《用友1面》专题
-
在SELECT查询中使用TOP 1的性能影响
问题内容: 我有一个用户表,其中有一个用户名和应用程序列。用户名可以重复,但是用户名+应用程序的组合是唯一的,但是我没有在表上设置唯一约束(出于性能考虑) 问题:两者之间是否有任何区别(在性能方面): 和 - 由于用户名+应用程序的组合是唯一的,因此两个查询将始终返回不超过一条记录,因此TOP 1不会影响结果。我一直以为添加TOP 1会真正加快速度,因为sql server会停止寻找匹配的内容,但
-
控件1建议在eclipse scala ide中不起作用?
我使用的是eclipse scala ide scala ide构建的eclipse SDK构建id:3.0.4-2.11-20140520-1158-Typesafe。它似乎缺少建议功能,就像从我的测试用例中我编写PersonTest一样。斯卡拉 由于Person类最初不存在,所以我收到了编译错误。现在在java的情况下,如果我按Control 1(建议),我可以选择创建一个类,但在scala
-
Android Spring 1.0。1使用基本身份验证删除
我正在使用Android Spring 1.0。1.(此处为API文档) 我有GET和POST(添加对象)事务与基本身份验证工作,但我如何做删除? 获取和发布看起来像这样:
-
N 1使用Include和AsNoTracking时查询中的选择
我有下一个关系(只是示例)用户0/1-*故事当我想获得包含用户的故事列表时,我会进行下一个查询。 我注意到ef向db发出了额外的请求以获取用户(但这不应该是因为我使用了include)。没有AsNoTrack(),一切都很好。 看起来这是一个可为null的关系问题,因为不允许为null的关系可以很好地工作。 有人有类似的问题吗?可能是“允许空”关系的预期行为。
-
错误:任务执行失败:应用程序:mergeDebugResources'>-1.
每当我运行、制作或清理项目时, 出现此错误消息。 我已经检查了我的资源文件好几次,没有出现致命错误。只有png图标和xml文件。 我不知道“-1”是什么意思。。 在我的主java文件中,有“无法解析符号R”错误。 我的应用程序昨晚启动得很好,但当我今天早上醒来运行android studio时,它失败了。 我该怎么办? 这是我的猎物 在下面,我添加了我的全部gradle输出,谢谢。 执行任务:[:
-
React:如何使用SetState更新状态中的state.Item[1]?
我正在创建一个应用程序,用户可以在其中设计自己的表单。例如。指定字段的名称以及应包括的其他列的详细信息。 该组件在这里可以作为JSFiddle使用。 我最初的状态是这样的: 如何创建以使其更新?
-
为什么Java的字符串。getBytes()使用“ISO-8859-1”
来自java。lang.StringCodeing: 这就是从Java.lang.getBytes()中使用的,在linux jdk 7中,我一直认为UTF-8是默认字符集? 谢啦
-
使用Python在1页上发布2个表单(Webscraping)
我试图建立一个网络刮板为我的客户端,将得到当前的价格,如www.wozwaardeloket.nl.在第一部分,我张贴接受数据表单,使网页接受'cookie警报'。 在第二个请求中,我想将“Streetname Number City”的值发布到同一页面的第二个帖子。我对Python有点缺乏经验,所以也许有人可以告诉我我做错了什么? 导入请求 url='https://www.wozwaardel
-
使用java中的10个线程打印1到100
我是多线程的新手,我有一个问题,要在Java中使用10个线程打印1到100,并使用以下约束。 > 线程 应打印: 1, 11, 21, 31, ...91 < code>t2应打印: 2, 12, 22, 32, ... 92 同样地 < code>t10应打印: 10, 20, 30, ... 100 最终输出应为: 1 2 3 ..100 我已经尝试过了,但它在所有10个线程中都抛出了以下异常
-
HikariPool-1-连接不可用,请求在30000ms后超时
我在SpringBoot 2.0中使用标准的HikariCP实现。1份申请书。但是过了一会儿,我一遍又一遍地犯同样的错误 HikariPool-1-连接不可用,请求在30000ms后超时 我首先检查了代码,如果有任何未关闭的连接或丢失的事务注释,但我没有找到任何东西。我也试图增加游泳池,减少我application.yml的时间,但这似乎没有任何效果。 奇怪的是,HikariCP似乎只创建了4个池
-
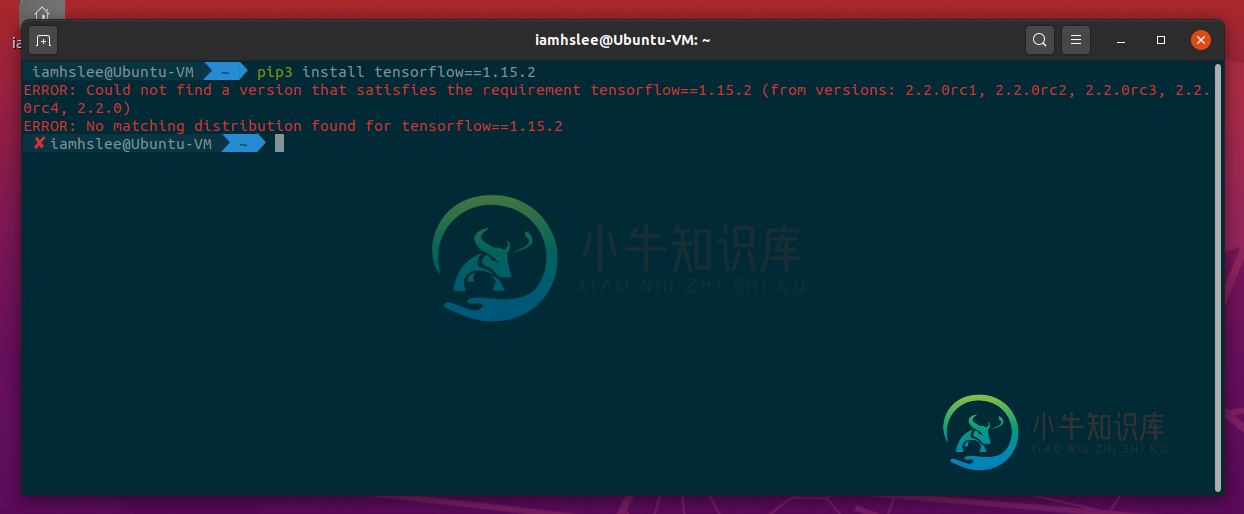 无法安装Tensorflow 1。Ubuntu20.04 LTS上的x使用pip
无法安装Tensorflow 1。Ubuntu20.04 LTS上的x使用pip我有理由使用Tensorflow 1。x版本,但返回错误消息: 我也尝试了. whl安装,但是最新的Tensorflow 1.15.2支持cp37,我不能再使用它了。 是张量流1。pip或pypi不再支持x?或者我应该降级python(3.8) 【系统环境】Ubuntu 20.04 LTS Python版本:3.8.2 pip版本:20.0.2 谢谢
-
将JSF 1.2 Seam应用程序迁移到WildFly Beta 1
一个Seam war应用程序(JSF1.2),以前迁移到JBoss7.1并运行良好,现在需要迁移到Wildfly Beta1。 默认情况下Wildfly不支持JSF1.2,因此遵循以下说明启用它: 项目建设得很好,野蝇启动得也很好。当我尝试打开一个页面时,它会抛出异常: 根据这个链接,javax.faces.context.facescontext.getAttributes()的返回类型参数发生
-
如何使用Docker公开1个以上的端口?
所以我有3个端口应该暴露在机器的接口上。有可能用Docker容器做到这一点吗?
-
队列使用2个堆栈,在O(1)中删除
我在Java中使用2个堆栈实现了一个队列,我遵循以下算法: 排队(x) 将x推到堆栈1 deQueue() 1)如果两个堆栈都为空,则返回错误 2)如果stack2为空,而stack1不为空,则将所有内容从stack1推到stack2 3)从stack2弹出元素并返回它。 现在,这里的问题是第一个操作非常慢(因为它将所有内容传输到)。我们可以修改算法,使总是O(1)吗?还有其他选择吗?
-
使用聚合时,子查询返回超过1行
子查询返回超过1行?? 下表是我想要达到的目标 这就是为什么我认为我需要使用group by来区分user_id 我已经看过了 子查询返回超过1行-MySQL 子查询返回的行数是否超过1行? 但还是不明白。 通过连接两个不同的表,我得到了下表。 谁能帮我解决这个问题?