《职业规划》专题
-
按行规范pandas DataFrame
问题内容: 规范pandas DataFrame每行的最惯用方法是什么?标准化列很容易,因此一个选项(非常难看!)是: pandas广播规则禁止这样做 问题答案: 要解决广播问题,可以使用以下方法: 参见http://pandas.pydata.org/pandas-docs/stable/basics.html#matching- broadcasting-behavior
-
SQL Server排序规则
问题内容: 我正在读的书说 SQL Server支持两种字符数据类型-常规和Unicode。 常规数据类型包括CHAR和VARCHAR,而Unicode数据类型包括NCHAR和NVARCHAR。不同之处在于,常规字符为每个字符使用一个字节的存储空间,而Unicode字符则每个字符需要两个字节的存储空间。每个字符只有一个字节的存储空间,因此,为一列选择常规字符类型会限制您只能选择英语以外的一种语言,
-
并行化蛇规则
问题内容: 抱歉,如果这是一个幼稚的问题,但我仍在努力解决Snakemake的复杂性。 我有一个目录,其中包含多个文件,这些文件要并行应用规则(即,我想向集群提交相同的脚本,为每个提交指定一个不同的输入文件)。 我首先尝试对输入文件使用expand,但这仅导致提交一份作业: 这里有替代方法吗? 谢谢! 问题答案: 当前,您的工作流确实只包含一次应用“ vep”规则,在此规则中,所有输入和输出都作为
-
枚举的JPA规范
我的JPA实体作为枚举字段 哪里 如果我用规范添加where条件 将枚举包含到规范查询中的正确方法是什么?
-
常规中的Hello World
本文向大家介绍常规中的Hello World,包括了常规中的Hello World的使用技巧和注意事项,需要的朋友参考一下 示例 以下示例说明了Hello World使用脚本最简单的常规操作,将以下代码段放置在文件中,例如helloWorld.groovy 如何执行:在命令行中,groovy helloWorld.groovy 输出:Hello World!
-
JUnit@之前vs@规则
我明白,,
-
JVM10规范与不同?
有没有人知道Java10和JVM10规范的版本与以前的版本不同?对于Java8和Java9,有不同的规范,很难看到有什么变化。
-
 Android:实时Firebase规则
Android:实时Firebase规则我想知道如何确保我的规则。我试着使用
-
 Firebase,不安全规则
Firebase,不安全规则我最近收到一封来自Firebase的电子邮件,告诉我我的数据库(FiRest)的规则不安全,所以我将它们更改为以下内容: 在我有这些规则之前: 在做出改变后,电子邮件不断地回来,我不知道还能做什么。我已经尝试了以下链接中给出的几个选项,但它们都不能满足我的需要。 https://firebase.google.com/docs/rules/insecure-rules#firestore 我需要授
-
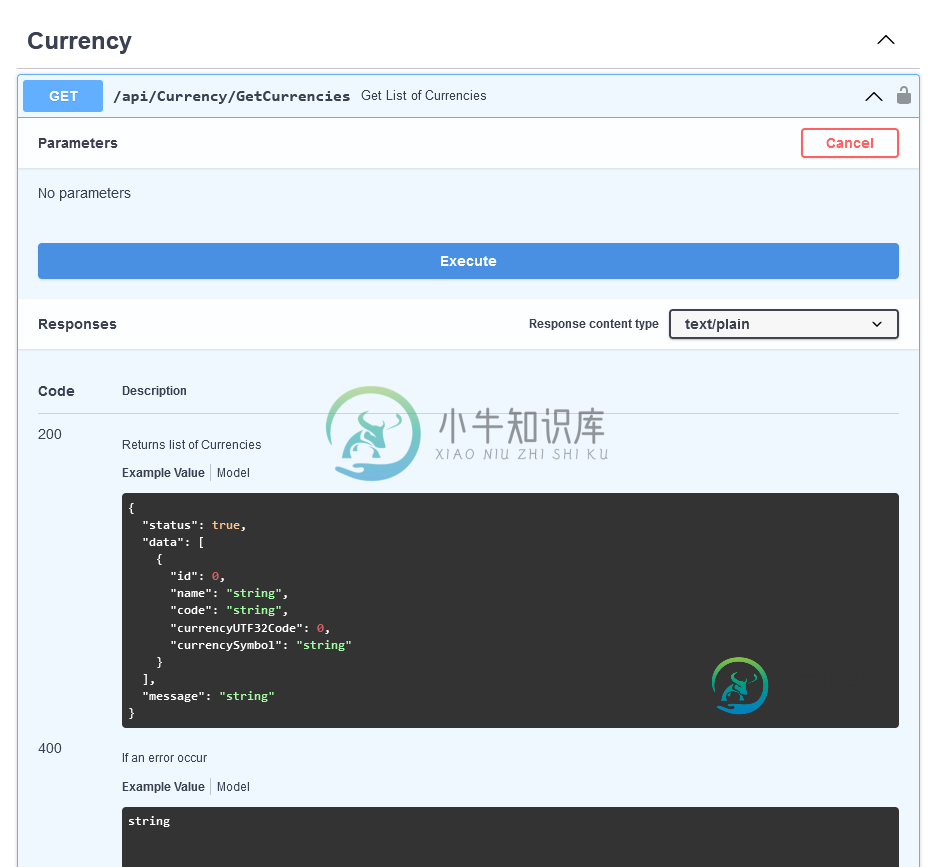 Swager 2.0参考规范
Swager 2.0参考规范我在尝试格式化这个OpenApI(Swagger) Json文件时遇到了挑战。当我试图与https://editor.swagger.io/,确认时,我得到了错误。 $ref值必须是符合 RFC3986 的百分比编码 URI 当我将文件中架构的$ref属性从$ ref:' #/definitions/GetResponse[List[currency model]]'更改为$ ref:%/defi
-
自动拳击规则
那么,换句话说,为什么编译器不能在第二个方法中执行自动装箱呢?是因为在第二个方法中,绑定不是显式的,而在第一个方法中绑定是明确的。
-
Nifi Jolt变换规格
我正在尝试使用nifi joltTransformjson来转换我的JSON。我正在使用这个网站http://jolt-demo.appspot.com/#modify-stringFunctions 我有一个JSON 我的颠簸规格是 电流输出为 想要的输出是 请帮忙。我试了这么多组合,但我似乎想不通。
-
Jolt Transform规范问题
我目前的输入 JSON 是 我想要如下所示的输出 JSON。我只需要添加一个额外的键并值“key5” 预期产量 并提及如何覆盖key4的值 请帮我找到这方面的Jolt Json规范。 以下是我使用的规格
-
SonarQube规则集丢失
我想用Sonarqube分析一个.NET项目。我正在使用sonar-scanner-msbuild-2.3.1.554-我已经编辑了sonarq.analysis.xml-我运行以下命令 msbuild.sonarqube.runner.exe“begin/key:”AHC“/名称:”AHC项目“/版本:”1.0“msbuild.exe”d:\tfs\ahc\mainbranch\tfsCompl
-
java虚拟机规范
我正在读“Java虚拟机规范第7版”,有一些东西真的让我困惑,下面是问题: 在这种情况下,使用当前帧(§2.6)恢复调用器的状态,包括其局部变量和操作数堆栈,调用器的程序计数器适当增加以跳过方法调用指令。然后在调用方法的帧中正常地继续执行,返回的值(如果有的话)推送到该帧的操作数堆栈上。 那么“跳过方法调用指令”是什么意思呢?有人能解释一下吗?非常感谢!