《迈普》专题
-
普罗米修斯或使用rate时()
摘要 由于导入的Grafana仪表板无法工作,我正在尝试找出如何在Prometheus查询中正确使用或运算符。
-
将pod指标拉到外部普罗米修斯
我试图使用现有的Prometheus(集群外部)从EKS集群内部聚合所有的指标,EC2(CPU、ram、disk)和POD(CPU、ram、disk)。我开始使用node-exporter、kube-state-metrics添加数据,但我一直坚持部署metrics-server。使用helm I conf并安装它,和正在提取数据,但是有人能告诉我如何将所有这些都提取到外部的Prometheus吗
-
基于标签的普罗米修斯滤波
如何在普罗米修斯查询中添加标签过滤器? KUBE_POD_INFO -->按命名空间测试筛选pod。 在这里,我想包括基于标签的过滤器以及。我在kube_pod_labels中有一个名为“label_source=”k8s“的标签。如何加入kube_pod_info和kube_pod_labels来应用标签筛选器?
-
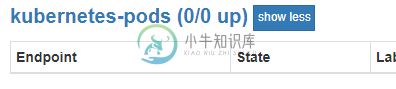 普罗米修斯不是在收集吊舱指标
普罗米修斯不是在收集吊舱指标我把普罗米修斯和格拉法纳部署到我的集群里。 当我打开仪表板时,我不会获得pod CPU使用情况的数据。 当我检查Prometheus UI时,它显示pods 0/0向上,但是我的集群中有许多pods在运行。
-
如何在普罗米修斯中从Kube状态度量中提取度量值时获得一个豆荚的标签
我有没有办法从kube-state-metrics中刮取这些指标,但在不覆盖它们的情况下将应用程序和团队标签放在一起? 编辑-我想通了
-
CPU使用率低于阈值且存在多个节点-普罗米修斯
我试图在prometheus中创建一个警报规则,以便当标签为agentpool=“worker”的所有节点在过去3分钟内的平均CPU使用率低于30%时,它会发出警报。
-
普罗米修斯不刮额外的刮伤
我正在使用stable/prometheus-operator图表部署prometheus。它安装在命名空间中。在命名空间中,我有一个运行的pod,名为,有三个副本。这个pod在端口9009上吐出度量标准(我已经通过执行k端口转发并验证localhost:9009中显示的度量标准来验证这一点)。我希望普罗米修斯操作员刮这些指标。因此,我将下面的配置添加到 然后,我使用下面的命令安装普罗米修斯:
-
GKE与普罗米修斯监测
我有一个启用了监视和日志记录的GKE集群(1.15)。到目前为止,我们一直使用metrics-server对StackDriver进行度量监控。对于其他自定义度量标准,我们使用了自定义度量标准适配器,该适配器使用Prometheus-to-SD将度量标准刮取并导出到stackdriver。 我想开始看看prometheus是否能给我们提供其他功能,比如HPA的聚合度量。 在GCP marketpl
-
普罗米修斯适配器使用的正确的普罗米修斯URL是什么
null 使用默认配置和轻微的定制。 我可以访问prometheus、grafana和alertmanager,查询度量标准并查看精美的图表。 但是prometheus-adapter在启动时不断抱怨它不能访问/发现度量: 在我的设置中,对于prometheus-adapter的正确值是什么?
-
普罗米修斯添加自定义度量
-
如何在默认endpoint/指标下重写普罗米修斯
}
-
如何修复'\'无效\'在普罗米修斯中不是有效的开始令牌''
我有spring-boot项目与web和执行器的依赖关系,这是在7071端口上运行的 我可以查看服务触发器的prometheus和metric http://localhost:7071/prometheus http://localhost:7071/Metrics 你能帮助yaml配置有什么问题吗?
-
普罗米修斯在GKE中没有收到来自cadvisor的度量
嘿, null 如果有人有经验得到这个配置,我肯定会感谢一些帮助调试。 干杯
-
普罗米修斯错误-摄取样本的错误
-
我如何得到一个豆荚的(毫)核心CPU使用普罗米修斯在库伯内特?
我运行了Kubernetes的自定义设置,并使用Prometheus刮取各种度量。除其他外,我还收集了和度量标准。 我想回答这样一个问题:“在我的部署中,有多少由和定义的CPU资源实际上被pod(及其容器)使用了(毫厘)核?” 有很多可用的量度,但没有这样的量度。也许它可以用秒的CPU使用时间来计算,但我不知道如何计算。 我一直在考虑这是不可能的--直到一个朋友告诉我,她在集群中运行Heapste