《泡池子》专题
-
Google Cloud Bigtable客户端连接池
我对Google Cloud Bigtable做了一个负载测试,制作了一个虚拟的web应用程序,用于处理向Bigtable写入数据和从Bigtable读取数据的请求。一开始,我只使用一个Bigtable连接作为单例,并跨所有线程(请求)重用它。当我增加请求数量时,我注意到性能正在变慢。不知何故,我没有增加节点的数量,而是想到了创建多个Bigtable连接,然后将它们随机分配给任何线程,从而提高了性
-
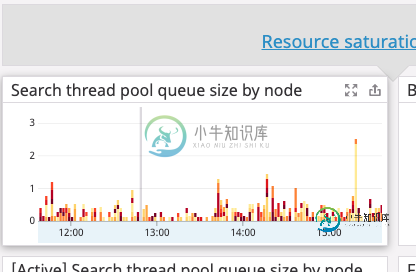 了解elasticsearch的搜索线程池
了解elasticsearch的搜索线程池我使用Datadog与elasticsearch的集成来监控ES集群,它在仪表板上显示的一个重要指标是活动和等待搜索线程的数量。参考这个ES文档,我知道搜索线程在ES中的一个请求队列上工作,该队列的固定大小为1000。 如图所示,我看到很多等待线程,但这里没有解释拒绝队列异常。所以这意味着ES没有拒绝请求,但搜索线程仍然无法足够快地执行请求,因此最终处于等待状态很长一段时间。 问题 搜索请求队列的
-
malloc或无对齐的内存池
我正在做C代码,我有几个(数百万)malloc,每个请求20-30字节的内存。 因此,GNU C Malloc和Jemalloc的开销都达到了40-50%。DL-Malloc工作得更好,但仍有约30%的开销。 有没有一种方法可以在没有任何对齐/填充的情况下执行malloc?我知道这会很慢,而且可能在某些CPU上需要从不同的单词“重建”数据,但我准备以速度换取内存使用量。 我也可以使用内存池来代替m
-
JavaServlet中的数据库连接池
我正在为员工管理系统创建一个web应用程序,使用ApacheTomcat作为HTTP服务器,Oracle作为数据库,applet用于客户端编程,servlet用于服务器端编程。我还想使用DBCP来管理与数据库的连接。 我希望执行查询的servlet使用客户端为连接输入的用户名和密码。但是到目前为止,我看到在中配置资源时必须设置连接池的用户名和密码。 有没有什么方法可以实现这一点并且仍然使用DBCP
-
自定义线程池执行器
我正在编写一个定制的ThreadPoolExecutor,具有以下额外功能:- > 如果有理想的线程,并且随着任务的到来,将该任务分配到队列中,而不是将其添加到队列中。 如果所有线程(最大池大小)都忙,则在新任务到来时,使用RejectionHandler的reject方法将它们添加到队列中 我已经重写了线程池执行程序的java 1.5版本的执行方法。 新守则如下:- 遗留代码如下所示:- 现在正
-
node.js mysql2连接池执行问题
我还是nodejs的新手,有些东西不能理解。我有带有代码的db.js文件: 当我尝试这样插入行时: 它会失败,并出现sql语法错误。为什么它失败了,它工作得很好,只是使用了稍微不同的db.js。我在这里寻找简短而正确的解决方案。
-
连接池、jdbc和jndi的区别
我需要知道我对上面的理解是否正确。 在连接池中,可以使用java.sql.DataSource设置多个连接。 在jdbc中,我们直接指定连接url和oracle.jdbc.driver.OracleDriver并且它总是一个连接,另一个请求必须等待到连接完成处理。 使用JNDI与直接jdbc类似,我们通过名称引用jdbc设置,这样我们就可以在应用服务器中指定连接url和其他设置,而不是将它们绑定到
-
Tomcat Jdbc连接池活动连接
我们有一个spring-boot应用程序,它使用嵌入式tomcat进行部署,并使用MySQL后端的默认tomcat-jdbc连接池,而没有为MySQL或tomcat端定制。 该应用程序有一些调度程序,它们主要在一天中的特定时间运行,即在昨天的最后一次cron运行和今天的第一次cron运行之间,有超过9个小时的间隙。然而,无论何时cron在早期运行,它都从未遇到过空闲连接问题。 现在我们看到一条错误
-
无法从池JedisConnectionException获取资源
大家好,我正在尝试使用Java建立redis服务器。我的Redis服务器是linux服务器,ulimit无限。 这里是创建连接的spring bean 公共类JedisService实现IJedisService,InitializingBean,DisposableBean{private JedisPool JedisPool;
-
cassandra连接池中的HostDistance概念
我不明白,HostDistance概念意味着它有本地或远程价值。需要在使用java API创建连接(即池选项中的core/max)时进行设置。 问题是 我们是否需要为集群中的每个节点设置主机距离值?如果是怎样? 或者 我读了这些链接 https://docs.datastax.com/en/drivers/java/2.0/com/datastax/driver/core/policies/Loa
-
Azure弹性池的替代方案
我正在设计多租户SaaS解决方案。我读过多租户SaaS数据库租赁模式的文章,对我来说,每个租户都有数据库的多租户应用似乎是最好的选择。它看起来非常有吸引力,因为它为所有现有数据库提供了数据库管理工具。可以一次更新所有租户的数据库模式。但这是唯一的选择吗?我没有找到任何AWS或谷歌云替代弹性池。有吗? 也许有更好的解决方案为每个租户提供单独的数据库?例如,使用docker/kubernates。 谢
-
python多处理池。地图挂起
我甚至不能使用Python 2.7中运行的多重处理包(使用spyder作为窗口上的用户界面)进行并行处理的最简单的例子,我需要帮助解决这个问题。我已经运行了conda更新,所以所有的包都应该是最新的和兼容的。 即使多处理软件包文档(如下所示)中的第一个示例也不起作用,它会生成4个新进程,但控制台只是挂起。在过去的3天里,我已经尝试了我能找到的一切,但是没有一个不挂起就运行的代码能够将我25%以上的
-
Java线程池执行器监视
Java SE6文档中的ThreadPoolExecutor类具有以下方法: 返回正在积极执行任务的线程的大致数目。 这里近似和积极执行是什么意思? 在调用之前、期间和之后,是否保证 null 我已经研究了线程池执行器监视需求,以及如何在java中判断线程池中是否有可用的线程,但它们没有回答我的查询。
-
spring boot activemq使用者连接池
是否需要Spring Boot ActiveMQ使用者连接池来配置?我在spring boot应用程序中只有一个消费者(作为一个微服务),生产者在另一个应用程序中。我对以下内容并不感到困惑:(摘自http://activemq.apache.org/spring-support.html) 注意:虽然PooledConnectionFactory确实允许创建活动使用者的集合,但它并不“聚集”使用者
-
Cassandra Datastax驱动程序-连接池
我试图理解Datastax Cassandra驱动程序中的连池,因此我可以更好地在我的Web服务中使用它。 我有留档的1.0版。它说: Java驱动程序异步使用连接,因此可以在同一个连接上同时提交多个请求。 他们通过连接理解什么?当连接到集群时,我们有:一个生成器、一个集群和一个会话。他们中的哪一个是连接? 例如,有一个参数: MaxSimultaneousRecestsPerConnection