《大管加》专题
-
awk和gawk使用大整数和2的大幂
据我了解,POSIX awk 和 GNU awk 都使用 IEEE 754 double 来处理整数和浮点数。(我知道 开关在 GNU awk 上可用于任意精度的整数。这个问题假设没有选择 ... 这意味着awk / gawk / perl(没有自动提升到任意精度整数的那些)的最大整数大小将是53位,因为这是IEEE 754 double中可以容纳的最大整数大小。(当数量级大于2^53时,你不能再
-
 大学简单大方的自我介绍30秒
大学简单大方的自我介绍30秒主要内容:大学简单大方的自我介绍30秒篇1,大学简单大方的自我介绍30秒篇2,大学简单大方的自我介绍30秒篇3,大学简单大方的自我介绍30秒篇4,大学简单大方的自我介绍30秒篇5,大学简单大方的自我介绍30秒篇6,大学简单大方的自我介绍30秒篇7,大学简单大方的自我介绍30秒7篇 大学简单大方的自我介绍30秒?对于大学生来说,写上几份适合各种场合做自我介绍的腹稿可能会帮助你有更好的机遇。下面小编给大家带来了大学简单大方的自我介绍30秒,供大家参考。 大学简单大方的自我介绍30秒篇1 我叫__,是
-
如何设置上传文件的最大大小
我正在使用JHipster开发基于Spring Boot和AngularJS的应用程序。我的问题是如何设置上传文件的最大大小? 如果我试图上传到大文件,我会在控制台中获得以下信息: 和状态为500的服务器响应。 怎么设置?
-
超过最大调用堆栈大小-Connected React Component
问题内容: 我无法终生弄清楚为什么我会出错: 超过最大呼叫堆栈大小 运行此代码时。如果我注释掉: 错误消失了。我什至已注释掉其他电话,以尝试缩小问题的出处。 代码(删除了额外的功能): 问题答案: 由于此循环: 您正在从render调用getTabs方法,并在其中进行操作,将触发重新渲染,再次是getTabs ..... 无限循环 。 从方法中删除,它将起作用。 另一个问题在这里: 我们需要为on
-
PHP中数组的最大键大小是多少?
问题内容: 我正在生成关联数组,键值是1..n列的字符串连接。 有最大长度的钥匙会再次咬我吗?如果是这样,我可能会停下来并以不同的方式进行。 问题答案: 它似乎仅受脚本的内存限制的限制。 快速测试为我提供了128mb的密钥,没问题:
-
猫鼬-RangeError:超出最大调用堆栈大小
问题内容: 我试图将文档批量插入MongoDB中(因此绕过Mongoose并使用本机驱动程序,因为Mongoose不支持批量插入文档数组)。我这样做的原因是为了提高写作速度。 我在以下代码中的console.log(err)处收到错误“ RangeError:超出最大调用堆栈大小”: 也许与Mongoose返回的响应数组的格式有关,这意味着我不能直接使用MongoDB进行本机插入吗?我已经在每个响
-
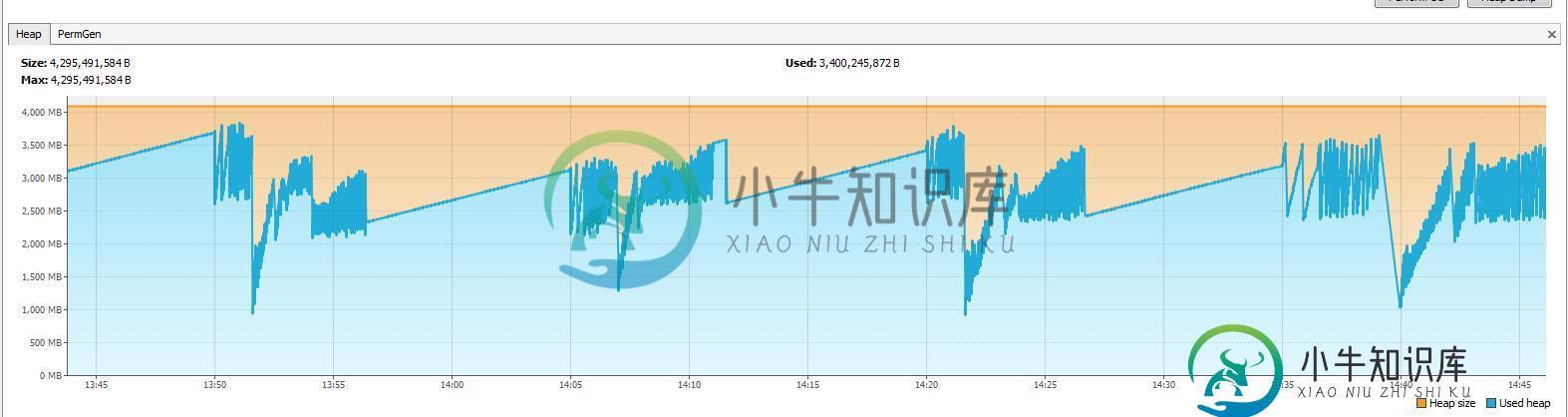 Java堆大小随着Infinispan缓存变得太大
Java堆大小随着Infinispan缓存变得太大我使用Infinispan缓存来存储值。代码每10分钟写入一次缓存,缓存大小约为400mb。它的生存时间约为2小时,最大条目数为1600万条,尽管目前在我的测试中,条目数没有超过200万条左右(我可以通过检查jconsole中的MBean/指标来了解这一点)。 当我启动jboss时,java堆大小是1.5Gb到2Gb。为jboss分配的最大内存的-Xmx设置是4Gb。 当我禁用Infinispan
-
如何确定密码的最大密钥大小
-
Javafx场景切换导致舞台大小增大
我正在使用Javafx(没有使用FXML),我正在将阶段传递到a控制器中,以便在单击按钮时更改阶段上的场景。场景的变化是正确的,但是舞台和场景的尺寸增加了,它的尺寸增加了大约0.1(宽度),而高度有时也增加了(不是每次都增加)。 下面是正在使用的控制器。
-
自动调整按钮大小到屏幕大小?
我是一个新的android开发和我正在尝试创建和应用程序与网格菜单,菜单。 当前依赖项:compile fileTree(目录:“libs”,include:['*.jar'])testCompile“junit:junit:4.12”编译组:“org.apache.httpcomponents”,名称:“httpclient-android”,版本:“4.3.5.1”编译组:“cz.mseber
-
aws cdk LambdaRestApi:最终策略大小大于限制
嗨,我一直在尝试许多可能性,但现在我需要一些帮助。 我使用aws-cdk通过代码创建架构,到目前为止一切顺利。现在我碰到这个问题: 我不知道这意味着什么,但我不知道如何解决它。 我正在创建lambda函数来处理所有请求: LambdaRestApi是这样定义的: 我在创建endpoint时使用了23次。 例如 因为只有一个lambda用于从apigateway调用,所以我很好奇,我如何才能控制只有
-
保存并设置“未最大化”窗口大小?
当用户关闭一个程序时,我想保存一些关于主窗口的信息,以便下次用户打开程序时,窗口具有相同的属性。 这对于窗口是否最大化很容易做到: 得到:舞台。isMaximized() 场景:舞台。setMaximized(布尔最大化) 如果窗口没有最大化,这也很容易做到: 得到:舞台。getX()/stage。getY()/舞台。getWidth()/stage。getHeight() 场景:舞台。setX(
-
Spring数据排序操作超出最大大小
我是相当新的Spring和MongoDB,并有一个问题,从我的MongoDB拉数据。我试图获得相当大的数据量,并收到以下异常: 执行器错误:操作失败:排序操作使用超过最大33554432字节的RAM。添加索引,或指定一个较小的限制。;嵌套异常是com.mongodb.MongoExc0019: Execator错误:操作失败:排序操作使用超过内存的最大33554432字节。添加索引,或指定较小的限
-
 最大化舞台后的场景最大化javafx
最大化舞台后的场景最大化javafx当我调整窗口大小时,舞台以及包含的场景会正确调整大小,但是当我单击最大化按钮时,只有舞台被最大化,而不是里面的场景。更糟糕的是,没有手动更改场景高度和宽度的方法(这些是只读的)。我还尝试创建新场景并将旧场景的根元素放在里面,但后来我得到了一个例外,即2个场景不能具有相同的根元素。谢谢! 最小可再现示例: 我标记了单击“最大化”的时刻。谢谢
-
Neo4j查找数据库的最大字节大小
我找到了关于如何计算neo4j数据库大小的以下信息:https://neo4j.com/developer/guide-sizing-and-hardware-calculator/#_disk_storage