《APUS-独角兽》专题
-
 带角度CLI的角度2材质
带角度CLI的角度2材质> 到目前为止,我使用角2快速入门创建了一个新项目。 我决定开始使用angular 2 cli,并创建了一个新的angular 2 cli项目。 移动了我的所有文件并重新安装了所有软件包。 现在,当我试图在CLI项目中使用角2材料时,我遵循了这里的指南,但这是我得到的: 会出什么问题?
-
独特元素数组?
问题内容: 给定下面的数组,我想知道是否有一种简单的方法可以将此数组转换为仅具有唯一值的数组? 给出: 将其变成这样的结果数组,保留原始顺序: 问题答案: 在Java 8中,用于获取数组的唯一元素 最简单的方法是从数组创建集合。 然后您可以使用以下方法检索数组: 如果要维护订单,请使用 LinkedHashSet; 如果要对订单进行排序,请使用 TreeSet 。
-
Java独立代码块
问题内容: 我从事Java已有很长时间了,但是从未遇到过这样的事情。我想知道它的作用以及为什么它不是错误。 我想知道单个块的目的是什么,其中包含对“ doSomething()”的调用。它只是一个基本代码。我遇到的实际代码位于http://www.peterfranza.com/2010/07/15/gwt- scrollpanel-for-touch-screens/ 问题答案: 这是一个(非静
-
mongoose独特:true无效
问题内容: 为什么在此脚本中猫鼬唯一不起作用 我很困惑,结果就像 谢谢您的帮助。 问题答案: 发生这种情况是因为您要在完成索引创建之前保存重复的文档。在您的应用启动后,Mongoose可以随时随地创建索引。 因此,为确保仅在创建索引后才保存文档,您必须侦听模型事件。例如: 现在,当您尝试保存第二个文档(重复的文档)时,MongoDB将引发错误,因为您的调用将在创建索引后立即运行。
-
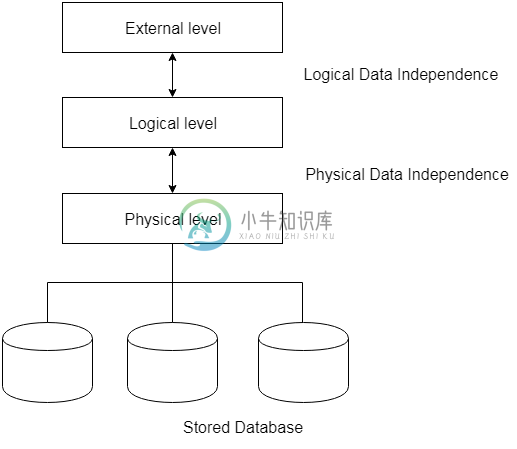 DBMS数据独立性
DBMS数据独立性主要内容:1. 逻辑数据独立性,2. 物理数据独立性可以使用三模式体系结构来解释数据独立性。 数据独立性是指能够在数据库系统的一个级别修改模式而不改变下一个更高级别的模式的特征。 有两种类型的数据独立性: 1. 逻辑数据独立性 逻辑数据独立性是指能够在不必更改外部模式的情况下更改概念模式的特征。 逻辑数据独立性用于将外部级别与概念视图分开。 如果对数据的概念视图进行任何更改,那么数据的用户视图将不会受到影响。 逻辑数据独立性发生在用户界面级别。 2
-
单独使用Django ORM
问题内容: 我想单独使用Django ORM。尽管搜索了一个小时的Google,但我仍然有几个问题: 是否需要我使用setting.py,/ myApp /目录和modules.py文件设置Python项目? 我可以创建一个新的并运行以使其自动设置表和关系,还是只能使用现有Django项目中的模型? 关于的问题似乎很多。如果你不调用现有模型,是否需要? 我想最简单的事情是让某人发布基本模板或流程的
-
MySQL独占行选择
我有一个名为“survey_product”的表,其结构如下: 此表存储通过系统订购的产品。 下面是该表中的一些数据记录: 以上我们有3个订单(订单号2、3和4)。 我需要获取product\u id=21但product\u id=20的所有订单的order\u id(订单中的其他product\u id不相关-我只对21和20感兴趣)。 然后我需要知道product\u id为20和21的订单
-
独立Kafka制作人
我正在考虑创建一个独立的Kafka生产者,它作为守护进程运行,通过套接字接收消息,并将其可靠地发送给Kafka。 但是,我决不能是第一个想到这个想法的人。这样做的目的是避免使用PHP或Node编写Kafka生成器,而只是通过套接字将消息从这些语言传递到独立的守护进程,这些语言负责传递,而主应用程序则一直在做自己的事情。 此守护进程应负责在发生中断时进行重试传递,并充当服务器上运行的所有程序的传递点
-
用Java生成数独
我在java编程方面有一些问题。这是我第一次遇到java,所以请耐心等待,因为我可能会错过绝对的基础知识。无论如何,长话短说,我有数独要做,我遇到了一些问题。我需要随机数来制作数独板,或者更确切地说是它的值。 如果您不知道数独是关于什么的,则必须只有1-9的数字,并且它们不能在行列和3x3正方形中重复。板本身是9x9,因此可以分为9个3x3正方形。 主要问题是随机生成的值有时会使模式难以解决。因此
-
Kafka独立消费者
我是Kafka的新手,我想验证我的设计。下面是我所拥有的。 我有一个生产者发布到一个主题,有一堆容器(部署我的web应用程序的地方),每个容器上都运行着一个消费者。这些消费者不在消费者组中,也不独立地消费消息。每个消费者都应该阅读主题中的所有消息。例如,假设主题m0,m1,m2上有3条消息,那么consumer1到consumerN应该独立地读取m0,m1,m2。每个使用者在处理读取的消息后立即提
-
Python数独检查器
我正在用python为我的CIS类做作业。我们得给数独棋盘编码。在9x9电路板中,我们显然必须检查每一行、col和3x3正方形是否存在重复项。我对如何用3x3的正方形来检查数字的想法有点固执。下面是我检查每一行和每一列的代码,如果有人能帮我一点轮廓或一种方法,那就是检查每一个3x3的正方形,这将是惊人的!
-
访问独占锁源
我在第一个事务中运行以下查询: 然后是第二个,来自不同的连接,这是完全相同的。在,它正在等待。 然后我运行下面的代码来查看锁 它显示行锁(ROW SHARE,ROW EXCLUSVE),这很好。但我也看到了 根据文档来自: 通过ALTERTABLE、DROP TABLE、TRUNCATE、REINDEX、CLUSTER和VACUUM FULL命令获取。这也是未显式指定模式的lock TABLE语句
-
独立运行Apache Atlas
我正在尝试在Ubuntu上以独立的方式运行Apache地图集 - 这意味着不必设置Solr和/或HBase。我所做的(根据文档:http://atlas.apache.org/0.8.1/InstallationSteps.html)是克隆Git存储库,使用mbadded的HBase和dSolr构建maven项目: 解压缩了 resuting tar.gz 文件并执行了 bin/atlas_sta
-
Single projects(独立项目)
一个项目将会自动生成测试运行。默认位置为:build/reports/androidTests 这非常类似于JUnit的报告所在位置build/reports/tests,其它的报告通常位于build/reports/< plugin >/。 这个路径也可以通过以下方式自定义: android { ... testOptions { reportDir = "$p
-
独立应用程序
现在假设我们想要使用 Spark API 写一个独立的应用程序。我们将通过使用 Scala(用 SBT),Java(用 Maven) 和 Python 写一个简单的应用程序来学习。 我们用 Scala 创建一个非常简单的 Spark 应用程序。如此简单,事实上它的名字叫 SimpleApp.scala: /* SimpleApp.scala */ import org.apache.spark.S