《平安》专题
-
JUnit插件测试忽略目标平台
问题内容: 我已经使用了tycho-eclipse-plugin-archetype中的原型来创建带有工作集成测试项目的简单Eclipse插件。除了…不是。 当我以“ JUnit插件测试”启动任何测试时,会出现以下异常: (以及其他插件的一些类似消息。) 这很奇怪,因为我的目标平台包含3.4.300,而不是3.4.500,它需要版本[3.3.0,4.0.0)。测试用例的运行配置与此版本一致,并证明
-
平开窗被冻结,不显示内容
问题内容: public class Main extends JFrame{ 这是主类,这是它调用的框架类。 主类调用框架类..它需要保持一段时间,然后再移到另一个框架..但是发生的是主类调用它,该框架出现了,但是其中没有内容。显示,然后移至frame1()// 但是如果我像 新的Frame(); 然后按住,显示内容,然后移动。 那么为什么在Main()调用Frame()时它不起作用? 甚至这段
-
如何解决数据不平衡问题?
本文向大家介绍如何解决数据不平衡问题?相关面试题,主要包含被问及如何解决数据不平衡问题?时的应答技巧和注意事项,需要的朋友参考一下 这主要是由于数据分布不平衡造成的。解决方法如下: 采样,对小样本进行加噪声采样,对大样本进行下采样 进行特殊的加权,如在Adaboost中或者SVM 采用对不平衡数据集不敏感的算法 改变评价标准:用AUC|ROC来进行评价 考虑数据的先验分布 https://blog
-
获取SQL中每X行的平均值
问题内容: 假设我有下表 我想绘制这些值,但是由于我的真实表有成千上万个值,因此我考虑了获取每X行的平均值。我有什么办法可以做到这一点,即每2或4行,如下所示: 另外,是否有任何方法可以根据表中的总行数使此X值动态化?例如,如果我有1000行,则将基于每200行(1000/5)计算平均值,但是如果我有20行,则应基于每4行(20/5)计算平均值。 我知道如何以编程方式执行此操作,但是有什么方法可以
-
有平行游标之类的东西吗?
问题内容: 我正在使用CURSOR进行逐行操作。 我想知道为什么不能并行执行此操作,因为行操作是完全隔离的,只能将一些行插入到另一个表中,并且每一行都有自己的ID分配,因此不存在发生冲突的明显可能性。 我想知道是否有一种方法可以在纯SQL中并行化它? 问题答案: 这通常是通过队列来实现的:选择“待办事项”项并将其放入队列,同时队列读取器(处理线程)将“待办事项”项出队并逐一处理。将表用作队列是一种
-
查询以找到平均加权价格
问题内容: 我在Oracle中有一个表,每个给定部分有多行。每行都有一个与之关联的数量和价格。给定零件的行集合总计的总数量也是如此。以下是数据示例。我需要得到零件的平均加权价格。例如,如果数量为100的零件的价格为1,数量为50的零件的价格为2,则加权平均价格为1.33333333 有想法吗? 问题答案: 试试这个:
-
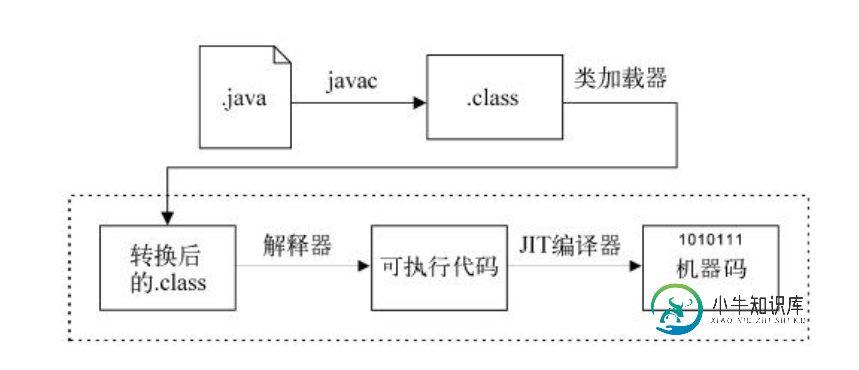 java语言与平台基础知识点
java语言与平台基础知识点本文向大家介绍java语言与平台基础知识点,包括了java语言与平台基础知识点的使用技巧和注意事项,需要的朋友参考一下 使用Java之前,我们要先弄清楚Java语言和Java平台之间的区别。然而,有时候不同的作者对语言和平台的构成会有不同的定义,所以人们有时不太清楚两者之间的区别,分不清是语言还是平台提供了代码使用的编程特性。 因为本书的大部分内容都需要你理解两者的区别,所以这里需要说明一下。以下
-
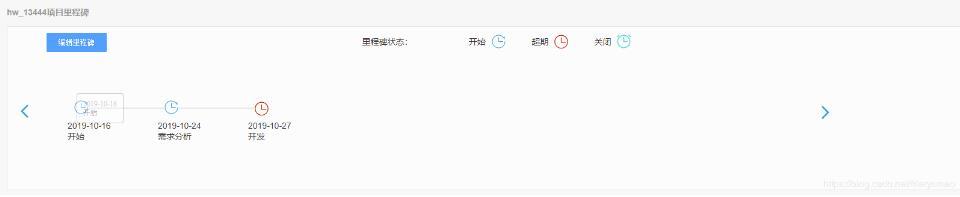 Vue实现可移动水平时间轴
Vue实现可移动水平时间轴本文向大家介绍Vue实现可移动水平时间轴,包括了Vue实现可移动水平时间轴的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Vue实现可移动水平时间轴的具体代码,供大家参考,具体内容如下 里程碑时间轴具体实现 效果图 编辑里程碑效果图 编辑里程碑 stonedetail.vue 关于vue.js组件的教程,请大家点击专题vue.js组件学习教程进行学习。 以上就是本文的全部内容,希望对
-
从leetcode oj中二分搜索平方根
上面是工作代码段。我有以下问题。事先谢谢你的帮助。;-) while(end-start>1)为什么这里需要1?就因为返回的意思是int? 如果我们将while循环从while(end-start>1)更改为while(end>start),我们必须使end=mid-1;和start=mid+1,对吗?还有一步,不知道这是不是也是因为返回类型是整数? 为什么不能返回End?或(int)(开始+结束
-
用可读的函数名展平promise链
我在处理promise链中的多个捕获中看到了promise实现,它产生了一个非常可读的链 但是,为了做到这一点,每个函数都需要返回一个值,而不是Promise?因为Promise可以解析为值或Promise,所以这不是问题。我的目标是让每个函数都具有可读的清晰逻辑。 尝试解除嵌套的promise函数时会出现问题 想象一下,原始实现涉及访问先前promise中的值。有了嵌套的promise,它很容易
-
Apache Http客户端和负载平衡器
在花了几个小时阅读Http客户机文档和源代码后,我决定在这里寻求帮助。 我有一个使用循环算法的负载均衡服务器
-
在Android系统中平滑擦洗视频
我正在尝试使用Android实现平滑的视频清理。的方法并不是我想要的。它并没有精确地寻找我传递的毫秒,它实际上是从/跳到最近的位置,而不是我想要的精确位置。此外,框架显示出较大的间隙。不是精确的毫秒帧。 我开始四处搜索,发现只能搜索最近的同步帧,而不是精确的同步帧。这取决于视频的生成方式。我如何才能实现平稳擦洗,并寻求准确的位置,即使视频暂停或播放。它是可能通过Android或类或我应该改变的方法
-
Mediastore.images.media.InsertiMage在三星平板电脑上失败
我的代码只会在三星Galaxy平板电脑上崩溃(例如SM-P601、Android4.4.2)。 崩溃的代码是这一行: 另一个失败的代码只是在OnClick方法中: null
-
Kafka提供生产者水平偏移吗?
假设,我有多个Kafka制作者同时为单个Kafka主题生成数据。 有可能得到哪个是给定生产者生产的最后一个偏移吗? 例如: 生产者: 我想找出分别由P1和P2发布的最后一条记录的偏移量。 请注意,我不是在要求全局主题分区偏移量。
-
Spark:扁平化简单的多列数据
如何将一个简单的(即没有嵌套结构的)数据表扁平化为列表?我的习题集是检测从节点对表中更改/添加/删除的所有节点对。 这意味着我有一个“before”和“after”表要比较。将before和after dataframe组合在一起生成的行描述了一对数据在一个dataframe中出现而在另一个dataframe中不出现的位置。 单独且不同地合并所有列 平面地图和不同的 映射和展平 由于结构是众所周知