《offer比较》专题
-
Spark结构化流-比较两个流
我正在使用Kafka和Spark 2.1结构化流。我有两个json格式的数据主题,例如: 我需要比较Spark中基于标记的两个流:name,当值相等时,执行一些额外的定义/函数。 如何使用Spark结构化流来做到这一点? 谢谢
-
Jersey-client和Apache HTTP Client有何比较?
jersey-client和Apache的HttpClient之间的主要区别是什么?在哪些方面一个比另一个好?某处有好的对比图吗?哪一个在较大的文件(比如2048 MB)下性能更好? 非常感谢您的评论!
-
如何比较js中集合的值
我有一个集合,我想比较它是否包含所有的值。 这就是我想要的 我相信一定有其他方法来检查,而不是重复。
-
排序算法的比较和选择
排序算法有不少,当然,一般的语言中都提供某个排序函数,比如Python中,对list进行排序,可以使用sorted(或者list.sort()),关于这方面的使用,在我的github代码库algorithm中有几个举例,有兴趣的看官可以去那里看看(顺便告知,我在Github中的账号是qiwsir,欢迎follow me)。但是,在某些情况下,语言中提供的排序方法或许不适合,必须选择某种排序算法。
-
在 Dreamweaver 中比较文件的差别
比较本地和远程文件,在放置文件前比较文件以及在 Dreamweaver 中同步时比较文件。 比较本地和远程文件的差别 Dreamweaver 可以使用文件比较工具(也称为“diff 工具”)比较同一文件的本地和远程版本的代码、两个不同的远程文件的代码或两个不同的本地文件的代码。在本地处理某个文件并怀疑该文件在服务器上的副本已由他人进行了修改时,比较本地和远程版本十分有用。可以在将文件上传到服务器之
-
HPB 共识算法简介与比较
HPB是一套基于特定硬件设备的高性能区块链基础设施。其运行在分布式的网络上——各个节点通过P2P的邻居节点相连,各类节点之间独立维护自己各自的区块。HPB的共识算法为系统的核心,共识算法负责协调各类节点以保障整个系统的交易和智能合约的数据一致性。 HPB的算法是一种基于委托投票的POA提升算法。 Proof of Authority [1] 是运行可信区块链节点上的一种共识算法,其更轻量的消息交换
-
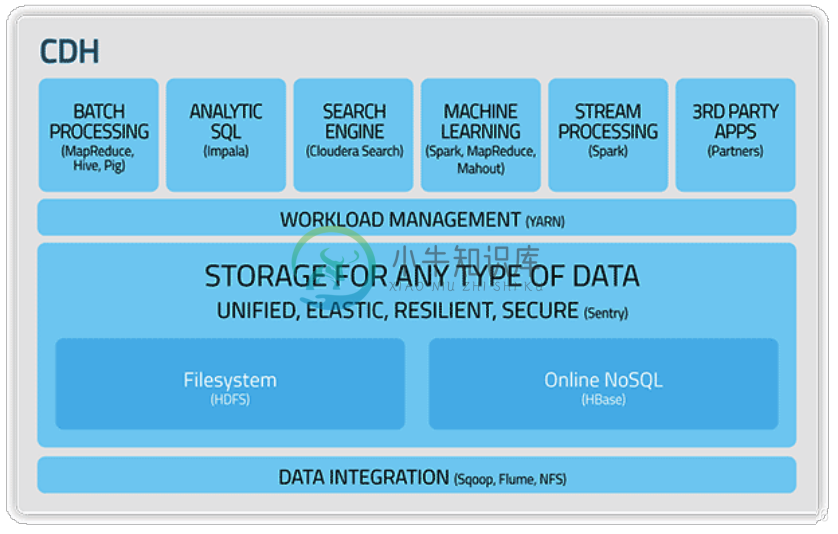 hadoop与第三方(CDH等)的比较
hadoop与第三方(CDH等)的比较主要内容:1.CDH 1、CDH简介,2.社区版与第三方发行版的比较,3.第三方发行版的比较,4.版本选择1.CDH 1、CDH简介 CDH:全称Cloudera’s Distribution Including Apache Hadoop CDH版本衍化 hadoop是一个开源项目,所以很多公司在这个基础进行商业化,Cloudera对hadoop做了相应的改变。 Cloudera公司的发行版,我们将该版本称为CDH(Cloudera Distribution Hadoop)。截至目前为止,CD
-
 多益效率还是比较高的
多益效率还是比较高的#非技术面试记录# 运营岗 12-投递 13-笔试 20-一面 23-hr面 简单分享下一面面经😊 自我介绍 选择公司看重哪些 为什么选择多益 运营有哪些能力要求 玩过什么游戏这半年 他做了什么好的运营策略和差的运营策略 如何起号 你会选择一个什么平台做宣传 对工作城市偏好 平时在学校都干什么 玩过多益的游戏吗 #本周投递记录# 面了1h,口干舌燥😂
-
git服务器用哪个比较好?
各位公司的版本管理服务器软件,用的哪个程序呢?
-
Python比Java / C#慢吗?
问题内容: Python比Java / C#慢吗? 性能比较c-java-python-ruby-jython-jruby- groovy 这是一个优化CPython的项目:空载吞咽 问题答案: 不要混淆语言和运行时。 Python(该语言)具有许多运行时实现。 CPython通常是解释型的,并且会比本机代码C#慢。取决于Java JIT编译器,它可能比Java慢。 JYthon在JVM中进行解释
-
什么比“不”更“ pythonic”
问题内容: 我已经看到了两种方式,但是哪种方式更适合Python? 哪种方法被认为是更好的Python? 问题答案: 第二个选项是Pythonic,原因有两个: 它是 一个 运算符,转换为一个字节码操作数。另一行是真的; 两个操作员。 碰巧的是,Python会 优化 后一种情况 并转换成任何情况,但这是CPython编译器的实现细节。 这接近于您在英语中使用相同逻辑的方式。
-
Redis比mongoDB快多少?
问题内容: 人们普遍认为Redis的速度非常快,而mongoDB的速度也很快。但是,我很难找到比较两者结果的实际数字。给定相似的配置,功能和操作(并可能显示因素如何随着不同的配置和操作而变化)等,Redis的速度快10倍吗?快2倍吗?快5倍吗? 我只说性能。我知道mongoDB是另一种工具,具有更丰富的功能集。这不是“ MongoDB 比Redis 更好 ”的争论。我问的是,Redis在什么方面优
-
c ++ 11 regex比python慢
问题内容: 嗨,我想了解为什么下面的代码使用正则表达式进行拆分字符串拆分 比下面的python代码慢 这是 我在osx上使用clang ++。 使用-O3进行编译可以降低到 问题答案: 我将循环数增加到1000000,以获得更好的计时措施。 这是我的Python时间: 这等效于您的代码,但更漂亮: 定时: 这是为了避免构造和分配矢量和字符串对象而进行的优化: 定时: 这几乎是100%的性能提升。
-
Elasticsearch分析百分比
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
MySQL计算百分比
问题内容: 我有4个项目MySQL数据库:(数值),和。 在我的报告中,我需要通过“调查”中的数字来计算已参加调查的“雇员”的百分比。 这是我现在的声明: 表格如下: 我想按参加调查的人数来计算谁所占的百分比。即,如以上数据所示,分别为0%和95%。 问题答案: 尝试这个 在这里演示