《APUS-独角兽》专题
-
在单独的模块中定义Mongoose模型
问题内容: 我想将Mongoose模型分离到一个单独的文件中。我试图这样做: 然后,我尝试使用如下模型: 在单独的模块中引用模型是否合理? 问题答案: 基本方法看起来很合理。 作为一种选择,您可以考虑集成模型和控制器功能的“提供商”模块。这样,您可以让app.js实例化提供程序,然后可以执行所有控制器功能。app.js只需指定要实现的具有相应控制器功能的路由即可。 为了进一步整理,您还可以考虑使用
-
 解决layui的input独占一行的问题
解决layui的input独占一行的问题本文向大家介绍解决layui的input独占一行的问题,包括了解决layui的input独占一行的问题的使用技巧和注意事项,需要的朋友参考一下 1.input标签独占一行,与button标签无法同行显示 (使用position属性进行设置,position属性详见。) 解决方法: 一.对button的position进行设置,使之与input同行。 二.将input与button放在一个大div中
-
在dag之间使用单独的environ和sys.path
问题内容: TLDR :该问题最初基于问题,后来被确定为该问题的标题更新。跳至“更新2”以获取最相关的问题详细信息。 有dag文件从另一个位置的另一个python文件中导入了dicts的python列表,并根据列表的dict值创建了dag,气流存在奇怪的问题,当我手动运行dag文件时,它看上去会有所不同。像… 从dir手动运行py文件时,没有引发任何错误,并且for循环将输出命令,但是气流显然会在
-
页面上每个Vue实例的单独Vuex
我正在页面上实例化多个Vue应用程序: 我的商店文件看起来像这样: 和地址模块: 但该存储似乎在页面上的所有Vue实例中共享。为什么,当我为每个Vue应用程序创建新实例时? 谢啦
-
Spring Cloud配置服务器独立存储库
我第一次使用Spring Cloud Config Server,并有一个基本的查询。 SpringConfigServer将配置外部化到一个单独的git存储库中。 为什么我要为配置创建一个单独的存储库? 在一个repo中使用包含所有应用程序代码和配置的mono存储库,不比只为配置创建一个单独的存储库更可取吗。 我们在同一个存储库中有多个微服务。配置服务器不应该是存在于其他应用程序代码所在的同一存
-
熊猫:在独立列中转换列的值
我有一个熊猫数据框,它看起来如下()。我希望将列的值转换为独立的列() 原始数据帧 转换数据帧 实现这一目标最方便的方法是什么?
-
使用Maven创建独立的应用程序
问题内容: 如何使用Maven创建桌面(独立/ Swing)应用程序? 我正在使用Eclipse 3.6。 问题答案: 创建一个Maven项目,如下所示: 将以下条目添加到您的pom文件中: 将项目作为Maven项目导入到Eclipse,然后作为Java应用程序运行。
-
微服务之间如何独立通讯的?
本文向大家介绍微服务之间如何独立通讯的?相关面试题,主要包含被问及微服务之间如何独立通讯的?时的应答技巧和注意事项,需要的朋友参考一下 同步通信:dobbo通过 RPC 远程过程调用、springcloud通过 REST 接口json调用 等。
-
具有独立where子句的多列-SQL Pivot?
问题内容: 是否可以采用以下方式构成的表: 最终变成这样的表: 我已经研究过使用枢轴,但无法使其正常工作。 我目前每个月都使用CROSS APPLY表值函数。 有一个更好的方法吗? 编辑:添加了现有查询-试图简化显示: 功能看起来像 问题答案: 您不需要多个子查询。答案很容易-使用集合理论。从您的第一个表ID / Month / Info1 / Info2轻松合并即可完成ID / Month +(
-
Ms Access Join表在单独的数据库中
问题内容: 我试图创建一个查询,将保留联接两个表(这些表在我的本地驱动器中的两个不同的数据库中)。到目前为止,我已经提出了这个SQL语句,但是当我运行查询时,它告诉我FROM子句中的语法有错误。 与本地表(Daily_Report)相比,查询输出一个新表(AUDIT_TABLE)并包含外部表(YTD-Daily_Report)中不存在的记录。 我从来没有在单独的数据库中查询表,所以我在这里很迷失,
-
在单独的行中打印列表列表
问题内容: 我有一个清单清单: 我想要以下格式的输出: 我已经按照以下方式尝试过,但是输出的方式不是理想的: 输出: 在更改打印调用以代替使用时: 输出: 有任何想法吗? 问题答案: 遍历原始列表中的每个子列表,并在打印调用中使用以下命令将其解压缩: 默认情况下,分隔设置为,因此无需显式提供分隔。打印: 在您的方法中,您要遍历每个子列表中的每个元素,并分别进行打印。通过使用您在打印调用中 解压缩
-
MySQL内存使用之线程独享介绍
本文向大家介绍MySQL内存使用之线程独享介绍,包括了MySQL内存使用之线程独享介绍的使用技巧和注意事项,需要的朋友参考一下 前言 在 MySQL 中,线程独享内存主要用于各客户端连接线程存储各种操作的独享数据,如线程栈信息,分组排序操作,数据读写缓冲,结果集暂存等等,而且大多数可以通过相关参数来控制内存的使用量。 线程栈信息使用内存(thread_stack) 主要用来存放每一个线程自身的标识
-
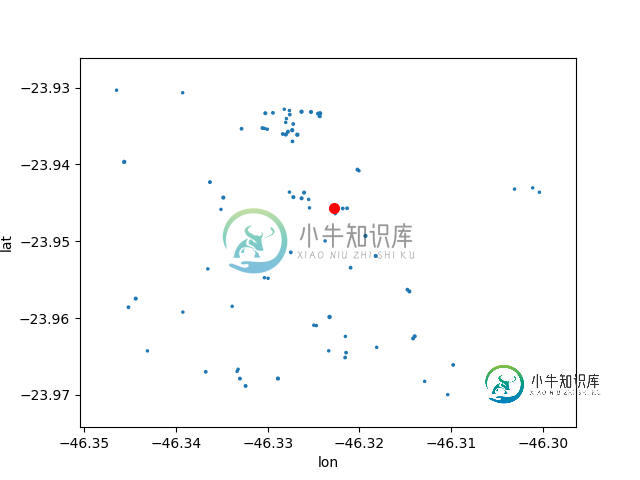 Pandas&Matplot->独立标记超出比例[副本]
Pandas&Matplot->独立标记超出比例[副本]我有一张散点图,x轴是纬度,y轴是经度。每个点代表一家餐厅。标记大小应代表该餐厅的总收入。 在一些地区这些数值相差很大,大概是100X倍,所以这些家伙(有钱的)完全“躲”住附近的小餐馆…… 所以我想到用对数刻度来刻度记号...代码如下:
-
SparkML(Scala)中的并行训练独立模型
假设我有3个简单的SparkML模型,它们将使用相同的数据帧作为输入,但彼此完全独立(在运行序列和使用的数据列中)。 我想到的第一件事是,只需使用阶段数组中的3个模型创建一个管道数组,然后运行总体拟合/变换来获得完整的预测等等。 但是,我的理解是,因为我们将这些模型作为序列堆叠在单个管道中,Spark不一定会并行运行这些模型,即使它们彼此完全独立。 也就是说,有没有办法并行拟合/转换3个独立模型?
-
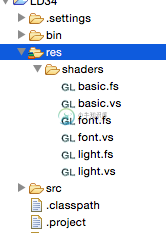 导出具有独立资源的lwjgl程序
导出具有独立资源的lwjgl程序我正在尝试将我用lwjgl制作的游戏导出到jar文件中,我使用jarsplice创建了一个胖jar。我的问题是,它总是提出一个: JAVA木卫一。FileNotFoundException:res/shaders/basic。vs(无此类文件或目录) jar文件里面有res文件夹,所以我不知道为什么它找不到它。 我正在使用eclipse供参考。