《迈普》专题
-
React-Redux容器抛出Connect(ModalRoot)中的mapStateToProps()必须返回一个普通对象。而是收到未定义。"
我正在基于Dan Abramov对这个问题的解决方案构建一个基于Redux的模型/对话框触发器:Dan Abramov的解决方案 我得到的错误是“Connect(ModalRoot)中的MapStateTops()必须返回一个普通对象,而不是未定义的接收。”
-
如何从斯坦福Corenlp得到“普遍依赖,增强”?
我正在使用Stanford coreNLP解析器,我遇到了一个小问题,我认为这只是由于我缺乏经验而错过的一些愚蠢的东西。我目前使用的是Node.js stanford-corenlp包装器模块和Stanford Corenlp的最新完整Java版本。 如果有人能给我提供一些线索,甚至只是什么方向我需要更多的研究,这将是非常有帮助的。目前,谷歌在具体的“增强”结果方面没有提供太多帮助,我只是试图找出
-
如何在数据下载时将类似\u041b\u044e\u0431\u0438的文本转换为普通文本?
当我批量下载用俄语编写的GAE数据时,我得到如下文本 u'\u041b\u044e\u0431\u0438\u043c\u0430\u044f \u0430\u043a\u0446\u0438\u044f \u0432\u0435\u0440\u043d\u0443\u043b\u0430\u0441\u044c!\u0412 \u0440\u0435\u0441\u0442\u043e\u044
-
构造器自动布线比普通自动布线或属性自动布线有什么优势?
与属性自动装配相比,构造函数自动装配有什么特殊的优势吗……或者普通的优势。?优于迫使团队在Spring启动中使用构造函数自动装配……它有什么特殊的优势吗?两种类型的自动装配的优缺点
-
BigQuery:将重复字段与普通字段一起过滤
我有下表: 选择*结果JSON schema JSON: 我想通过cust_id和重复的字段来过滤它们的值,所以查询如下: 查询的预期输出: JSON格式查询的预期输出: 受这个问题的启发BigQuery:用标准SQL过滤重复字段我试试这个查询: 哪个输出: 输出JSON: 输出结果是不一样的,我想有,我如何才能实现这一点?
-
获取com。洛普。Androidhttp。启用Proguard后的AsyncHttpClient
我读过这篇文章,这似乎是很久以前就知道的问题了。但当我没有使用时,我没有收到任何警告或崩溃。启用后,我收到大约500条警告,如下所示:; 警告:com.loopj.android.http.AsyncHttpClient:找不到引用的类cz.msebera.android.httpclient 我试着跟踪,但所有的警告仍然存在。 我没有使用http客户端库,但我在项目中使用的其他库可能正在使用它。
-
Android将普通布局改为制表符布局,图片按钮和其他错误?
我按照这个方法创建了一个Android Radio流 在那里我添加了,但我有很多错误,所以我改变了一些像 从 对此 为了测试的目的,我在ProfileFragment中添加了我的代码.... 有没有人可以建议我如何使用我的活动片段像我的示例表布局请建议我在这类 更新
-
POM中出现错误。开普勒日食上的xml
我创建了基于maven的web应用程序,所以在创建应用程序后,pom中出现了两个错误。哪些是xml 1.在此行找到多个批注:-未能转移组织。阿帕奇。专家插件:maven资源插件:pom:2.6 fromhttp://repo.maven.apache.org/maven2已缓存在本地存储库中,在经过central的更新间隔或强制更新之前,不会重新尝试解析。原始错误:无法转移工件组织。阿帕奇。专家p
-
如何在Azure云上加入带有普通文件缓存的Kafka KStream?
我正在开发一个日志丰富Kafka流工作。我们的计划是使用Azure Blob上的文件缓存来丰富Kafka KStream中的日志条目。我的理解是,我必须将缓存文件从Azure Blob加载到一个KTable。然后我就可以将KStream与ktable连接起来。 作为一个新手,我遇到了两个困难,谁能给我一些提示吗? > 看起来Kafka Connect没有连接到Azure Blob的lib。我是否必
-
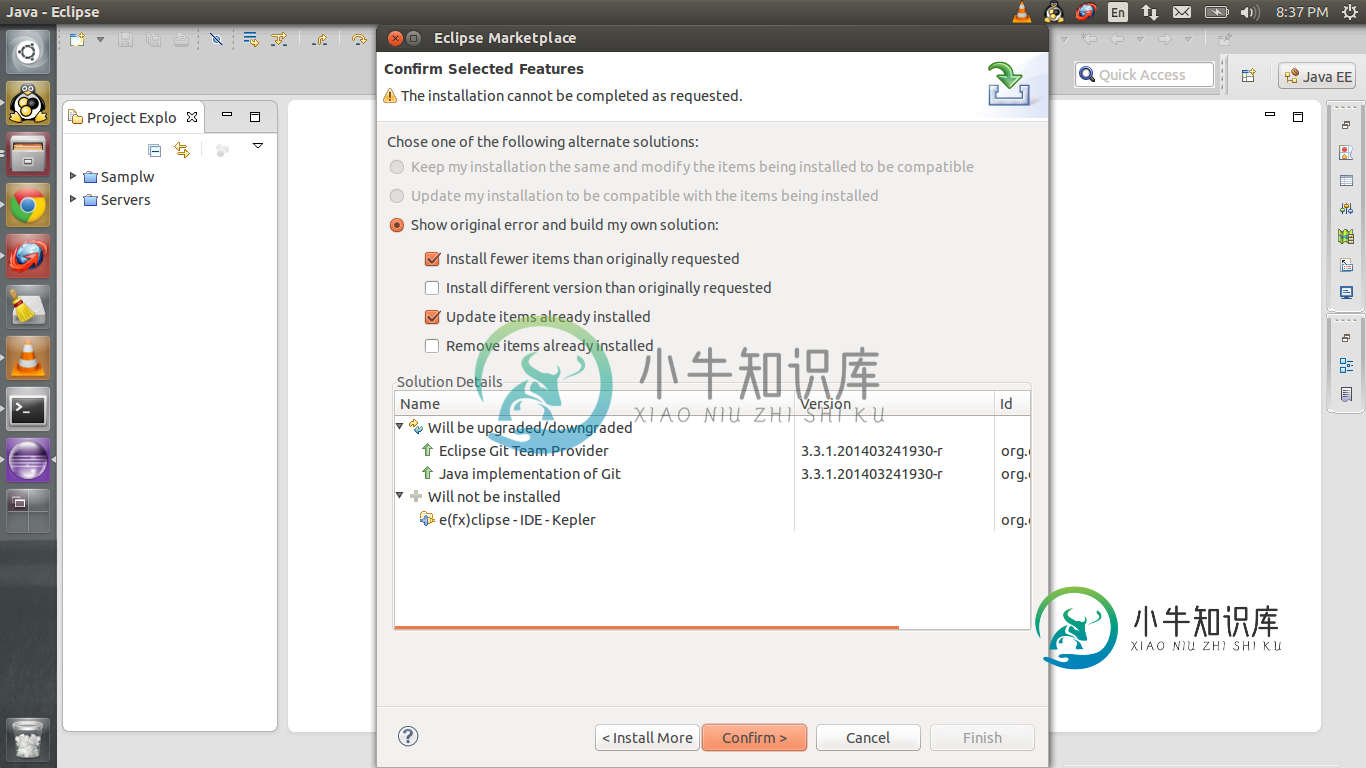 在Eclipse开普勒中安装e(fx)clipse的问题
在Eclipse开普勒中安装e(fx)clipse的问题因此,我选择了另一个安装e(fx)clipse的选项,并在http://www.eclipse.org/efxclipse/install.html#for-the-havided找到了步骤 无法完成安装,因为找不到一个或多个必需项。正在安装的软件:e(fx)clipse-ide-Kepler 0.9.0.201401250805(org.eclipse.fx.IDE.all.Kepler.fea
-
为什么命令会执行事务。更新是在carrelloatale之前执行的。普罗多蒂。add()命令
我正试图从cloud firestore的文档中获取产品,然后将该产品放入购物车。当我阅读(成功地)产品时,我会尝试将其放入一个在外部声明的arraylist中,但除非我将final放入变量,否则它不会工作。这样,当我运行下面的代码时,我成功地检索到了数据,但操作仍在进行。普罗多蒂。add(prod)在命令事务之后执行。update(),因此更新不会从一开始就上传任何内容。 我希望命令更新是在ca
-
PySpark在每一行DataFrame上执行普通Python函数
PySpark有可能吗?如果有,你能展示一个如何实现的例子吗?以from作为输入参数的UDF函数是正确的方法,还是可以以更简单的方式完成?Spark对一个时间点可以注册多少UDF函数(数量)有任何限制吗?
-
如何将普通数据(从房间返回)转换为ViewModel图层上的LiveData
我正在使用带有MVVM模式的干净体系结构,所以房间部分进入数据层,我将观察结果从那里返回到域层,并通过将它们包装在LiveData中在表示层中使用它们。现在的问题是,在插入/删除/更新列表之后,UI中的列表不会立即更新。 演示层中的Viewmodel: 数据层中的DAO: 数据层中的存储库: 域层中的GetAllWordsUseCase: 域层中的UseCase基类: 最后,表示层中的单词活动 谁
-
如何在Spring靴执行器普罗米修斯度量中包含时间戳
我正在使用Spring靴2.5.4和执行器与千分尺和普罗米修斯支持。当我打开endpoint时,我看到如下度量: 请注意,没有时间戳附加到该度量。但是,根据OpenMetrics/Prometheus规范,可以在度量输出中添加时间戳。 我的问题是:如何告诉Spring Boot Actuator生成时间戳并将其添加到它创建的度量标准中?我没有找到任何关于它的文件。谢了! 我的依赖关系如下所示: 我
-
cxf拦截器作为Springbean,具有自动生成的字段,使用普通注释配置
我的问题与另一个问题中的问题完全相同:“如何在自定义cxf拦截器中使用Spring Autowired?”。此处的有效响应建议通过上下文xml配置endpoint: 但我想完全不用xml配置,只通过注释来实现。是否可以通过注释@InInterceptors向@WebServiceendpoint添加拦截器(这是一个具有自动连接成员的Springbean)。还是有别的办法?