《泡池子》专题
-
如何解决:使用池时出现“找不到适用于jdbc:mysql:// localhost / dbname的驱动程序”错误?[重复]
问题内容: 这个问题已经在这里有了答案 : 臭名昭著的java.sql.SQLException:未找到合适的驱动程序 (13个答案) 3年前关闭。 我试图建立与数据库的连接,当我使用main方法测试代码时,它可以无缝运行。但是,当尝试通过Tomcat 7访问它时,它失败并显示以下错误: 我正在使用池。我将WEB-INF / lib和.classpath中的mysql连接器(5.1.15),dbc
-
Docker“错误:在分配给网络的默认值中找不到可用的,不重叠的IPv4地址池”
问题内容: 我有一个具有以下结构的目录: 我正在尝试运行以下命令: 其中,用于为 那是 其中由两个线 而对于IS 其中包含单行。最后,该程序旨在简单地测试使用Tor更改IP地址是否有效: 在成功建立,但如果我尝试,我得到以下错误信息: 我尝试搜索有关此错误消息的帮助,但找不到任何帮助。是什么导致此错误? 问题答案: 遵循彼得·豪格)的评论,在跑步时,我发现(其中包括)以下内容: 和两者的界线似乎就
-
Java调度线程池执行器对某些条件进行初始延迟对某些值进行检查
问题: 我有一个任务,它必须在每个任务运行后以固定的延迟定期运行。另外,我有一个条件,在初始延迟或第一次执行应该发生在一个条件满足后。因此,执行器必须阻止调度任务,直到满足条件为止。 Java并发包为我们提供了ScheduledThreadPoolExecutor,它具有初始延迟的选项。但在我的例子中,初始延迟是在某个条件或值改变为所需的条件或值之后。 我如何实现这个行为以及我应该使用什么exec
-
Docker“错误:在分配给网络的默认值中找不到可用的、不重叠的IPv4地址池”
我有一个目录,其结构如下: 我试图搜索有关此错误消息的帮助,但找不到任何帮助。是什么导致了这个错误?
-
为什么使用 python 的进程池处理并发的 TCP 请求,会导致客户端并发卡住?
服务端代码: 服务端使用进程池并发处理来自客户端的 TCP 请求 客户端代码: 因为我的客户端使用线程池并发,只要 max_workers 大于 1 就会一直卡死 测试平台是 macos 13.3.1 (22E261) + python3.10.10,会卡死 但是我在 ubuntu20.04 + python3.11.3 上就是一切正常,不会出现卡死的问题 但是 max_workers 是 1 就
-
在glass乐于服务器管理控制台中为postgreql供应商创建连接池时连接被拒绝
我正在尝试在Glass乐于服务器中创建一个到PostgreSQL数据库的连接池。我所做的步骤如下: > 我将postgresql-jdb-jar的jar复制到完整路径 我已经在glassfish服务器管理控制台中指定了jar的完整路径: 池名称:post-gre-sql_CommonPush_postgresPool 资源类型:javax.sql.XADataSource data source
-
我可以为长时间运行但不频繁的任务使用单独的非连接池数据源吗?
我的应用程序栈由Spring MVC、Hibernate和Apache Tomcat7上的MySQL组成。 这个用例不会经常启动,所以我可能会使用单独的数据源定义而不使用连接池。当然,我可以在Spring中设置两个具有不同名称“abc”和“xyz”的事务管理器,并使用@transactional(name=“abc”)和@transactional(name=“xyz)”。这两个事务管理器都将使用
-
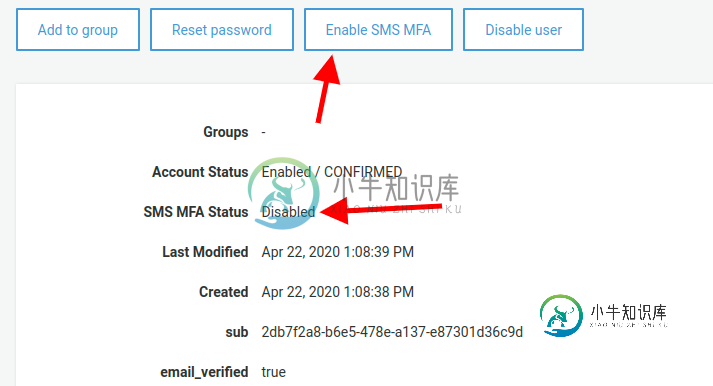 如何在Java中以编程方式为AWS认知用户池中的日志用户启用或禁用MFA?
如何在Java中以编程方式为AWS认知用户池中的日志用户启用或禁用MFA?我正在使用下面的代码,但它没有更改AWS中的任何内容,尽管它没有返回文档中所述的任何内容。https://docs.aws.amazon.com/cognito-user-identity-pools/latest/apireference/api_adminsetusermfapreference.html 更新:实际上,这段代码更改了SMS MFA状态,但是在Cognito用户池的UI中看不到
-
不能从Glassfish池连接到外部Oracle数据库,但我可以从DBeaver连接到外部Oracle数据库
首先,如果我说错了话,我很抱歉,英语不是我的第一语言。此外,出于安全(和NDA)原因,我正在更改真实名称 下面是我如何配置Glassfish池的: 数据源和驱动程序 URL、DBUSER和DBPASSWORD 使用“auser”和“apass123”代替auser和apass123 用\(\auser和\apass)转义第一个字符 下载了OJDBC6.jar的上一个版本 我不是外部数据库的管理员,
-
线性编程:在PYTHON中使用DocPlex生成的所有解决方案列表(cplex解决方案池失败)?
在解决问题的过程中,我实际上面临着一个问题。我的问题是一个线性规划问题,具有食物饮食优化和成本最小化。因为这个问题和这个类似(https://ibmdecisionoptimization.github.io/docplex-doc/mp/diet.html),我已经在Python中安装了docplex来解决这个问题,它可以正常工作!问题是我需要获得所有可行的解决方案并将其输出。但是IBM的例子只
-
使用“”运算符的非字符串操作数后,生成的字符串是否会进入字符串池?
我正在学习和准备OCP 1Z0-815,我从这本优秀的准备书中读到: Deshmukh,Hanumant。OCP Oracle认证专业JavaSE 11程序员I考试基础1Z0-815:通过OCPJava11开发者认证第1部分考试1Z0-815的学习指南(p.99)。Enthuware.电子书做Kindle。 上面创建了一个字符串对象,在循环的开始处包含“hello”,然后在每次迭代中再创建两个,一
-
在Azure Batch中使用托管标识在批处理池中使用Python对密钥库进行身份验证
对于较新的azure keyvault包,我使用了以下内容: 但是它找不到。这是错误的一部分:
-
是否有带有多个队列的开箱即用的线程池(可确保每个队列的串行处理)?
问题内容: 在所有任务中,我有一些必须按顺序处理(它们永远不能同时运行,必须按顺序处理)。 我实现了为必须串行执行的每组任务创建一个具有单个线程的独立线程池的功能。它有效,但我没有足够的资源。我无法控制组的数量,因此最终可能会产生大量同时运行的线程。 有什么办法可以通过单个线程池完成此任务?是否有一个带有多个阻塞队列的线程池,我可以确保每个队列的串行执行? 编辑: 只是强调我在第二段中所说的:我已
-
当我们使用new运算符时,确切地说什么时候在字符串常量池中创建对象。?
这里将创建两个对象,一个在堆内存中,另一个在字符串池中。 那么,方法有什么用呢?执行上述语句后,字符串将在堆和字符串池中可用
-
Python多进程池。当工作进程之一确定不再需要执行更多工作时,如何退出脚本?
问题内容: 因此,我有一组工作人员在做一些工作。它只需要找到一个解决方案。因此,当一个工作进程找到解决方案时,我想停止一切。 我想到的一种方法是只调用sys.exit()。但是,由于其他进程正在运行,因此似乎无法正常工作。 另一种方法是检查每个进程调用的返回值(part_crack_helper函数的返回值),然后在该进程上终止调用。但是,我不知道在使用该map函数时该怎么做。 我应该如何实现?