《大数据开发》专题
-
为什么抵达率会有大于100%的数据出现
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么抵达率会有大于100%的数据出现 抵达率的计算方法为访问次数比上点击数,如有无效点击,点击会被过滤掉不计费,但是后续的PV、访问次数等数据统计会记录到,所以点击数量可能出现小于访问次数。百度统计里边的点击量和凤巢里边的点击量是一致的,都是过滤了无效点击之后的数据,但无效点击产生的访次还在,所以可能导致抵达率>100%。
-
3.6 编程案例:如何求 n 个数据的最大值?
3.6 编程案例:如何求 n 个数据的最大值? 面对复杂问题时,我们需要合理利用基本控制结构,设计出好的算法。对此,并不存在什么机械的套路可循,只能通过大量实践来提供我们的程序设计水平。本节通过一个案例问 题的解决,来展示程序设计过程的挑战性以及“好”程序的特征。 我们要解决的问题是:从 n 个数值中求出最大值。这个问题在实际中很常见——也许不 是作为独立的问题,而是作为其他复杂问题的子问题,因此
-
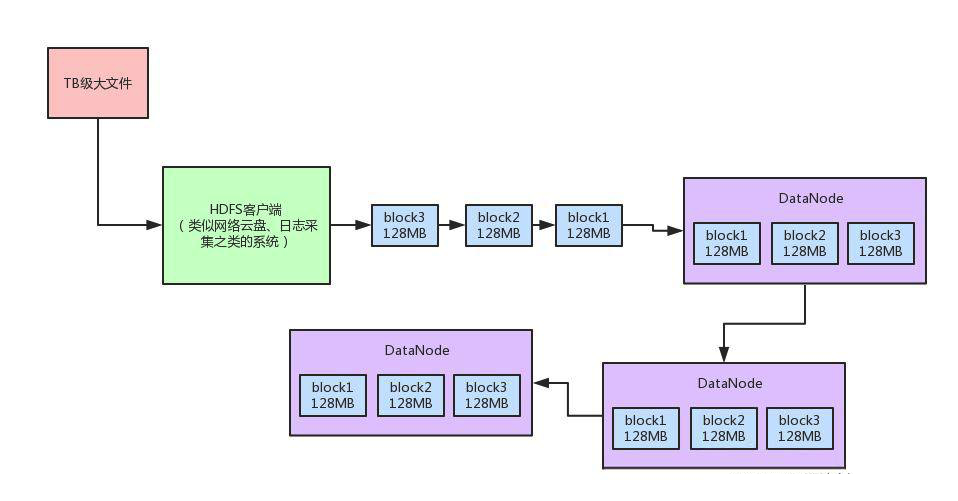 关于超大数据量的系统性能优化设计
关于超大数据量的系统性能优化设计主要内容:1、Chunk缓冲机制,2、Packet数据包机制,3、内存队列异步发送机制,总结:这篇文章,我们来聊一聊在十亿级的大数据量技术挑战下,世界上最优秀的大数据系统之一的Hadoop是如何将系统性能提升数十倍的? 首先一起来画个图,回顾一下Hadoop HDFS中的超大数据文件上传的原理。 其实说出来也很简单,比如有个十亿数据量级的超大数据文件,可能都达到TB级了,此时这个文件实在是太大了。 此时,HDFS客户端会给拆成很多block,一个block就128MB。 这个HDFS客户端
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点 hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理 hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台) 特点: 高扩容:had
-
 大数据面试题—包含真实面经(压力拉满)
大数据面试题—包含真实面经(压力拉满)从事数据开发,手写面试题5W字,涉及hadoop、zookeeper、kafka、spark、flink、clickhouse等常见的大数据中间件,文档可以后台踢我 1、Hadoop特点hadoop是一个分布式计算平台,能够允许使用编程模型在集群上对大型数据集进行分布式处理hadoop的三大组件:HDFS(分布式文件存储平台)、MR(计算引擎)、YARN(资源调度平台)特点:高扩容:hadoop在
-
根据开发者帐号查看App
如何在应用中列出自己开发的所有上线产品呢?一般作法是把上线产品放在自己的服务器上,客户端到相应的接口上取产品列表。如果没有服务器怎么办呢?而且,把产品列表放在自己的服务器上,如果有产品上线或者产品更新时,必须得在服务器上更新列表,十分麻烦。这份代码是通过开发者账号直接从appstore上获取开发者上线产品的信息。并且点击相应产品,直接跳转到itunes下载页面。 [Code4App.com]
-
R: 查找数据帧列中大于或等于其他数据帧列的行值的最小值
第一次问问题(温柔点),因为我还没有找到任何有用的东西。 在R中,我有两个数据帧。一个(DataFrameA)有一列带有唯一日期列表。另一个(DataFrameB)也有日期列表。但是DataFrameB中的某些日期在DataFrameA中可能不存在。在这种情况下,我想将DataFrameB中的日期更新为DataFrameA中的最小日期,该日期大于DataFrameB中的日期。 在SQL中,我可能会
-
宇宙数据库能否以批大小从文件 Blob 或 Csv 或 Json 文件中读取数据?
我目前正在研究使用cosmos db读取数据,基本上我们目前的方法是使用带有Cosmos DB SDK的.Net Core C#应用程序从文件blob或csv或json文件中读取整个数据,然后使用for循环,逐个从cosmos db中提取其信息并比较/插入/更新, 这在某种程度上感觉效率低下。 我们很好奇 cosmos DB 是否可以执行从文件 blob 或 csv 或 json 文件以及类似 S
-
为什么分报告中不同维度的数据相加会大于网站概况的数据
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么分报告中不同维度的数据相加会大于网站概况的数据 每个报告的分析维度不同,因此去重逻辑也不同。网站概况,以及趋势报告中的数据是以整个站点为维度去重的,是了解站点整体流量和访问量的地方。 例如:访客 X 通过百度搜索进入网站后又通过直接访问进入网站,此时,“搜索引擎”报告和“直接访问”报告会各记录一个独立访客数据,但是网站概况中只会记录一个独立访客数
-
_GET中的URL参数的最大大小
问题内容: 我正在使用REST访问PHP服务器:所有数据都作为URL参数在GET请求中传递。参数之一以query_string到达服务器,但不在_GET全局中。但是,缩短参数(截止值似乎是512个字符左右)可以让它通过。 假设我已正确诊断问题,是否可以更改此最大大小?我在文档中没有找到任何解释,甚至没有提及此限制。这是在Debian挤压/ Apache 2.2.16 / PHP 5.3.3上。 问
-
大数上的最大素因子失败
我在研究Euler项目的问题,这是问题五: 最大素因子问题3 13195的素因子为5、7、13和29。 600851475143的最大质因数是什么? 我得到了工作代码: 因数(19*19*19*19*19*19*19*19*19*1999989899) x=33170854034208712,最后一个系数=182128674 33170854034208712 有人知道为什么这没有得到正确的答案吗
-
滑动删除在大多数情况下不起作用,它会从视图中删除数据,但不会从SQLite数据库中删除数据
我是一个初学者开发人员。我的应用程序中有一个SQLite数据库。我已经成功地为其添加了添加、删除和更新功能。我现在正在尝试实现滑动删除,但是,我面临着当前的问题:有时在我滑动并删除项目后,它会成功删除(从数据库中),有时不会,有时会删除上面的项目,有时会删除上面的项目2 id。我做了很多尝试和错误,但我无法确认为什么会发生这种情况。总是发生的是项目从视图中删除,因为它不再有自己的卡(我正在使用ca
-
 腾讯游戏数据科学后端开发暑假实习一面(c++)
腾讯游戏数据科学后端开发暑假实习一面(c++)1、上来先问用过哪些排序算法,然后手写快排 2、问使用过stl哪些工具,具体原理是什么 3、深挖项目1,一直问实现细节,问共享文件的修改怎么做 4、问项目2,提了他想到的一些问题,类似于同步攻击 5、场景题:100万个选手,每个选手有对应的id和分数,要求参赛选手可查询分数前100的名单,和自己的排名,ps:排名可能随时更新,可能一天是10万级的更新,因此对应的前100名单和选手排名也要更新。 时
-
 详解iOS开发中UItableview控件的数据刷新功能的实现
详解iOS开发中UItableview控件的数据刷新功能的实现本文向大家介绍详解iOS开发中UItableview控件的数据刷新功能的实现,包括了详解iOS开发中UItableview控件的数据刷新功能的实现的使用技巧和注意事项,需要的朋友参考一下 实现UItableview控件数据刷新 一、项目文件结构和plist文件 二、实现效果 1.说明:这是一个英雄展示界面,点击选中行,可以修改改行英雄的名称(完成数据刷新的操作). 运行界面: 点击选中行: 修改数
-
详解iOS App开发中session和coockie的用户数据存储处理
本文向大家介绍详解iOS App开发中session和coockie的用户数据存储处理,包括了详解iOS App开发中session和coockie的用户数据存储处理的使用技巧和注意事项,需要的朋友参考一下 NSURLSession 在iOS7之后,NSURLSession作为系统推荐使用的HTTP请求框架,在进行前台请求的情况下,NSURLSession与NSURLConnection并无太大差