《我的记录》专题
-
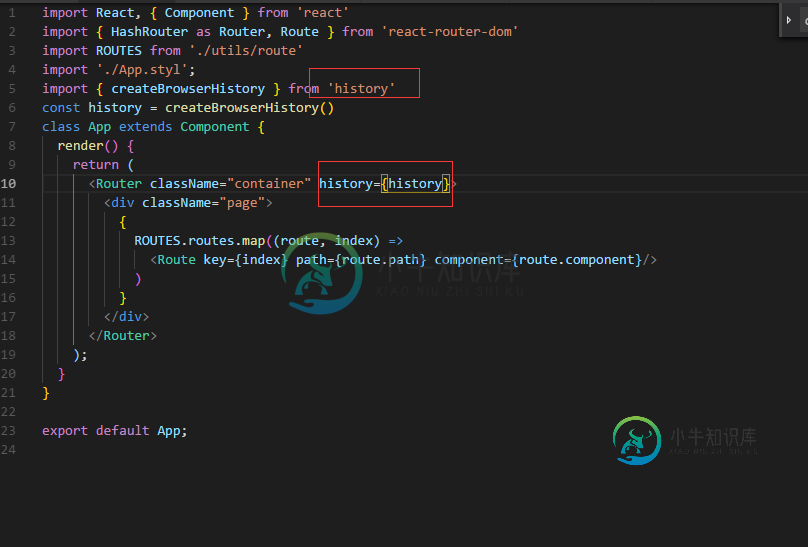 当我使用react route 4历史记录,但控制台发出以下警告时。谁能告诉我原因吗?
当我使用react route 4历史记录,但控制台发出以下警告时。谁能告诉我原因吗?警告:忽略历史道具。要使用自定义历史记录,请使用而不是
-
查找所有子记录都具有给定值的所有父记录(而不只是某些子记录)
问题内容: 一个活动有很多参与者。参与者的字段为“状态”。 我需要找到除以下事件以外的所有事件:每个参与者的状态都为“出席”的事件。 我可以找到带有以下AR代码的某些参与者处于“呈现”状态的所有事件: 这样就创建了SQL: 这 几乎 可行。问题是,如果参与者的某行(在范围内 )的状态为“离开”,则该事件仍将被获取,因为至少某些同级记录的状态与其他状态相同而不是“现在”。 我需要确保我正在过滤所有事
-
使用Python日志记录管理记录器
问题内容: 我正在编写一个服务器应用程序,该应用程序应该能够在控制台和日志文件上以不同级别登录。 问题是,如果设置了logging.basicConfig(),它将登录到控制台,但是必须在主线程中进行设置。 也可以使用logging.basicConfig(filename =’logger.log’)进行设置以写入文件。 设置用于控制台日志记录(logging.StreamHandler())或
-
如何禁用jupyter笔记本历史记录
我正在使用Jupyter笔记本编写Python 2代码。我将其调用为: 同时,我使用IPython控制台,启动时使用: 我的问题是,Jupyter历史被保存,并且与IPython历史混合在一起。我根本不想要Jupyter笔记本的历史记录-有没有办法禁用它,同时保留IPython**历史记录? 平台:win32 更新: 我尝试过使用建议的设置摘要方法。但是,当我在配置中输入“c.Session.di
-
After Effects 中的图层标记和合成标记
使用合成标记和图层标记可存储注释和其他元数据,以及标记合成或图层中的重要时刻。合成标记显示在合成的时间标尺上,而每个图层标记显示在相应图层的持续时间条上。两种标记都可以保存相同的信息。 标记可以指单个时间点,也可以指一段持续时间。 After Effects 中的合成标记对应于 Adobe Premiere Pro 中的顺序标记。After Effects 中的图层标记对应于 Adobe Prem
-
我们如何记录每个http请求和响应,并将其保存到express中的数据库
我试图将所有传入的请求及其响应保存到数据库中。 我正试图使用express winston npm包实现这一点,它正在控制台中记录响应主体和请求。但我想把它保存在数据库里。我该怎么做???? 我正在控制台中获取此日志。 {"level":"info","消息":"HTTP GET /ideas/category/hello","meta":{"res":{"statusCode": 200,"bo
-
Twilio chat:我可以获得一个频道的消息历史记录而不加入该频道吗?
我正在使用Twilio chat SDKfor iOS,但遇到了一个问题。我可以获得通道列表,获得单个通道,并成功获得该通道的消息计数。我要做的下一件事是使用从该通道获取最后一条消息。但是,从不调用该方法的完成。 我需要在没有实际加入频道的情况下这样做,因为我只是试图获得最后一条消息,以便与许多其他消息一起显示在一个摘要屏幕中。我不想加入,因为对方可能在另一端在线,它会错误地将用户显示为在线(即使
-
如何在具有聚合函数的MySQL查询中获取分组记录的第一条记录和最后一条记录?
问题内容: 我正在尝试获取“分组”记录的第一条记录和最后一条记录。 更准确地说,我正在执行这样的查询 但我想获得小组的第一和最后的记录。可以通过执行大量请求来完成,但是我的桌子很大。 是否有使用MySQL的方法(如果可能的话,可以减少处理时间)? 问题答案: 您要使用和: 这避免了昂贵的子查询,并且我发现对于这个特定问题它通常更有效。 请查阅手册中的两个函数以了解它们的参数,或访问本文,其中包含有
-
 从没有唯一标识的重复记录中获取最高的第一条记录
从没有唯一标识的重复记录中获取最高的第一条记录问题内容: 我需要从下面给出的表中获取每个重复记录集的第一行。我需要在视图中使用此查询 请不要使用临时表,因为我已经通过添加标识列和最小函数以及分组依据来完成了。我需要没有临时表或表变量的解决方案 这只是示例数据。原始表中有1000条记录,我只需要前1000条的结果,因此不能使用 不同的 我正在使用SQL Server 2005 谢谢。 问题答案: 答案具体取决于您所说的“前1000个不同”记录的
-
同一记录器到两个不同级别的不同appender的sl4j记录器配置
如何在SL4J中配置日志记录?我的项目有很多类:class1、class2、Class3....我想做两件事:将所有类记录到一个名为FILE1的文件追加器中,并具有警告级别(class1、class2、class3...)将一个名为class1的类记录到具有调试级别的名为FILE2的文件追加器中。 问题是,当我将class1的记录器配置为具有WARN级别的FILE1 appender时,我不知道如
-
从Postgres DB中包含1000万条记录的表中获取记录的性能改进
我有一个分析表,其中包含1000万记录,为了生产图表,我必须从分析表中获取记录。其他几个表也加入到这个表中,目前正在获取数据但它需要大约10分钟,即使我已经索引了加入的列,并且我在Postgres中使用了物化视图。但仍然性能很低,从物化视图执行选择查询需要5分钟。 请建议我一些技巧,以便在5秒内得到结果。我不想改变数据库存储结构,因为要支持它,需要做很多代码更改。我想知道是否有一些内置的方法可以提
-
为什么这个吃记忆的人真的不吃记忆?
问题内容: 我想创建一个程序来模拟Unix服务器上的内存不足(OOM)情况。我创建了这个超级简单的内存消耗者: 它消耗的内存与定义的内存一样多,而现在恰好是50 GB的RAM。它按1 MB分配内存,并精确打印无法分配更多内存的点,这样我就知道它设法吃了哪个最大值。 问题是它有效。即使在具有1 GB物理内存的系统上。 当我检查顶部时,我发现该进程占用了50 GB的虚拟内存,而占用的驻留内存不到1 M
-
Jsoup选择带有多个标记的标记后的文本
我想在每个文本之后使用jsoup提取一个文本。有没有办法选择它? 示例代码如下: 当它完成时,它会创建自动id示例id=123
-
用更新的标记移除地图上的多个标记
-
获取索引值=0的Indexeddb ObjectStore的记录
我试图从索引值为0的indexeddb存储区获取所有记录,下面的代码在值为1,2,3,4等的情况下工作,但当它为0时,它不会返回。 有什么想法吗? 最诚挚的问候Lmac34