《APUS-独角兽》专题
-
基于swagger文件验证请求的独立NPM库
我们正在使用Swagger、AWS API网关和Lambda函数与NodeJS构建API。API网关将进行请求验证,但是根据设计,lambda函数需要将请求对象重新验证为API网关代理请求事件。这是有意义的,因为理论上我们可以通过其他事件源(例如SNS)调用lambda函数来重用它们。 因此,我们需要一个NodeJS工具,它可以根据swagger规范验证请求(不仅是正文,还有参数等)-正是swag
-
Spark 1.2.1独立集群模式spark-submit不起作用
/usr/local/spark-1.2.1-bin-hadoop2.4/bin/--类com.fst.firststep.aggregator.firststepmessageProcessor--主spark://ec2-xx-xx-xx-xx.compute-1.amazonaws.com:7077--部署模式集群--监督文件:///home/xyz/sparkstreaming-0.0.1
-
ANTLR4:使用单独语法时出现grun错误(ClassCastException)
我试图创建一种自定义语言,将lexer规则与parser规则分开。此外,我的目标是进一步将lexer和parser规则划分到特定的文件中(例如,通用lexer规则和关键字规则)。 但我似乎无法让它发挥作用。
-
Jenkins为使用Selenium独立webdriver的PHPUnit测试设置
我有使用Selenium独立服务器运行的PHPUnit端到端测试。我的测试扩展了PHPUnit_Extensions_Selenium2TestCase,我使用$this设置浏览器- 谢谢
-
使一个类中的JButton打开独立的JDialog类
我正在创建一个测验,并创建了一个具有JFrame的类,它的作用类似于主菜单。在这个菜单上,我创建了一个JButton,我想打开单独的JDialog(其中包含问题等)。 JDialog是一个名为QuestionDialog.java独立类 这里是我在主菜单JFrame类中的代码,特别是我要打开新JDialog public static void main(String[]args){SwingUt
-
Maven模块与作为依赖项的独立Maven POM
我目前在一个项目中工作,该项目包括大约12个子项目。 每个子项目都包含一个POM,该POM单独构建依赖关系。 上游子项目包括下游子项目作为依赖项,其方式与包含对log4j: 这似乎对我们管用。 然而,今天,经过11个月的开发,我决定重温这十几个POM文件,并考虑到重构。 我随后发现了和标记,并开始怀疑我的Maven项目策略是否“正确”。 重构我的POM,使最上层的POM(一个Web WAR项目)变
-
独立servlet容器中的Spring Boot应用程序war
关于从Spring Boot应用程序构建war并在独立的servlet容器中运行它的一般问题。我所看到的文档似乎与堆栈溢出的示例不一致。 这里的答案显示了我几个月前读到的这样做的方式。我在这里读到了这个,但是指南似乎已经改变了,失去了实际的示例应用程序。 这里的“configure”方法引用了主要的Spring Bootapplication.class。
-
我需要为spring-boot项目单独安装Tomcat吗?
我有一个spring-boot项目,我有以下设置: 我问这个问题的原因是,我可以同时在IntelliJ IDE和终端(mvn spring-boot:run)中运行我的web(war package)应用程序来启动该应用程序,然后我可以使用localhost向restful服务发送http请求。我没有单独安装Tomcat。 过了好一阵子,我仍然可以在IntelliJ中成功运行我的web应用程序,但
-
对PriorityQueue使用比较器和单独的compareTo方法
如果我有一个由T对象组成的PriorityQueue,并且T有一个compareTo()方法并实现comparable,但是我的PriorityQueue也使用一个comparator作为参数,那么我的PriorityQueue在元素的顺序方面会寻找什么? 换句话说,哪一个决定了对象的优先级?compareTo()方法或提供的比较器?
-
IntelliJ中独立模块导致的Hibernate映射错误?
我正在创建一个多模块maven项目,其中模块ModuleA和ModuleB位于父项目之下。 这些模块使用自己的Hibernate映射和自己的资源文件夹。每个模块独立于其他模块保存其对象。现在,当我尝试在模块A中实例化模块B中的一个类时,我可以访问所有需要的方法,但是当我执行应用程序时,Hibernate会抛出以下错误: 我可以另外将ModuleB中类的映射添加到模块A的Hibernate配置文件中
-
为什么我的实体在JPA中保持独立?
我正在使用Spring、JPA和Hibernate。这是一个玩具示例,我正在使用它来调试一个更大的与JPA相关的问题。但是,这个试图持久化一个非常基本的实体的简单示例似乎创建了分离的对象。据我所知,在对象上调用应该将实体设置为由持久性上下文管理。但是,它不是,而且对此也不起作用。输出如下:: 为简洁起见省略了进口。 :: ::
-
Apache Spark:在Spark独立模式下禁用Spark Web UI
我正在以客户端部署模式的独立模式运行Apache Spark 2.1.1。我想为主服务器和所有工作人员禁用 Spark 网页 UI。 参考:https://spark.apache.org/docs/latest/configuration.html#spark-ui 和在$SPARK_HOME/conf/spark-defaults.conf中的以下配置使用: 然而,我仍然可以在默认端口8080
-
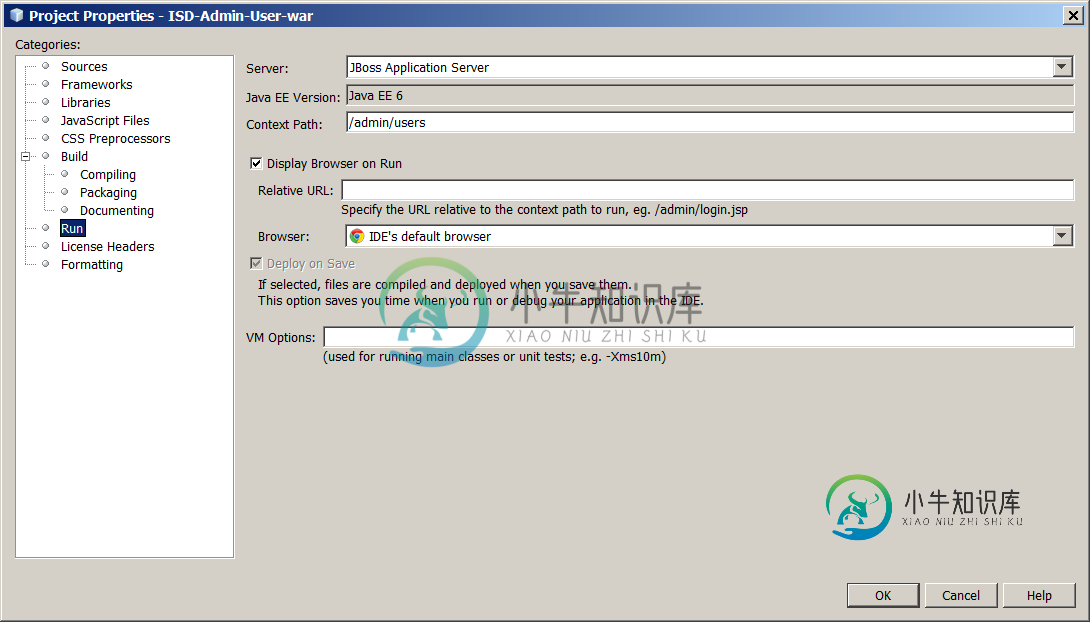 将NetBeans中的JSF页面热部署到JBoss独立
将NetBeans中的JSF页面热部署到JBoss独立以下是设置: 使用Subversion的多开发者环境 我们可能不会改变工具;我们既不能使用Maven,也不能使用JRebel。硬件升级也不在范围之内。 源代码(包括与web相关的文件)签出到: 这个目录包括一个通用的开发结构(粗体从存储库中签出): 编译文件 dist-. war文件 nbproject-项目文件 src-Java源代码 web-JSF页面,WEB-INF目录,CSS文件等 bui
-
如何为log4j设置单独的日志记录流?
说我有一堂这样的课: 现在当涉及到打印这个信息时,我想要能够打开和关闭不同类型的信息(参数、结果、花费的时间)。 使用日志级别进行区分的问题是,粒度的较细级别也包含较粗的级别。 我怎样才能轻松地设置这个?
-
测试 - 通过系统属性执行单独测试
22.13.4.通过系统属性执行单独测试 如上所述该机制已经被测试过滤取代 译者注:被取代的东西就先不翻译了 Setting a system property of taskName.single = testNamePattern will only execute tests that match the specified testNamePattern. The taskName can