《提前批真的不会影响正式批吗》专题
-
Cassandra批量
在Cassandra中,用于同时执行多个修改语句(插入,更新,删除)。 当你必须更新一些以及删除一些现有的列是非常有用的。 语法 实例: 让我们举个例子来演示命令。 在这里,我们有一个名为“”的表,其中包含列(,,),具有以下数据。 在这个例子中,我们将执行BATCH(插入,更新和删除)操作: 插入一个包含以下信息的新行(,,)。 更新行ID为的学生的列的值为。 删除具有行ID为的雇员的值。 完整
-
Spring批次
我们正在从Oracle DB迁移到Azure SQL Server,用于我们的Spring批处理应用程序。 我断断续续地得到以下错误 错误:01.03.2022:1458(40.269)[]main]命令行JobRunner:作业因错误而终止:创建名为“dateStoreList”的bean时出错:设置bean属性“jobRepository”时无法解析对bean“jobRepository”的引
-
审批单
作用 创建差旅或商务出行审批单,创建成功后会立即在企业APP上显示出行信息 依赖 需要在滴滴管理后台创建差旅或商务出行制度,然后通过用车制度查询接口查询制度id 如需要将费用归属到部门或者项目之下,需要先获取部门或项目id 注意 所有接口调用时需要严格遵守请求方式(GET/POST) 使用接口前需要仔细阅读每个接口的注意事项 接口报错时先阅读通用错误解决方案和当前接口文档下的接口错误解决方案
-
批处理
批处理 本书展示的几个例子中,ElasticSearch提供了高效的批量索引数据的功能,用户只需按批量索引的格式组织数据即可。同时,ElasticSearch也为获取数据和搜索数据提供了批处理功能。值得一提的是,该功能使用方式与批量索引类似,只需把多个请求组合到一起,每个请求可以独立指定索引及索引类型。接下来了解这些功能。 MultiGetMultiGet操作允许用户通过_mget端点在单个请求命
-
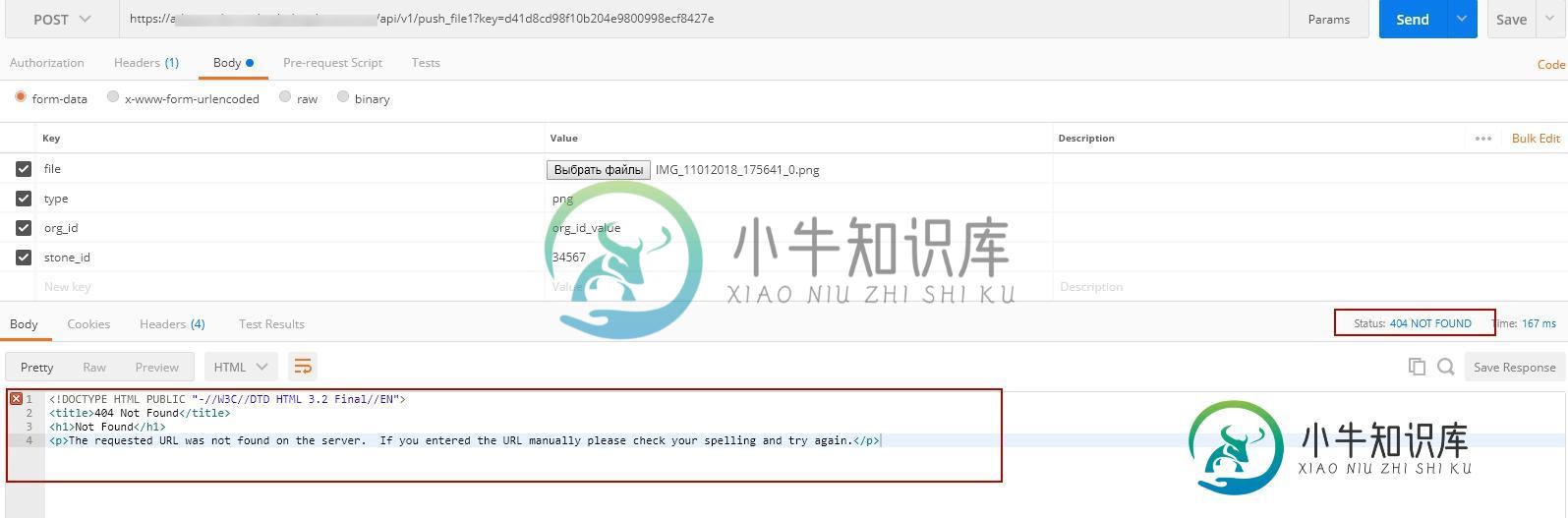 如何使用restTemplate获得真正的http代码和响应正文?
如何使用restTemplate获得真正的http代码和响应正文?我有以下代码: 如果我提供的所有参数都正确-enpoint会像邮递员应用程序一样返回200个http stsatus代码。 但是如果我提供了错误的url-我看到异常: 但是当我以同样的方式在postman中修改url时——我看到404错误: 我想有像邮递员一样的回应和像邮递员一样的回应。 如果我提供而不是,我会得到正确的,我可以在其中提取我想要的数据: 如何编写将提取和的通用代码? 重新模板初始化
-
HibernateCursorItemReader不工作的Spring Boot批处理
知道为什么下面的代码会出现以下错误吗? java.lang.NullPointerException:org.springframework.batch.item.database.HibernateCursoritemReader.DoRead处为null(HibernateCursoritemReader.java:155)
-
不可避免地调用abort()可能会产生什么影响?
我对“关闭”我的程序的abort术语的术语和矛盾感到有点困惑,从该函数的描述来看,它说析构函数和开放资源可能分别不被调用/关闭。那么,在调用abort()之后,我的程序是否仍在运行并且存在内存泄漏或者资源仍然打开?
-
当限制Kafka批大小时,如何使spark streaming在每个批中提交?
Kafka大约有5000万张唱片库存(即将消耗)。主题是3个分区。 我的消费应用程序: 我限制了spark streaming的消耗大小,在我的例子中,我将设置为10000,这意味着在我的例子中,它每批消耗30000条记录。 有什么方法可以让spark streaming在每个批处理中提交? Spark streaming日志,证明它每批消耗的记录num:
-
列出影响资本结构模式的因素。
本文向大家介绍列出影响资本结构模式的因素。,包括了列出影响资本结构模式的因素。的使用技巧和注意事项,需要的朋友参考一下 影响资本结构模式的因素如下: 经济 行业 公司 经济 经济措施:优先考虑股权。 资本市场:资金可用性取决于市场状况。 税收:税收结构不同。 金融机构的政策:选择债务可能会随着政策的变化而改变。 行业 频繁变化:多年来频繁的活动变化可能导致破产。 竞争:必须牢记风险因素才能在竞争者
-
吸收器和设置器会影响C ++ / D / Java的性能吗?
问题内容: 这是一个比较古老的话题:二传手和getter是好是坏? 我的问题是:C ++ / D / Java中的编译器是否可以内联吸气剂和吸气剂? 与直接现场访问相比,吸气器/设置器在多大程度上影响性能(函数调用,堆栈框架)。除了使用它们的所有其他原因之外,我想知道它们是否应该作为良好的OOP惯例而影响性能。 问题答案: 这取决于。没有普遍的答案永远是正确的。 在Java中,JIT编译器可能 迟
-
关于值长度的知识会影响哈希完整性吗
如果我在数据库中存储一个散列值,但被散列的原始值的长度是固定的(例如,总是4个字符),这会影响散列函数的单向性吗? 更准确地说,我有敏感字符串,然后加密并存储在数据库中。为了搜索这些字符串,我不想解密数据库中的每个条目,所以我还将字符串前4个字符的散列存储在另一列中。当我想搜索数据库时,我会生成搜索词的前4个字符的散列,并将其与存储的散列进行比较,以找到匹配或可以匹配的条目,然后解密这些条目以检查
-
JPA / Hibernate提高批处理插入性能
问题内容: 我有一个数据模型,该数据模型在一个实体和其他11个实体之间具有一对多关系。这12个实体一起代表一个数据包。我遇到的问题是与这些关系的“许多”方面发生的插入次数有关。其中一些可以具有多达100个单独的值,因此要将一个完整的数据包保存在数据库中,最多需要500次插入。 我正在将MySQL 5.5与InnoDB表一起使用。现在,通过测试数据库,我发现在处理批量插入时,它每秒可以轻松地每秒进行
-
Spring批处理块处理提交频率
如果我正在读写本地文件,那么对远程数据库服务器的更新相对昂贵。如果增加[chunk-size],内存使用量就会上升。 提交频率对编写本地文件并没有太大的影响,所以对我来说,元数据更新才是一个问题。该步骤是可重新启动的,因此从技术上讲,我不需要记录中间提交计数。 对于JobRepository,我可以只使用map或内存数据库,但我需要其他信息,例如持久化的开始/结束时间,而且这个问题只涉及一个步骤。
-
Spring批处理提交-间隔动态值
1)读取器读取的任何记录都应通过处理器的处理传递给写入器 2)我的阅读器通过SQL查询读取记录,所以如果阅读器读取了100条记录,那么所有记录都应该一次传递给writer 3)如果读取1000条记录,则应同时通过所有1000条记录 4)所以从本质上说,提交间隔在这里是动态的,而不是固定的。 5)我们有什么办法可以做到这一点吗? 编辑: 现在我们想要的是动态提交间隔。读者正在阅读的任何内容,都将立即
-
Spring批处理Java配置提交间隔
如何使用Java配置实现这一点?