《数据分析》专题
-
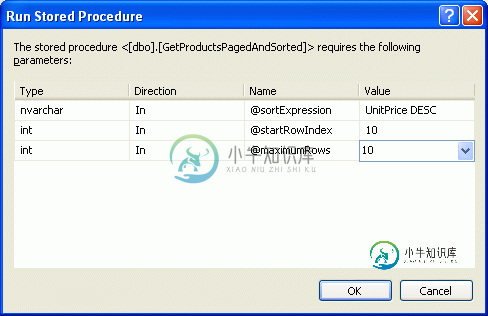 在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据
在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据本文向大家介绍在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据,包括了在ASP.NET 2.0中操作数据之二十六:排序自定义分页数据的使用技巧和注意事项,需要的朋友参考一下 导言 和默认翻页方式相比,自定义分页能提高几个数量级的效率。当我们的需要对大量数据分页的时候就需要考虑自定义分页,然而实现自定义分页相比默认分页需要做更多工作。对于排序自定义分页数据也是这样,在本教程中我们就
-
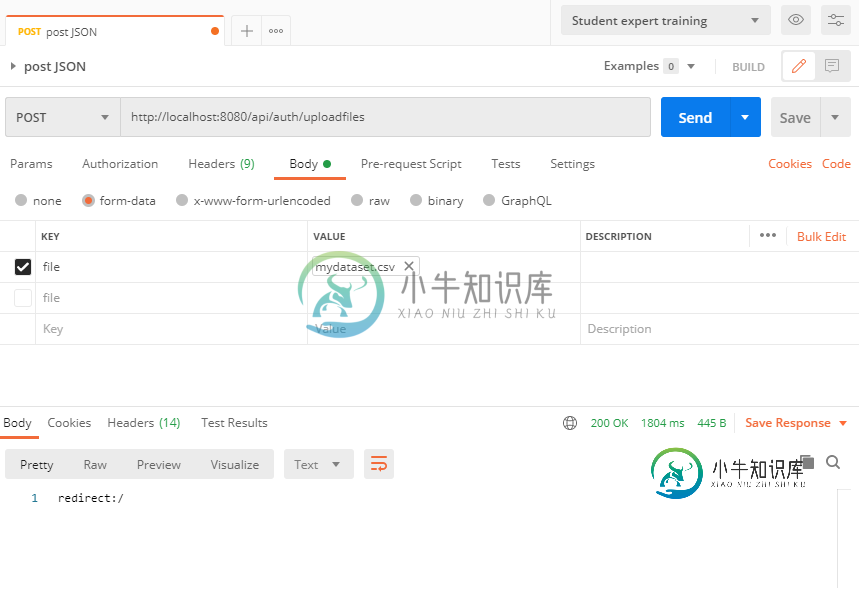 使用axios POST请求将JSON数据作为多部分/表单数据发送
使用axios POST请求将JSON数据作为多部分/表单数据发送以下API使用postman工作: Spring boot,后端代码: ReactJS,前端代码:我在中有对象数组。 触发功能的按钮: 我需要将我的前端(ReactJS)代码更改为,就像我使用postman发布请求一样。当前JS代码导致以下错误响应: Servlet。路径为[]的上下文中的servlet[dispatcherServlet]的service()引发了异常[请求处理失败;嵌套异常为o
-
将原始图像数据张贴为卷曲中的多部分/表单数据
我试图在PHP中使用multipart/form-data头发布一个带有cURL的图像,因为我发送到的API期望图像以多部分形式发送。 我没有问题与API与其他请求;只有张贴图像是一个问题。 我在客户端使用此表单: 请求头中的content-type现在显示正确了。但是图像似乎没有像API所期望的那样正确地发送。不幸的是,我无法访问API... 感谢您的帮助,谢谢
-
通过从配置单元表中读取数据创建的spark数据帧的分区数
我对spark数据帧的分区数量有疑问。 如果我有包含列(姓名、年龄、id、位置)的Hive表(雇员)。 如果雇员表有10个不同的位置。因此,在HDFS中将数据划分为10个分区。 如果我通过读取 Hive 表(员工)的整个数据来创建 Spark 数据帧(df)。 Spark 将为数据帧 (df) 创建多少个分区? df.rdd.partitions.size = ??
-
熊猫对HDFStore中的大数据进行“分组依据”查询?
问题内容: 我有大约700万行,其中有60列以上。数据超出了我的内存容量。我正在基于列“ A”的值将数据聚合到组中。熊猫拆分/汇总/合并的文档假定我已经将所有数据都存储在了,但是我无法将整个商店读取到内存中。在分组数据的正确方法是什么? 问题答案: 这是一个完整的例子。 输出量 一些警告: 1)如果您的组密度相对较低,则此方法很有意义。大约数百或数千个组。如果获得的收益更多,则效率更高(但方法更复
-
如何根据列表选择数据帧的一部分?[复制]
我有以下数据框: 我有以下一些位于美国的城市列表: 我想在数据框中只保留列表\u americ中国家的“名称”。因此,我尝试执行以下代码: 此代码产生以下错误: 我希望输出为:
-
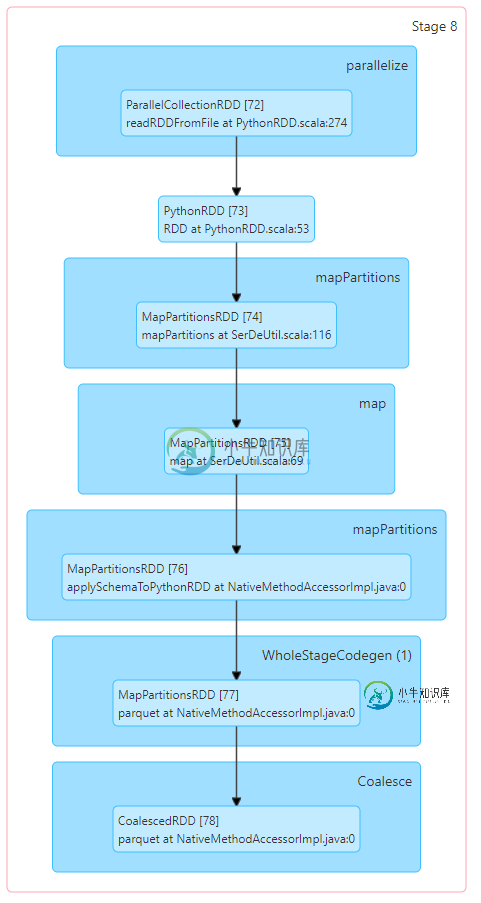 减少分区数量时,为什么spark数据帧重新分区比合并快?
减少分区数量时,为什么spark数据帧重新分区比合并快?我有一个包含100个分区的df,在保存到HDFS之前,我想减少分区的数量,因为拼花文件太小了( 它可以工作,但将过程从每个文件 2-3 秒减慢到每个文件 10-20 秒。当我尝试重新分区时: 这个过程一点也不慢,每个文件2-3秒。 为什么?在减少分区数量时,合并不应该总是更快,因为它避免了完全洗牌吗? 背景: 我将文件从本地存储导入spark集群,并将生成的数据帧保存为拼花文件。每个文件大约100
-
程序参数 - 参数分析
匹配可以用来解析简单的参数: use std::env; fn increase(number: i32) { println!("{}", number + 1); } fn decrease(number: i32) { println!("{}", number - 1); } fn help() { println!("usage: match_args <stri
-
无法分配具有形状和数据类型的数组
问题内容: 我在Ubuntu 18上在numpy中分配大型数组时遇到了一个问题,而在MacOS上却没有遇到同样的问题。 我想一个numpy的阵列形状分配内存 使用 当我在Ubuntu OS上遇到错误时 我在MacOS上没有得到它: 我读过某处不应该真正分配数组所需的全部内存,而只分配了非零元素。即使Ubuntu计算机具有64gb的内存,而我的MacBook Pro却只有16gb。 版本: PS:在
-
当分区数据从HDFS中被手动删除时,如何更新配置单元中的分区元数据
如果新的分区数据被添加到HDFS(没有alter table添加分区命令执行)。然后,我们可以通过执行命令'MSCK修复‘来同步元数据。 如果从HDFS中删除了许多分区数据,该怎么办(不执行alter table drop partition commad执行)。 如何同步配置单元元数据?
-
拆分(爆炸)熊猫数据帧字符串条目以分离行
我有一个数据框,其中一列文本字符串包含逗号分隔的值。我想分割每个CSV字段,并为每个条目创建一个新行(假设CSV是干净的,只需要在“,”上分割)。例如,应该变成: 到目前为止,我已经尝试了各种简单的函数,但是方法在轴上使用时似乎只接受一行作为返回值,并且我无法让工作。任何建议都将不胜感激! 示例数据: 我知道这是行不通的,因为我们失去了DataFrame元数据通过通过Numpy,但它应该给你一个感
-
Pyspark dataframe重新分区将所有数据放在一个分区中
我有一个具有如下模式的dataframe:
-
数据库 - 或许我们都被分库分表约束了思维?
概述 这篇文章没什么太多的干货,纯纯是一篇讨论和思考帖。 从业数据库领域三年有余了,从分库分表中间件到数据库团队内核学到了很多东西。也接触了很多项目,包括TiDB、Vitess、Polardb、StarDB等等。 国内的项目好像很多都聚焦于分库分表的概念,包括很多的数据库团队都在尝试这个概念的落地和沉溺于性能的跑分。 最近我在预览MySQL官方,看到了Partitioning的概念,而且占据了很大
-
 zijie数分
zijie数分自我介绍 介绍数模、实习的经历 问python,sql掌握情情况 5道sql,限时20min,现场使用做题窗口直接作答,非回答思路 1:row_number rank dense_rank区别——会 2-5:两个表格,主要考察时间函数(具体到年月日时分秒的时间列)、窗口函数、滑动窗口函数——比较欠缺 问数学模型的掌握情况 介绍随机森林 介绍降维方法——PCA...
-
 jsbg数分
jsbg数分自我介绍 3道sql:分性别求工资第二——排序窗口函数 行转列——sum+case...when或pivot+sum 忘了 python:查看df分布、df空值情况 统计:abtest的双总体比例的假设检验(方差公式,大样本n>30) 机器学习:kmeansk的选择 决策树(信息增益,信息增益率区别,基尼指数) 数据无量纲化(归一化,归一化的优点,什么时候需要归一化,决策树不需要归一化) 业务:销