《平安》专题
-
 Android:自定义水平进度条动画
Android:自定义水平进度条动画我试图创建一个进度条,当它水平前进时,进度条本身会以垂直旋转的方式进行动画。我通过以下方式成功地使用了我的进度绘图功能: 这是我的画: 但我希望它在前进的过程中有一个微妙的滚动效果。所以看起来垂直线在向后移动。你明白了吗?非常感谢您的帮助。谢谢 编辑:我尝试创建一个动画列表作为我的进度绘图,但我仍然不能看到动画。动画列表可以在进度项目的剪辑中吗?
-
 如何创建水平加载进度条?
如何创建水平加载进度条?卸载android应用程序或进行一些配置时,会显示这样一个水平进度条,如下图所示: 它与android:style/Widget不同。ProgressBar。水平。 如何在我自己的应用程序中使用它?
-
如何扁平化嵌套的STD::可选?
注意:这个问题被简单地标记为这个问题的重复,但它不是完全的重复,因为我是专门询问std::optionals的。如果你关心一般情况,还是一个很好的问题。 假设我有嵌套的选项,如下所示(愚蠢的玩具示例): 还有这个垃圾邮件功能: 什么是压扁这张可选支票的最佳方法?我做了这样的东西,它不是可变的,但我不太关心这个(如果真的需要,我可以再添加一个级别(用),而且超出这个级别的所有东西都是可怕的代码)。
-
Gradle多模块项目的Spring平台bom
我有一个多模块gradle项目。 Root有以下模块:核心、应用程序(依赖于核心)、web(依赖于应用程序、核心) 从https://plugins.gradle.org/plugin/io.spring.dependency-management 我曾经用过 核心build.gradle内。 当我触发 在root命令提示符下,CoreJAR已成功构建,但应用程序无法解析依赖项的版本。 commo
-
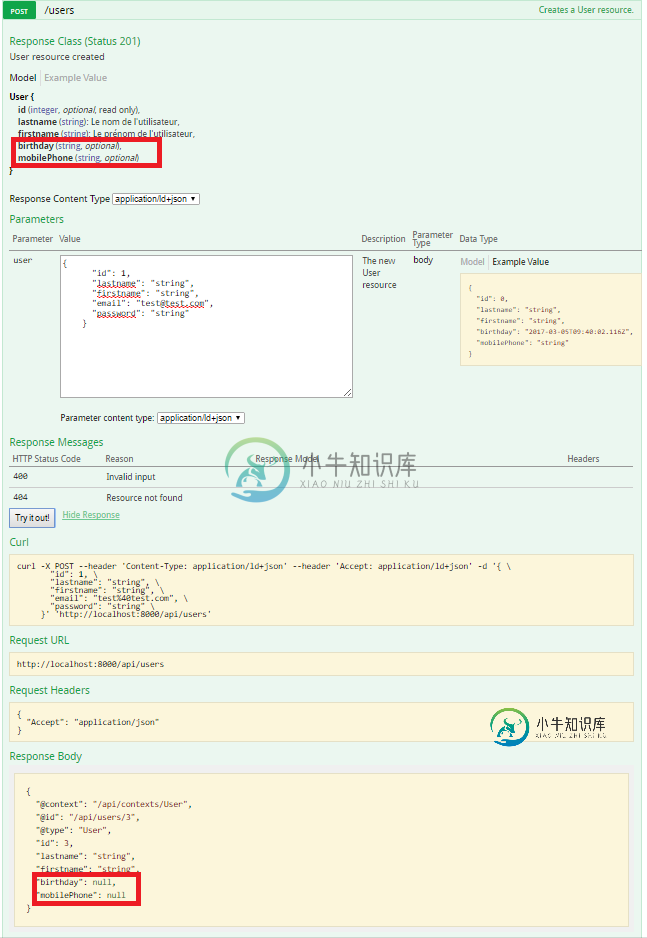 具有API平台Symfony的继承实体
具有API平台Symfony的继承实体我对平台API有问题(https://api-platform.com/)当我有一个从另一个实体继承的实体时。例如,从User实体继承的Worker实体。当我转到Platform API文档时,所有Worker属性都显示在User类中 这是一个比解释更好的模式。这是我的两个实体和问题文档的结果 这就是问题所在。我们看到 Worker 子类的属性出现在 User 类的模型中。并且当我测试发送 POS
-
理解Java中的公平可重入锁
API文档说明: 这个类的构造函数接受一个可选的公平性参数。当设置为true时,在争用状态下,锁倾向于授予对等待时间最长的线程的访问权限。 注意,锁的公平性并不能保证线程调度的公平性。因此,使用公平锁的许多线程中的一个可以连续多次获得它,而其他活动线程没有进展,并且当前没有持有锁。 我无法理解第2点: 如果一个线程连续多次获得锁,那么根据第1点,其他线程将等待更长时间,这确实意味着它们下次将获得锁
-
等待完成超时是否100%公平?
它是100%保证的线程,首先得到wait_for_completion_timeout会唤醒第一次调用完成?也许我错了,但是我看了下面的场景:线程A调用wait_for_completion_timeout并进入睡眠。当完成被调用时,它醒来并完成执行在函数do_wait_for_common。现在假设另一个线程B调用wait_for_completion_timeout. x- 然后继续睡觉。所以
-
如何写一个简单的公平锁?
如何写一个简单的公平锁模拟新的? 自定义不公平锁(我不确定它是否正确)
-
 水平对齐项目滑轮传送带
水平对齐项目滑轮传送带问题是我使用的是Slick Carousel,但每当我将div添加到Slick的脚本中时,我使用的是内容移动到不同的行中。 这就是当我将滚动div添加到Slick脚本时所发生的情况。 我几乎可以肯定这是一个CSS问题,但我已经尝试了很多,但不能使它工作。这是我的密码... 油滑 这是相关的CSS 这里有一个现场演示滚动到底部
-
xarray计算多年netcdf的月平均值
我有一个来自ERA5的2m温度netcdf文件,从2000年到2019年,从04月到10月,总共有13680个时间步长和61x161个纬度。我想分别计算每年所有每日时间步长的月平均值。例如,我们将获得2000年4月、2000年5月等数据的月平均值。我用xarray resample尝试了下面的代码,但是出现了两个问题。 出于某种原因,多年来,中庸之道似乎都是如此 重采样函数创建01、02、03、1
-
多语言和客户端负载平衡
使用Cloud Foundry功能“Polyglot”集成服务发现和通过内部路由在服务容器之间直接通信,负载平衡如何工作?Cloud Foundry是否负责负载平衡?有没有一种方法可以利用客户端负载平衡,比如在这种支持Polyglot的通信之上使用Ribbon?
-
Grails支架视图中无水平滚动
我有一个表,在某些列中有比较长的值,并且在我的Grails应用程序中为它打开了动态支架(我使用的是Grails3.3.8)。因此,在某些屏幕分辨率下,它们不在屏幕上,最右边的列最终会出现在屏幕之外--问题是,水平滚动条不会出现,所以用户甚至不知道它们在那里。把它们带回来的唯一方法是缩小--你不能用条形(因为它不在那里)或鼠标滚轮滚动;箭也不管用。 我如何修复这一点,使水平滚动条出现在内容超过屏幕大
-
关于把树夷为平地的困惑
我在处理这个Leetcode问题,它要求对树进行扁平化(请参见:https://Leetcode.com/problems/flatten-binary-tree-to-linked-list),这就是我的代码,但我很困惑为什么输出返回的是相同的原始树。我不是直接修改树本身来返回吗?我好像少了什么?
-
读取number.txt文件并查找平均值
目前正在处理一个作业,我需要读取一个数字文件,并显示数字的总量、总偶数、总奇数以及所有三个数字的平均值。我目前正在努力寻找偶数和奇数的平均值。我必须显示偶数的平均值和奇数的平均值。我通过使用parseInt将我读取的数字字符串转换为整数来找到总平均值,这样我就可以计算平均值,但是当我尝试对偶数和奇数做同样的事情时,我无法让它工作。 这是我当前的代码: 输出:
-
如何平等地间隔css网格列?
我有一个以表格格式显示数据的网格。我公司的前一个开发人员使用grid-template-columns和minmax属性来实现视图,但其中一个表的第一列很宽,其他每一列都是正常的。我如何将它们等量地间隔开,这样它们的宽度就一样了? 我试过使用minmax(auto,1fr)和repeat(auto-fill,minmax(max-content,1fr)),但它只是把视图的整个结构搞乱了 主容器具