《提前批真的不会影响正式批吗》专题
-
Spring boot hibernate/jpa批量更新不工作
应用程序属性 实体- 服务- Gradle- 我使用的是Spring boot 2.3.5。释放我正在尝试使用hibernate批处理更新批量记录,但它似乎不起作用。我没有收到任何错误,数据库中的记录正在更新,没有任何问题,但性能没有提高。事实上,无论是否使用Hibernate批处理,我都找不到任何区别。我检查了日志,他们的查询记录了每一条记录,例如,如果我试图保存1000条记录,那么日志中将有1
-
 PayPal订单V2不处理批准网址
PayPal订单V2不处理批准网址根据PayPal订单API作为文档,我们必须首先创建订单,然后从响应,我们必须复制批准网址并在浏览器中运行。这将打开PayPal页面。买方将批准请求。在此之后,应提出捕获请求。 发行详情 我有以下使用PayPal API创建订单的代码: 这段代码运行良好。这给了我4个URL,如下面的屏幕截图所示。 之后,我用rel=approve复制url。这个:https://www.sandbox.paypa
-
Kafka制作批次。大小不起作用
我用的是Kafka1.0,我增加了批量。大小=100K,用于优化我的制作人性能。但我发现,无论我设定的批次是什么,都没有任何效果。尺寸=100K或1000K或仅1K。此外,我还设定了我的逗留时间。ms=5,但这使性能更差。当我调试Kafka producer的源代码时,如下所示: 我发现了结果的价值。纽巴奇总是正确的,我想这就是为什么这一批。大小没有起任何作用,因为它每次都会唤醒发送者,而不是在b
-
Dynamodb批处理在Lambda中不起作用
我试图使用batchWrite将一个数据插入Dynamodb,但它无法插入数据。它只显示此消息(但没有错误消息)。 然后,无法插入数据。我试着用put,效果很好。我用的是Lambda。这是代码。
-
Hibernate批处理更新-不更新实体
我有一个批处理过程,它正在为一组实体重新计算数据。通过Hibernate从DB获取实体列表: 当流程运行时,某些实体似乎正在分离,导致两种症状: 当尝试获取惰性数据时,我得到一个异常: 在我的第一次尝试中,我试图通过调用inside
-
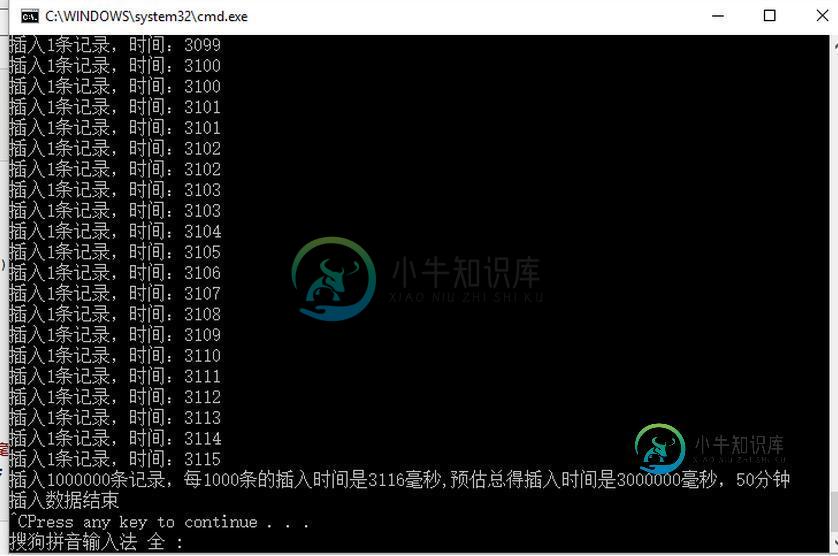 C#批量插入数据到Sqlserver中的三种方式
C#批量插入数据到Sqlserver中的三种方式本文向大家介绍C#批量插入数据到Sqlserver中的三种方式,包括了C#批量插入数据到Sqlserver中的三种方式的使用技巧和注意事项,需要的朋友参考一下 本篇,我将来讲解一下在Sqlserver中批量插入数据。 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引。GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表
-
批量模式下春云流Kafka中的错误处理
我正在使用Spring Cloud Stream和Kafka Binder批量消费来自一个Kafka主题的消息。我正在尝试实现一个错误处理机制。根据我的理解,我不能在批处理模式下使用Spring Cloud Stream的< code>enableDLQ属性。 我找到了和,以重试并从spring-kafka文档发送失败消息。但我无法理解如何按照功能编程标准将记录发送到自定义DLQ主题。我看到的所有
-
使用python-pptx包批量修改ppt格式的实现
本文向大家介绍使用python-pptx包批量修改ppt格式的实现,包括了使用python-pptx包批量修改ppt格式的实现的使用技巧和注意事项,需要的朋友参考一下 最近实习需要对若干ppt进行格式上的调整,主要就是将标题的位置、对齐方式、字体等统一,人工修改又麻烦又容易错。 因此结合网上的pptx包资料,使用python脚本完成处理。 主要的坑点在于,shape的text_frame不能直接修
-
块处理模式下的Spring批处理事务回滚
-
azure宇宙图数据库批量导入的Json格式
我们计划将数据库迁移到Azure cosmos graph数据库。我们正在使用此批量导入工具。 它没有提到Json输入格式。 批量导入Azure cosmos graph db的Json格式是什么 https://github.com/Azure-Samples/azure-cosmosdb-graph-bulkexecutor-dotnet-getting-started azure 批量导入映
-
Keras/TensorFlow批次标准化正在标准化什么
我的问题是批处理规范化(BN)正在规范化什么。 我在问,BN是单独标准化每个像素的通道还是一起标准化所有像素的通道。它是在每张图像的基础上还是在整个批次的所有通道上进行的。 具体而言,BN在X上运行。比如说,。因此,当轴=3时,它在“c”维度上运行,即通道数(对于rgb)或特征图数。 因此,假设X是rgb,因此有3个通道。BN是否做到了以下几点:(这是BN的简化版本,用于讨论维度方面。我知道gam
-
标准化数据库会对资源产生什么影响?
问题内容: 从相对不规范的形式获取数据库并将其规范化时,人们可能期望资源利用率 发生 什么 变化 (如果有)? 例如,规范化通常意味着可以从更少的表中创建更多的表,这意味着数据库现在具有更多的表,但是其中许多表都非常小,可以使经常使用的表更好地适合内存。 表的数量越多,意味着(潜在地)需要更多的联接才能获取抽象出的数据,因此,人们可能会期望系统需要执行的联接数量越多,就会产生某种影响。 那么,标准
-
数据库(最大)字段长度是否会影响性能?
问题内容: 在我的公司中,我们有一个包含各种表的遗留数据库,因此包含许多字段。 许多字段似乎都有从未达到的大限制(例如:)。 是否将字段的最大宽度设置为最大宽度或比通常输入的字段大2到3倍会对性能产生负面影响? 一个应如何在性能与字段长度之间取得平衡?有平衡吗? 问题答案: 这个问题有两个部分: 在VARCHAR上使用NVARCHAR是否会损害性能?是的,将数据存储在unicode字段中会使存储需
-
 Redis分布式锁,没它真不行!
Redis分布式锁,没它真不行!主要内容:写在前面,Redisson实现Redis分布式锁的底层原理写在前面 现在面试,一般都会聊聊分布式系统这块的东西。通常面试官都会从服务框架(Spring Cloud、Dubbo)聊起,一路聊到分布式事务、分布式锁、ZooKeeper等知识。 所以咱们这篇文章就来聊聊分布式锁这块知识,具体的来看看Redis分布式锁的实现原理。 说实话,如果在公司里落地生产环境用分布式锁的时候,一定是会用开源类库的,比如Redis分布式锁,一般就是用Redisson框架就好了
-
Spring内存批处理(MapJobRepositoryFactoryBean)清除旧作业,而不是正在运行的作业
我使用spring批处理来计划批处理作业,即内存中的批处理作业,作为项目特定的需求(即不在生产中,它只是用于测试环境),下面是我的配置类 我每0/15分钟安排两个作业,这将执行一些业务逻辑,我还安排了内存清理作业,仅当这两个作业中的任何一个未处于运行状态时,才从“mapJobRepositoryFactoryBean”bean清理内存中的作业数据。 我想建议找到如何删除已经执行的旧作业的最佳方法,