,以2个文件为参数的控制器()?
-
Oracle分层数据的JPA/Hibernate map@OneTomany
我知道可能的性能问题,但是我们可以使用Hibernate/JPA映射类似的东西吗?
-
Apache Spark中数据分区的控制
输出应类似于: [ {col1:row1,col2:row1:col3:row1:col4:row1}, {col1:row2,col2:row2:col3:row2:col4:row2}, {col1:row3,col2:row3:col3:row4:row3}, {col1:row4,col2:row4:row4},... ] 我尝试使用spark中可用的repartion(num),但它并不
-
Apache Spark中的分层数据操作
我在Spark(v2.1.1)中有一个数据集,其中有3列(如下所示)包含分层数据。 我的目标是根据父子层次结构为每一行分配增量编号。从图形上可以说,分层数据是树的集合 根据下表,我已经根据“Global_ID”对行进行了分组。现在,我想以增量顺序生成“值”列,但基于“父”列和“子”列的数据层次结构 表格表示(值是所需的输出): 树形表示(每个节点旁边都显示了所需的值): 代码片段: 经过大量研究并