《华为社招》专题
-
 2024年华为OD机试真题-会议室占用时间
2024年华为OD机试真题-会议室占用时间华为OD机试真题-会议室占用时间-2024年OD统一考试(D卷) 题目描述: 现有若干个会议,所有会议共享一个会议室,用数组表示各个会议的开始时间和结束时间,格式为: [[会议1开始时间,会议1结束时间],[会议2开始时间,会议2结束时间]] 请计算会议室占用时间段。 输入描述: [[会议1开始时间,会议1结束时间],[会议2开始时间,会议2结束时间]] 备注 会议室个数范围: [1,100] 会
-
 字符串序列判定 - 华为OD统一考试(D卷)
字符串序列判定 - 华为OD统一考试(D卷)OD统一考试(D卷) 分值: 100分 题解: Java / Python / C++ 题目描述 输入两个字符串S和L,都只包含英文小写字母。S长度<=100,L长度<=500,000。判定S是否是L的有效字串。 判定规则: S中的每个字符在L中都能找到(可以不连续),且S在L中字符的前后顺序与S中顺序要保持一致。 (例如,S="ace"是L="abcde”的一个子序列且有效字符是a、c、e,而”
-
 最新华为OD机试真题-字符串分割(100分)
最新华为OD机试真题-字符串分割(100分)🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-D卷的三语言AC题解 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接 => 字符串分割(100分) <= 🌍 评测功能需要 =>订阅专栏<= 后联系清隆解锁~ 🍓OJ题目截图 🎀 字符串分割 问题描述 K小姐最近在研究字符串问题。现在,她有一个只包含大写字母 和 的字符串 ,且 中 和 的数量相等。这
-
 华为OD-- java面经【超详细版】--待入职终端BG
华为OD-- java面经【超详细版】--待入职终端BG背景:双非一本,23届无经验,机考390 时间线:3月7日在牛客上联系的可乐姐,准备了一周左右。3月13日机考,3月14日性格测试, 3月15日资格面试,3月21日专业一面,3月25日专业二面,3月30日主管面试,4月12日offer【可乐姐辣评:终端审批正常速度】。 机试: 我的准备流程:在2023年12月24日考完408后就感觉要寄,遂决定找个工作。当时在网上看到了华为OD招聘,想着来试一下,
-
 华为2024暑期实习软件开发实习岗面经
华为2024暑期实习软件开发实习岗面经背景: 双非,港中深,计算机专业 没实习,有两个跟所面岗位没什么关系的学校课程的项目 求职岗位:后端开发暑期实习,base松山湖,部门匿了 已经过了两面,等待入职中 一面 Java内存结构 死锁如何处理 静态内部类的特点 类与类之间的关联性是如何在开发中体现的(他想问的是使用一个类存储另一个类的作为成员函数,我兜兜转转了半天,勉强算答对一半 Mysql是在我的项目中如何使用的 我熟悉哪些软件设计原
-
社交网络的Laravel雄辩ORM
我的状态帖子有以下数据库设置。对于每一篇文章,用户可以喜欢这篇文章,评论这篇文章,甚至可以由作者在原始文章中添加标签。 我试图设置我的足智多谋的控制器后带回所有的数据通过JSON对象,但我不能正确地找到评论,喜欢或标记用户名。如果有区别的话,我会用哨兵2进行认证。 以下是数据库设置: 我的Post控制器,我只是有一个简单的页面,可以显示所有内容。我不想循环查看文件中的任何内容,我只想返回json完
-
Clauset Newman Moore社区检测实现
我试图在Java中实现上述社区检测算法,虽然我可以访问C代码和原始论文——但我根本无法使其工作。我的主要问题是我不明白代码的目的——即算法是如何工作的。实际上,我的代码陷入了的无限循环中,列表似乎在每次迭代中都变得越来越大(正如我对代码的期望),但的值总是返回相同的值。 我测试这个的图相当大(300,000个节点,650,000条边)。我用于实现的原始代码来自SNAP库(https://githu
-
使用python和networkx检测社区
我正在研究网络中的检测社区。 我正在使用networkx和Python,我需要实现此算法:http://arxiv.org/pdf/0803.0476.pdf 这就是我试图解决它的方法:首先我制作列表列表,其中包含与图中节点一样多的列表(社区),以便我可以通过索引找到社区。然后对于每个节点,我找到它们的邻居并计算模块化增益,如下所示: 在哪里 然后我找到最大q并将节点I移动到新社区。但是这不起作用
-
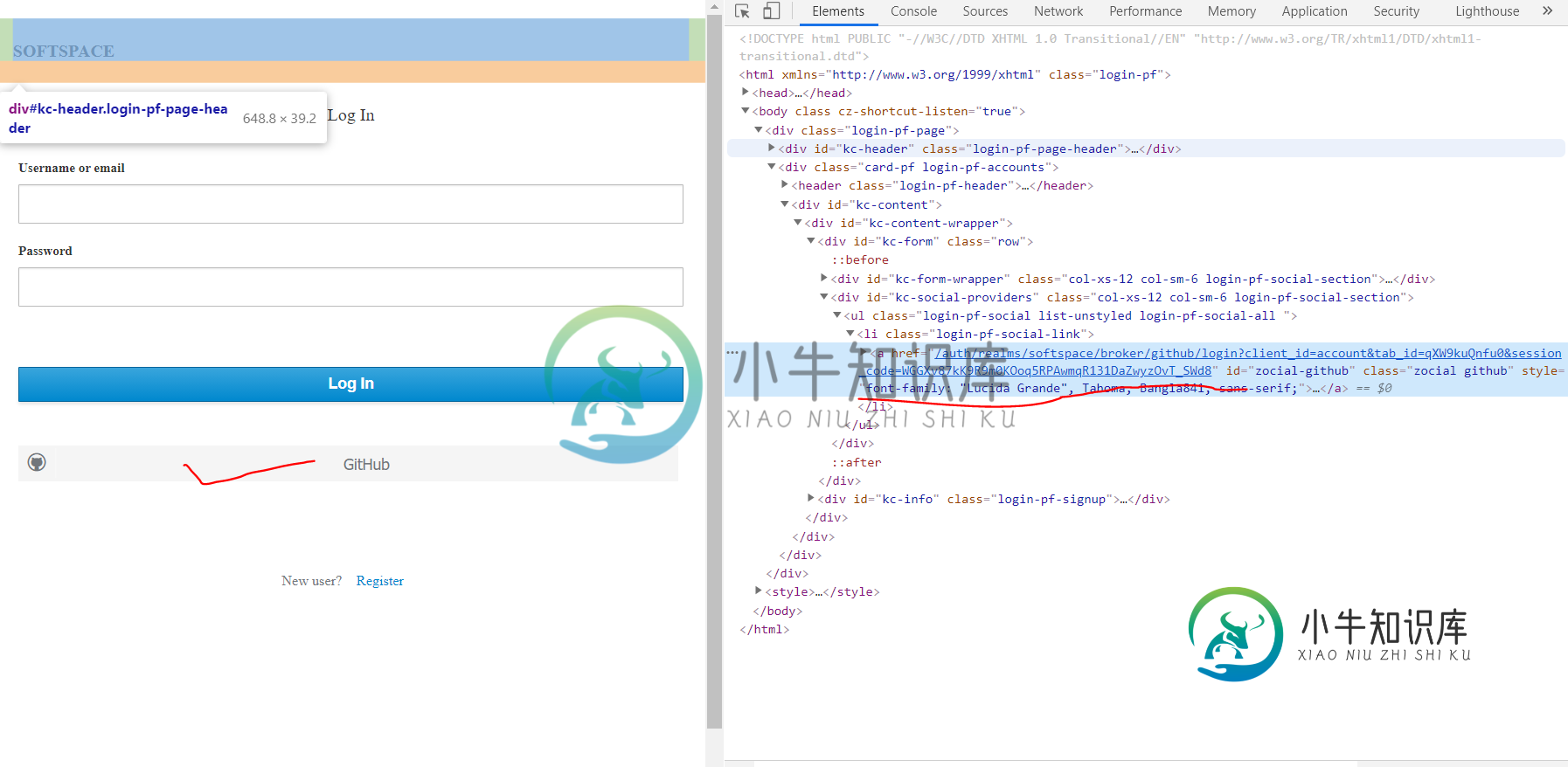 来自KeyClope的社交登录api
来自KeyClope的社交登录api我想从react js客户端和后端节点js使用KeyClope社交登录。我找不到任何方法从KeyClope生成红色标记的链接。 http://localhost:8080/auth/realms/softspace/broker/github/login?client_id=account 我不知道他们是如何生成标签id和会话代码的。
-
Android产品的在线旅行社
我如何更新我的Android的东西预览1与预览2?是否有一个自动在线旅行社可用,或者现在不可能,所以我必须闪存sd卡(从我的覆盆子派)?
-
IntelliJ社区版JSP语法高亮
我刚刚下载了IntelliJ 15.0.1社区版,因为我厌倦了Eclipse,它在我的笔记本电脑(Ubuntu 14.04 LTS)上看起来很糟糕。一切都很顺利,直到我看到JSP文件中的语法高亮不起作用。 我转到了设置/编辑器/文件类型 在可识别的文件类型中,除了其他选项之外,我还有这个选项: JSP 文件(仅语法突出显示) 当我选择它时,我可以在注册的模式中看到:*.jsp,*.tag,这正是我
-
Firestore社会网络数据结构
Firestore则不同,它需要冗余数据来有效地访问数据,但假设我跟踪了1000个人,如果我需要通过查询我跟踪的每15个用户的数据并使用方法来获得所有这些用户的帖子,那么查询之间可能会有未读的帖子,因为我们使用获得帖子,如何在Firestore中为社交媒体应用程序构造数据
-
这个算法叫什么?(社保)
观察:对于每个节点,我们可以重复使用它到目的地的最小路径,这样我们就不必重新计算它(dp)。此外,当我们发现一个循环时,我们检查它是否为负。如果不是,它不会影响我们的最终答案,我们可以说它没有连接到目的地(阉羊是否)。 伪代码: > 给定源节点u和目标节点v 初始化 Integer dp 数组,该数组存储相对于源节点的最小到达点节点的最小距离。dp[v]= 0,其他一切都是无限的 初始化boole
-
Firestore社交媒体模型结构
我有一个集合,我的应用程序在其中存储用户的所有帖子,数据结构如下: 现在,我想向我的用户显示这个集合的所有帖子;但是,只有当用户跟随创建帖子的人时,即帖子文档的字段适合。 我知道如果用户只关注一个人,查询集合是很简单的,也就是说,我有一个简单的子句。但是:如果我的用户关注10,000人或更多人呢?我怎么查询呢? 另外,我应该如何存储,即用户跟随的人?使用简单的数组似乎不适合我,但是使用所有其他选项
-
 得物 社区运营岗 面经
得物 社区运营岗 面经流程:电话面&一面 — 二面 — 收到offer — 正式入职 hr面:了解基本信息&约面试 电话联系确认一下基本情况,包括是否在上海,最早到岗时间是什么时候,一周能到岗几天 一般要求一周需要到岗4-5天,尽快入职,符合要求的hr就会帮你约面试啦,记得确认面试信息哦。 一面:mentor面 在飞书进行 简单的自我介绍 深挖简历:上一份实习的主要工作内容+过往的一些自媒体经历 了解得物吗?有使用过得